Masarykova univerzita byla první vysokou školou v České republice, která vytáhla do boje s plagiátory pomocí vlastního software na kontrolu textových podobností. Od roku 2006 kontroluje závěrečné a jiné práce přímo v Informačním systému MU (IS MU) díky vyvinutému algoritmu na odhalování plagiátů. O dva roky později se spojilo několik veřejných vysokých škol a MU vyvinula meziuniverzitní systémy, které tyto školy začaly od roku 2008 využívat. Postupně se prostřednictvím těchto systémů zapojily i další vysoké, vyšší odborné a střední školy. Jedná se o Theses.cz na odhalování plagiátů ve vysokoškolských a absolventských pracích, Odevzdej.cz na kontrolu seminárních, školních a jiných prací a Repozitar.cz pro kontrolu vědeckých publikací. Systémy využívá už více než 80 škol a institucí, mezi něž patří i dvě ministerstva, a výrazně se tak rozšířila i databáze prohledávaných souborů, která čítá více než 50 miliónů položek.
Způsob opisování se od dob spuštění systémů na odhalování plagiátů proměňuje. Studenti už nyní s kontrolou své práce v některém ze systémů počítají a často si práce před odevzdáním sami kontrolují v systému Odevzdej.cz, nedovolí si tak již odevzdat cizí práci nebo doslovně opsat pasáže z odborných publikací. Nově se proto opisování častěji projeví detailním přeformulováním textů, které je stále použitím cizích myšlenek, a tedy plagiátem. Vývojový tým IS MU proto vyvinul nový algoritmus vyhledávání podobností, který lépe odhalí i parafrázované texty a navíc poskytne nové funkce, modernější design a přehlednější způsob zobrazení nalezených podobností.
Obr. 1: Nová verze vyhledávání podobností
Nový algoritmus se soustřeďuje na parafrázované, tedy přeformulované, texty. Algoritmus se nesnaží vyhodnotit velmi krátké společné pasáže textu. Podle našich zkušeností takovéto pasáže bývají obvykle věci jako standardní definice, víceslovné ustálené odborné termíny, citace zákonů a podobně, jejichž přítomnost ještě neznamená, že jde o plagiát. Další jeho vlastností je, že při zobrazení výsledků "přeskakuje" ty z nalezených zdrojů, které z hlediska podobností nepředstavují oproti již zobrazeným žádnou přidanou hodnotu a v seznamu relevantních zdrojových dokumentů by jednou vyznačené podobnosti již jen duplikovaly. I tyto přeskočené zdroje si však lze zobrazit a podrobit kontrole. Nový systém také vyhodnocuje jinak procento podobnosti mezi dokumenty. Může být vyšší, anebo naopak i nižší. Rozhodně se však nedoporučuje, aby se uživatelé tímto procentem řídili. Je to jen číslo a i nález 1 % může znamenat závažné porušení. Opačně ani vysoké procento podobnosti nemusí být známkou plagiátorství.
Nalezené podobnosti se nově zobrazují ihned po kliknutí na Žárovku pod ikonou Vejce vejci (Vyzkoušejte novou verzi). Spočítání podobností probíhá výrazně rychleji než dříve, neboť podobnosti jsou dostupné ihned po vytvoření textové verze souboru. Automaticky jsou ignorovány dokumenty stejného vkladatele (lze ale zvolit i jejich zahrnutí).
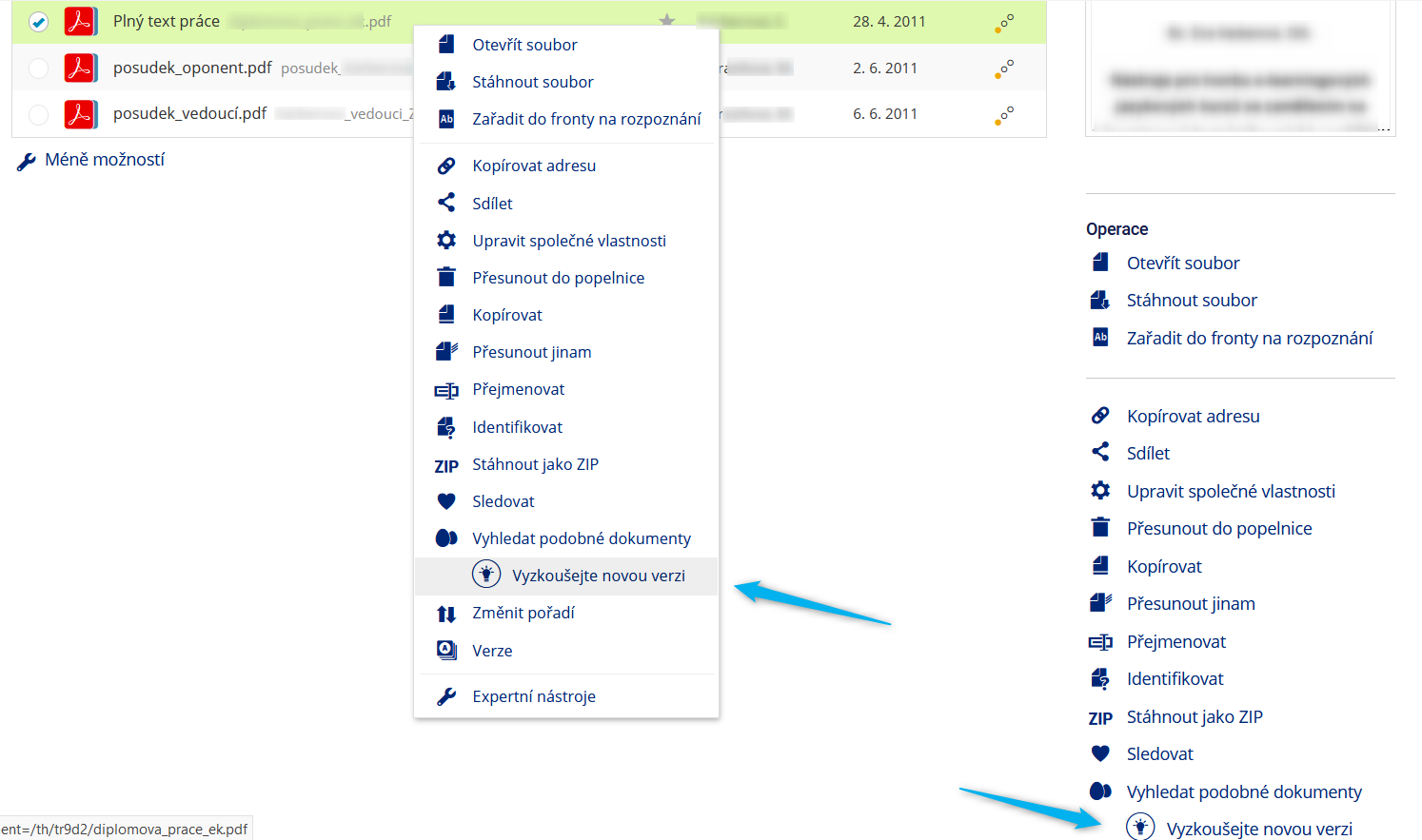
Obr. 2: Odkaz na novou verzi
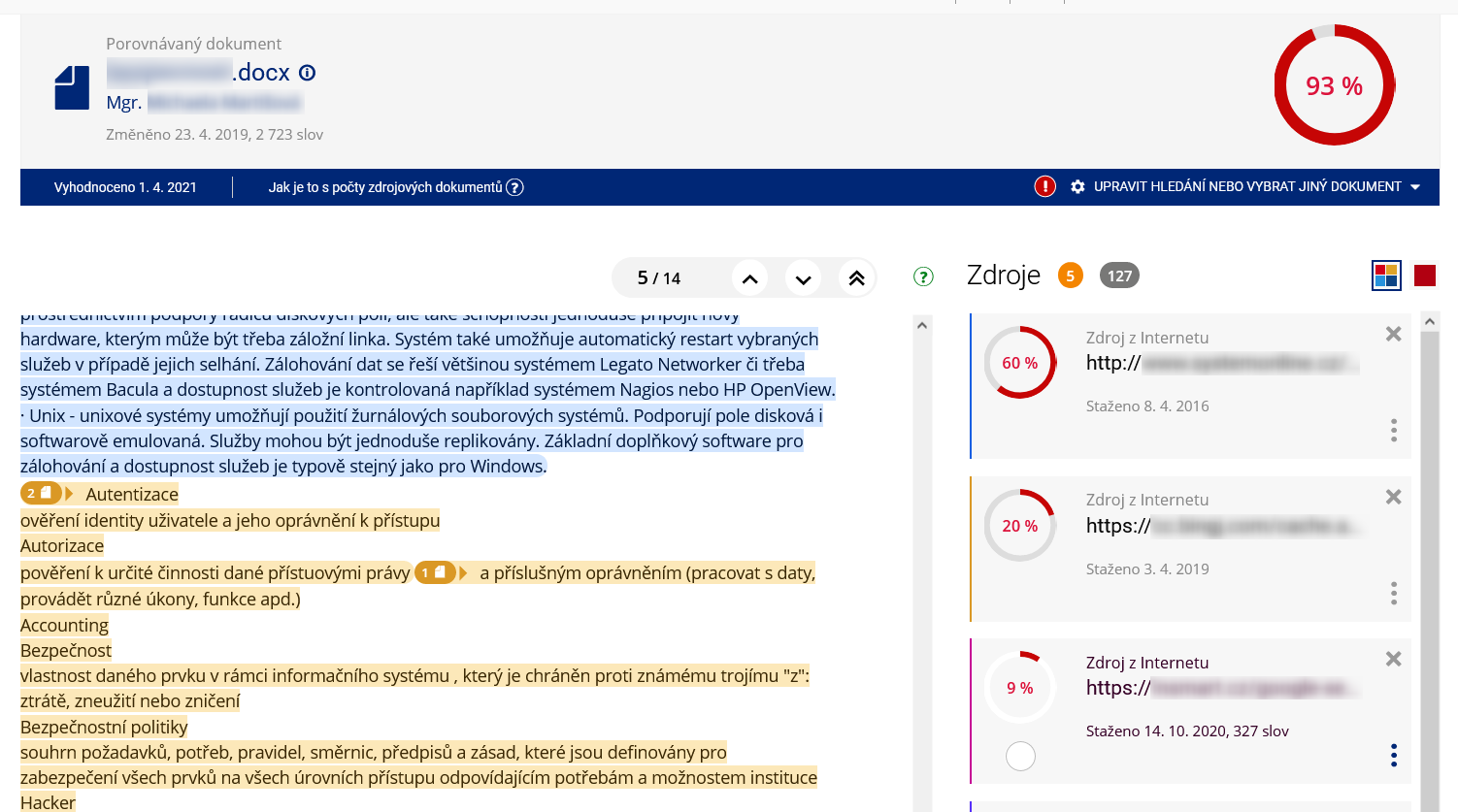
Podobnosti z jednotlivých zdrojových dokumentů jsou nově vyznačeny různými barvami, ne pouze červeným písmem. Ikonka na začátku barevně zvýrazněného textu ukazuje, kolik zdrojů je s tímto textem podobných, a po rozkliknutí je možné vidět, které zdroje to konkrétně jsou. Kliknutím na vybraný zdroj dojde ke zvýraznění podobností právě s tímto zdrojem. Přehled nalezených zdrojových dokumentů se zobrazuje také v pravé boční liště, kde pod ikonkou tří teček nalezne uživatel více informací o vybraném zdroji.
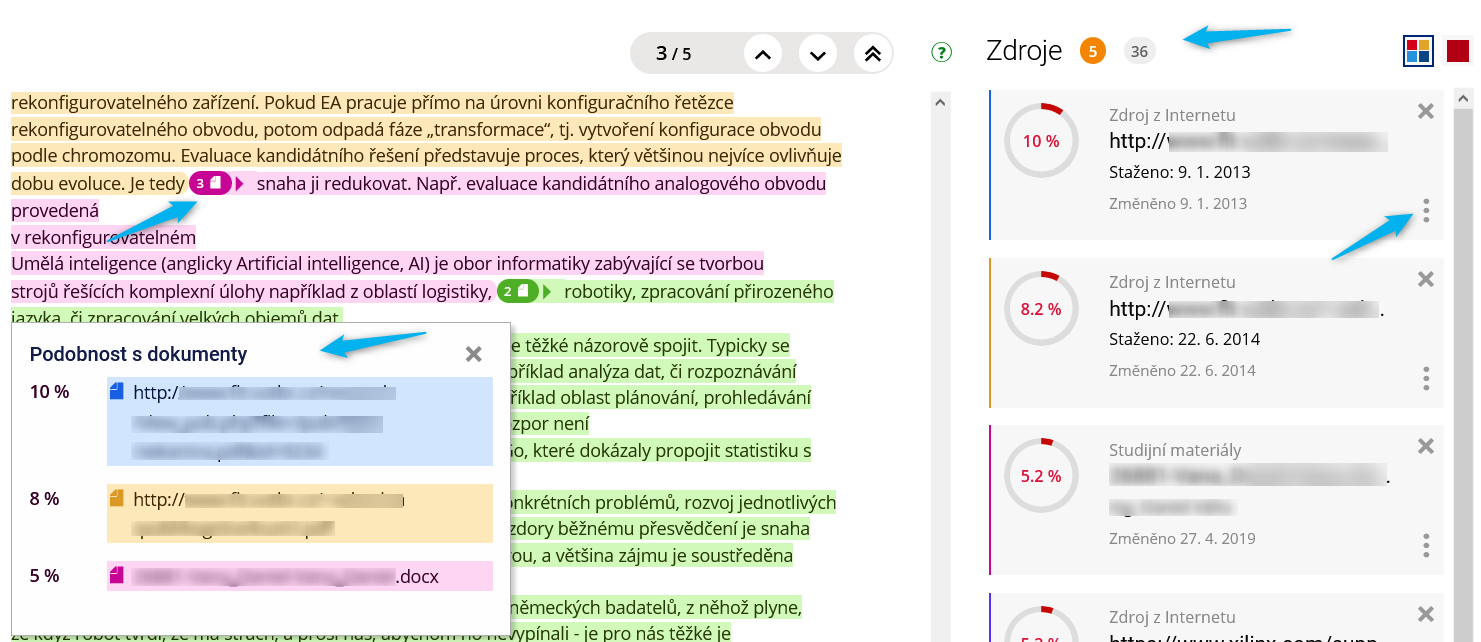
Obr. 3: Zobrazení nalezených podobností
Aby nebyl uživatel zahlcen množstvím zdrojů, které se s porovnávaným dokumentem překrývají ve stejných pasážích s dříve nalezenými dokumenty, jsou tyto tzv. přeskakovány. Pro lepší přehlednost začíná algoritmus přeskakovat dokumenty, pokud počet těchto zdrojů přesáhne desítku. Počet takto přeskočených dokumentů je zobrazen v šedém oválu v pravém panelu s přehledem zdrojů. Po rozkliknutí tohoto čísla si lze dokumenty prohlédnout a zobrazit k nim podobnosti.
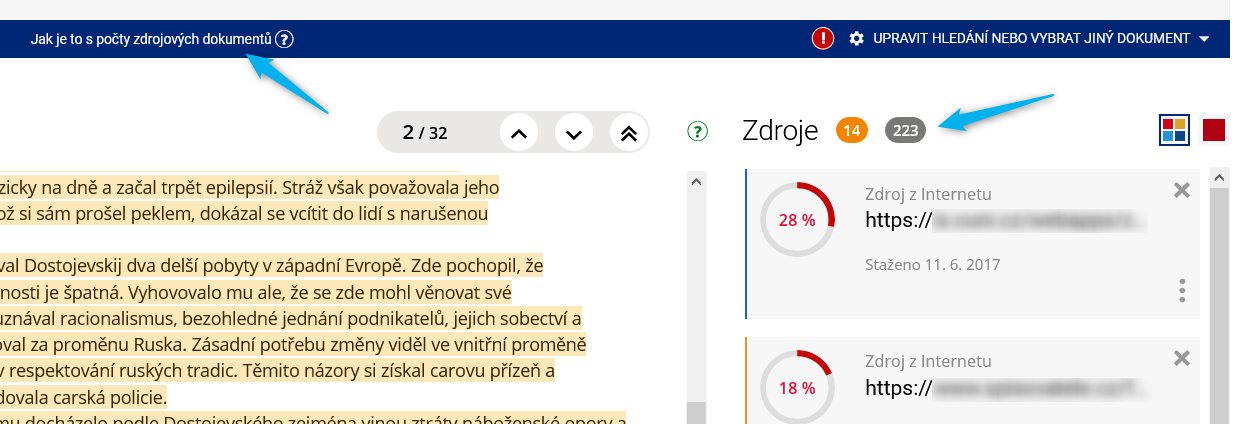
Obr. 4: Počet "přeskočených" dokumentů
Nový algoritmus a funkce by mohly vyučujícím a dalším pověřeným osobám, jež práce kontrolují, napovědět, které práce vyvolávají určité podezření. Procento nalezených podobností ale neurčuje, zda je práce plagiátem či nikoliv, každou práci je nutné posoudit individuálně, zkontrolovat správnost citací vždy člověkem, a to odborným pracovníkem v oboru.
Další informace o systému naleznete v Nápovědě a v Průvodci, který je odkazovaný přímo z této aplikace.
V současné době nabízíme uživatelům nejen výsledky nového algoritmu, ale po dobu ověřovacího provozu ponecháváme dočasně i možnost použití původního systému.
Nový algoritmus vyhodnocuje podobné pasáže textu jiným způsobem než původní algoritmus. Je tedy očekávané, že se budou odlišovat jak hranice podobných pasáží, výše zmíněné krátké podobnosti, tak i celková procenta podobnosti dokumentů. V případě že systém vrací jiná data, než byste očekávali, obraťte se jako obvykle s dotazem na adresu theses@fi.muni.cz a popisem toho, jaký dokument porovnáváte, co očekáváte za výsledky, a kde se vaše očekávání liší od toho, co systém vrací.
Věříme, že nový algoritmus pomůže školitelům a dalším uživatelům lépe dohledávat možné zdroje plagiátorství.
