29. 4.
2009
Dosud nehodnoceno.
V nedávné době byla v Informačním systému Masarykovy univerzity (IS MU) rozšířena služba na
rozpoznávání naskenovaných dokumentů (o této službě více v novince Rozpoznávání naskenovaných dokumentů integrováno do IS MU). Nyní je možné rozpoznávat nejen soubory ve formátu PDF, ale také obrázky
např. ve formátu BMP, JPG, PNG, GIF, TIF. Rozpoznáváním pomocí OCR metody (OCR - Optical Character Recognition - optické rozpoznávání znaků) se z
naskenovaného dokumentu získá text, který lze zkopírovat např. do Wordu či jiné podobné aplikace a ten následně dále upravovat, lze v něm
vyhledávat, označit jej myší apod.
Výstupem jednak může být textový dokument TXT, případně soubor DOC programu Word, nebo nakonec
dvouvrstvé PDF, které obsahuje jak rozpoznaný text, tak i nerozpoznaný originál.
Chce-li uživatel rozpoznat soubor v ISu, zařadí si soubor do fronty na rozpoznávání tak, že u daného typu
souboru (obrázek či PDF) rozklikne montážní klíček  a ve vlastnostech souboru klikne na "Zařadit do
fronty na rozpoznání".
a ve vlastnostech souboru klikne na "Zařadit do
fronty na rozpoznání".
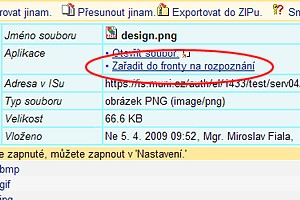
Obr. 1: Zařadit do fronty na rozpoznání.
Druhou z možností, jak nechat soubor rozpoznat, je po přihlášení do IS MU použít
(kliknout) na "rozpoznávání (OCR)" na konci hlavní stránky.

Obr. 2: Vyhledání požadovaného dokumentu pro rozpoznání.
Obr. 3: Bohatý výběr jazyků.
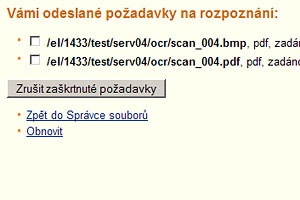
Obr. 4: Soubory připravené k rozpoznání.
Jazyková podpora rozpoznávání v Informačním systému Masarykovy univerzity je široká. Systém
nyní obsahuje 31 jazyků, mezi něž mj. patří čeština, angličtina, němčina, slovenština, ale i
méně obvyklé jazyky, kterými jsou bulharština, estonština, finština, litevština, rumunština, švédština,
turečtina a mnoho dalších. Systém je schopen rozpoznávat v jakékoliv agendě IS MU, tj.
ve Studijních materiálech, Poskytovnách, Dokumentovém serveru, Úschovnách, Mém webu, Závěrečných
pracích či v Přijímárně. Velkou výhodou je, že uživatel nemusí mít na svém počítači
nainstalováno žádné speciální programové vybavení pro rozpoznání, o vše se nyní postará sám Informační
systém Masarykovy univerzity.
Vzhledem k tomu, že se žádosti o rozpoznání řadí do fronty chronologicky podle času přidání souboru, a není tedy dopředu jisté, za jak dlouho bude rozpoznání hotové. Proto
je uživatel o dokončení rozpoznávání informován automaticky generovaným e-mailem a nemusí tak sám průběžně kontrolovat, v jaké fázi rozpoznávání jeho
souborů se nachází.
29. dubna 2009
