(\#fig:unnamed-chunk-3)Vizualizace dat s *ggplot2*
(\#fig:unnamed-chunk-3)Vizualizace dat s *ggplot2*
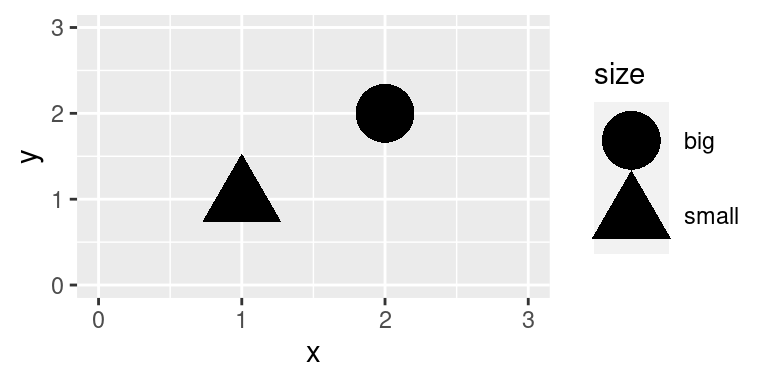
(\#fig:unnamed-chunk-4)Prvky umožňující převod vizualizace zpět do dat
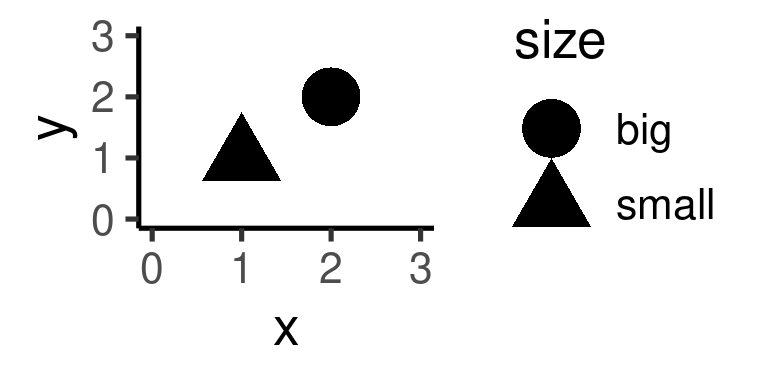
(\#fig:unnamed-chunk-5)Změny vzhledu obrázků
 Výsledkem je prázdná formátované plocha. Volání `ggplot()` totiž pouze vytvoří prázdné "plátno", na které je potřeba přidávat jednotlivé vrstvy s obsahem.
Nové vrstvy se typicky přidávají voláním funkcí `geom_*()`. Tyto funkce nejsou nic jiného, než aliasy pro různé nastavení funkce `layer()`:
```r
layer(geom = NULL, stat = NULL, data = NULL, mapping = NULL,
position = NULL, params = list(), inherit.aes = TRUE,
check.aes = TRUE, check.param = TRUE, subset = NULL, show.legend = NA)
```
Funkce `layer()` má mnoho parametrů. Zásadní jsou tyto:
- `data`...tabulka s daty, která se má použít v dané vrstvě. Pokud tento parametr není zadán, potom se použije tabulka dat specifikované ve volání `ggpplot()`. Každá vrstva tak může pracovat s jinými daty. (A také `ggplot()` nemusí obsahovat specifikaci dat.)
- `geom`...typ geometrického objektu, který se má použít pro vizualizaci dat. Může se jednat o bod (`point`), polygon (`polygon`), úsečku (`line`) a mnoho dalších.
- `mapping`...obsahuje namapování proměnných na estetiky pomocí funkce `aes()`. Pokud není parametr specifikován, potom se použije specifikace z `ggplot()`. Pokud je specifikace v konfliktu se specifikací v `ggplot()`, potom se použije specifikace z `layer()`. Pokud je specifikována estetika, která není přiřazena v `ggplot()`, potom se použije jako doplnění ke specifikaci z `ggplot()`.
- `stat`...statistická transformace dat, která se má provést před vykreslením. Vykreslují se až transformované data.
- `position`...umožňuje upravit pozici hrubých dat před jejich vykreslením
Funkce `layer()` není zpravidla nikdy volána přímo. V podstatě vždy se používají funkce `geom_*()`. Pokud například chceme přidat vrstvu s bodovým grafem, potom použijeme `geom_point()`. Tato funkce je přesným ekvivalentem volání:
```r
layer(
data = NULL,
mapping = NULL,
geom = "point",
stat = "identity",
position = "identity"
)
```
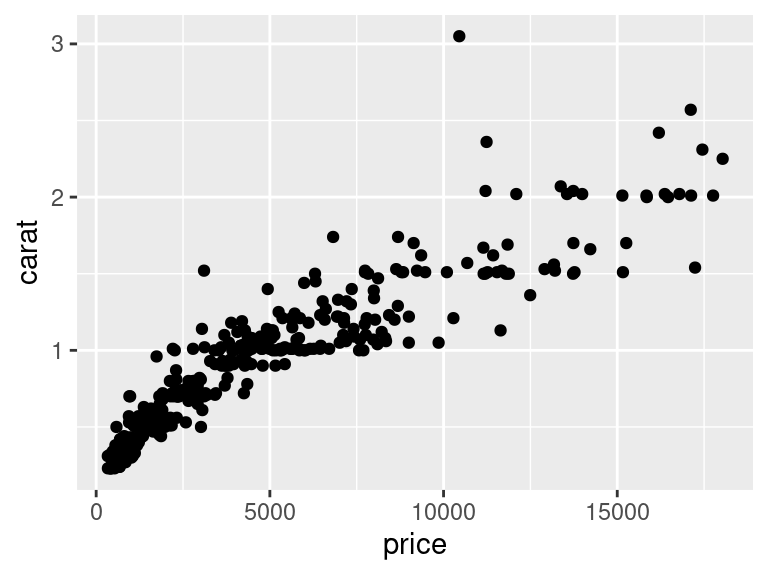
Pokračujme v příkladu konstrukcí bodového grafu:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point()
```
Výsledkem je prázdná formátované plocha. Volání `ggplot()` totiž pouze vytvoří prázdné "plátno", na které je potřeba přidávat jednotlivé vrstvy s obsahem.
Nové vrstvy se typicky přidávají voláním funkcí `geom_*()`. Tyto funkce nejsou nic jiného, než aliasy pro různé nastavení funkce `layer()`:
```r
layer(geom = NULL, stat = NULL, data = NULL, mapping = NULL,
position = NULL, params = list(), inherit.aes = TRUE,
check.aes = TRUE, check.param = TRUE, subset = NULL, show.legend = NA)
```
Funkce `layer()` má mnoho parametrů. Zásadní jsou tyto:
- `data`...tabulka s daty, která se má použít v dané vrstvě. Pokud tento parametr není zadán, potom se použije tabulka dat specifikované ve volání `ggpplot()`. Každá vrstva tak může pracovat s jinými daty. (A také `ggplot()` nemusí obsahovat specifikaci dat.)
- `geom`...typ geometrického objektu, který se má použít pro vizualizaci dat. Může se jednat o bod (`point`), polygon (`polygon`), úsečku (`line`) a mnoho dalších.
- `mapping`...obsahuje namapování proměnných na estetiky pomocí funkce `aes()`. Pokud není parametr specifikován, potom se použije specifikace z `ggplot()`. Pokud je specifikace v konfliktu se specifikací v `ggplot()`, potom se použije specifikace z `layer()`. Pokud je specifikována estetika, která není přiřazena v `ggplot()`, potom se použije jako doplnění ke specifikaci z `ggplot()`.
- `stat`...statistická transformace dat, která se má provést před vykreslením. Vykreslují se až transformované data.
- `position`...umožňuje upravit pozici hrubých dat před jejich vykreslením
Funkce `layer()` není zpravidla nikdy volána přímo. V podstatě vždy se používají funkce `geom_*()`. Pokud například chceme přidat vrstvu s bodovým grafem, potom použijeme `geom_point()`. Tato funkce je přesným ekvivalentem volání:
```r
layer(
data = NULL,
mapping = NULL,
geom = "point",
stat = "identity",
position = "identity"
)
```
Pokračujme v příkladu konstrukcí bodového grafu:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point()
```
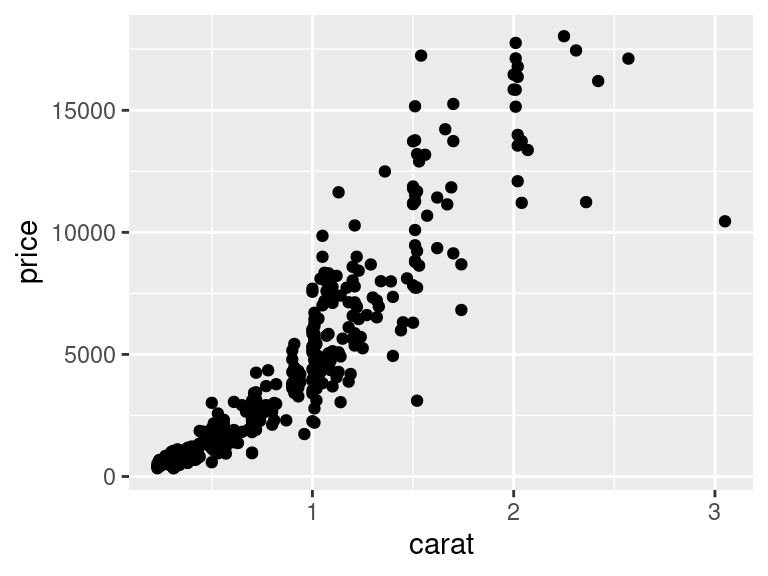 Vrstvu obsahující body jsme vytvořili voláním funkce `geom_point()`. Tato nová vrstva je k původnímu volání `ggplot()` připojena funkcí `+`. Pomocí této funkce můžeme do obrázku přidávat další vrstvy -- například vrstvu, která vykreslí proloženou křivku:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
geom_smooth()
```
```
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
```
Vrstvu obsahující body jsme vytvořili voláním funkce `geom_point()`. Tato nová vrstva je k původnímu volání `ggplot()` připojena funkcí `+`. Pomocí této funkce můžeme do obrázku přidávat další vrstvy -- například vrstvu, která vykreslí proloženou křivku:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
geom_smooth()
```
```
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
```
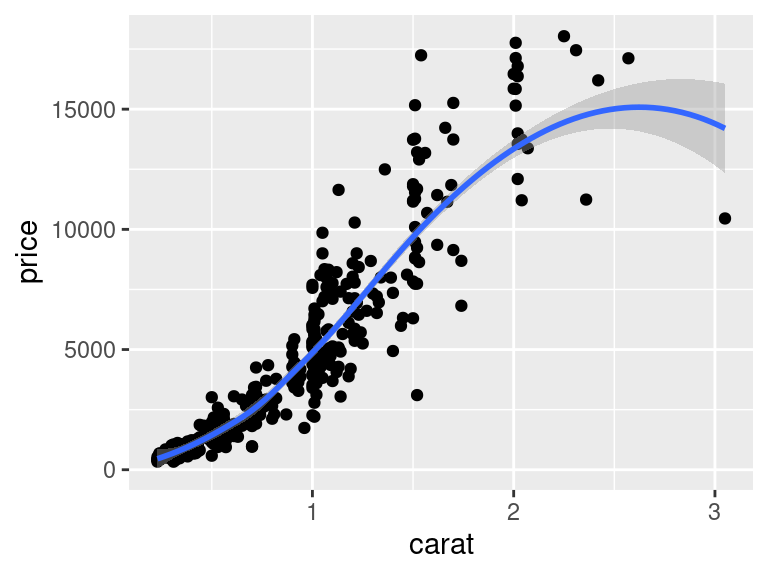 Jak vlastně funguje `ggplot2` vevnitř? Základní volání `ggplot()` vytvoří "prázdnou" datovou strukturu. Funkce `+` potom R říká, že má tuto datovou strukturu modifikovat. Jakým způsobem se to má stát určuje funkce volaná za `+`. Například `+ geom_point()` přidá k původní datové struktuře vrstvu s body, atd.
Primárním výsledkem volání `ggplot()` je tedy datová struktura. Tu můžeme přiřadit do proměnné:
```r
p <- diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point()
```
...a dále modifikovat...
```r
p <- p + geom_smooth()
```
...nebo "vytisknout":
```r
p
```
```
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
```
Jak vlastně funguje `ggplot2` vevnitř? Základní volání `ggplot()` vytvoří "prázdnou" datovou strukturu. Funkce `+` potom R říká, že má tuto datovou strukturu modifikovat. Jakým způsobem se to má stát určuje funkce volaná za `+`. Například `+ geom_point()` přidá k původní datové struktuře vrstvu s body, atd.
Primárním výsledkem volání `ggplot()` je tedy datová struktura. Tu můžeme přiřadit do proměnné:
```r
p <- diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point()
```
...a dále modifikovat...
```r
p <- p + geom_smooth()
```
...nebo "vytisknout":
```r
p
```
```
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
```
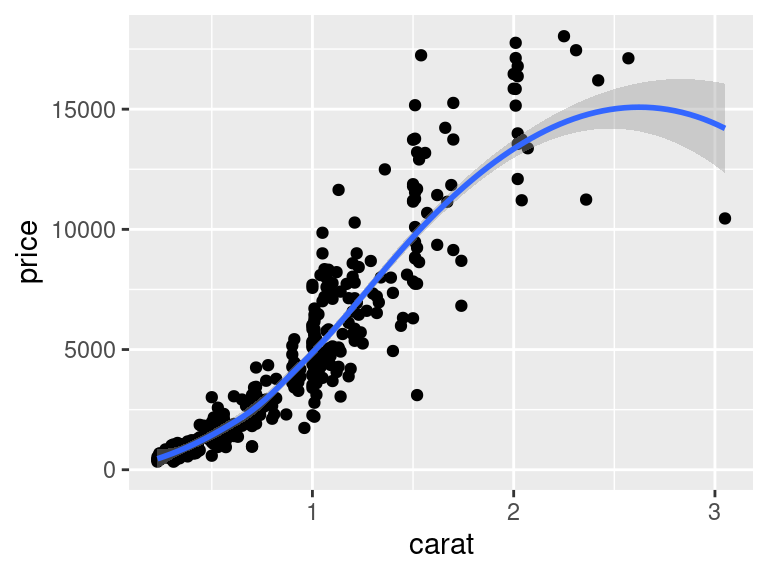 ## Mapování a nastavování estetik
V předchozím textu byl vysvětlen pojem estetika a mapování. Nyní se tomuto tématu budeme věnovat podrobněji. Každý `geom` má několik estetik -- dimenzí, jejichž podobu lze řídit podle určité proměnné. V případě bodového grafu (`point`) jde o: `x`, `y`, `shape`, `size`, `color`/`colour`, `fill`, `stroke` a `alpha`. Například `geom` `line` (spojnicový graf) má estetiky jiné -- nerozumí `stroke`, `shape` a `fill`. Namísto toho umí pracovat s `linetype`.
Výše uvedený příklad demonstruje mechanismus mapování. S pomocí funkce `aes()` je estetikám přiřazena proměnná. Některé estetiky je v závislosti na geomu nutné přiřadit. V případě `geom_point()` je to například `x` a `y`:
```r
diamonds %>%
ggplot(
aes(x = carat)
) +
geom_point()
```
```
## Error: geom_point requires the following missing aesthetics: y
```
## Mapování a nastavování estetik
V předchozím textu byl vysvětlen pojem estetika a mapování. Nyní se tomuto tématu budeme věnovat podrobněji. Každý `geom` má několik estetik -- dimenzí, jejichž podobu lze řídit podle určité proměnné. V případě bodového grafu (`point`) jde o: `x`, `y`, `shape`, `size`, `color`/`colour`, `fill`, `stroke` a `alpha`. Například `geom` `line` (spojnicový graf) má estetiky jiné -- nerozumí `stroke`, `shape` a `fill`. Namísto toho umí pracovat s `linetype`.
Výše uvedený příklad demonstruje mechanismus mapování. S pomocí funkce `aes()` je estetikám přiřazena proměnná. Některé estetiky je v závislosti na geomu nutné přiřadit. V případě `geom_point()` je to například `x` a `y`:
```r
diamonds %>%
ggplot(
aes(x = carat)
) +
geom_point()
```
```
## Error: geom_point requires the following missing aesthetics: y
```
 Pomocí `aes()` je možné mapovat i další estetiky:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, size = x, color = cut)
) +
geom_point()
```
Pomocí `aes()` je možné mapovat i další estetiky:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, size = x, color = cut)
) +
geom_point()
```
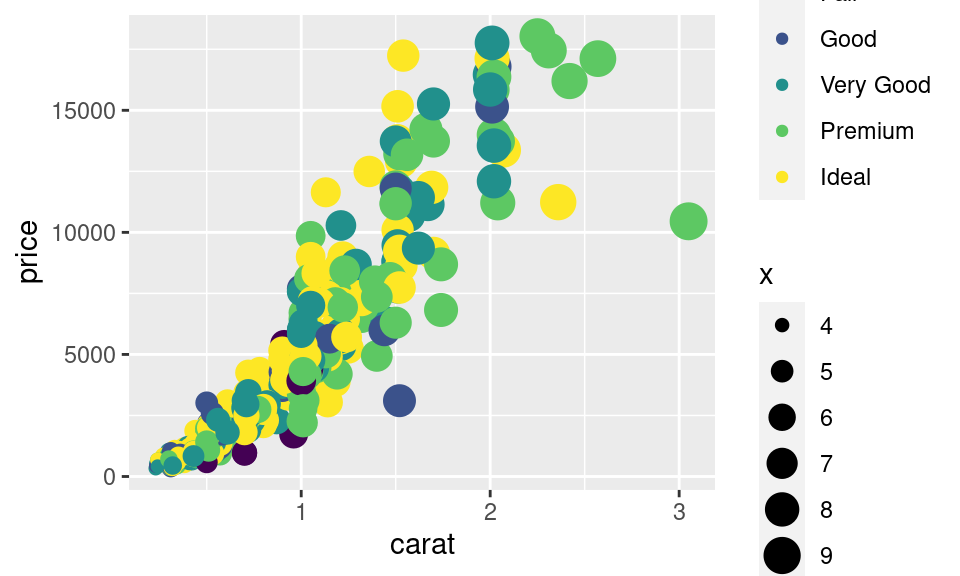 Pro každou namapovanou estetiku `ggplot2` vytvoří vodítko, které čtenáři umožní překlad z vizualizace do dat. V případě `x` a `y` vykreslí osy grafu. U zbývajících estetik vykreslil legendu.
Jednu proměnnou jde mapovat i na více estetik:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, size = cut, color = cut)
) +
geom_point()
```
Pro každou namapovanou estetiku `ggplot2` vytvoří vodítko, které čtenáři umožní překlad z vizualizace do dat. V případě `x` a `y` vykreslí osy grafu. U zbývajících estetik vykreslil legendu.
Jednu proměnnou jde mapovat i na více estetik:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, size = cut, color = cut)
) +
geom_point()
```
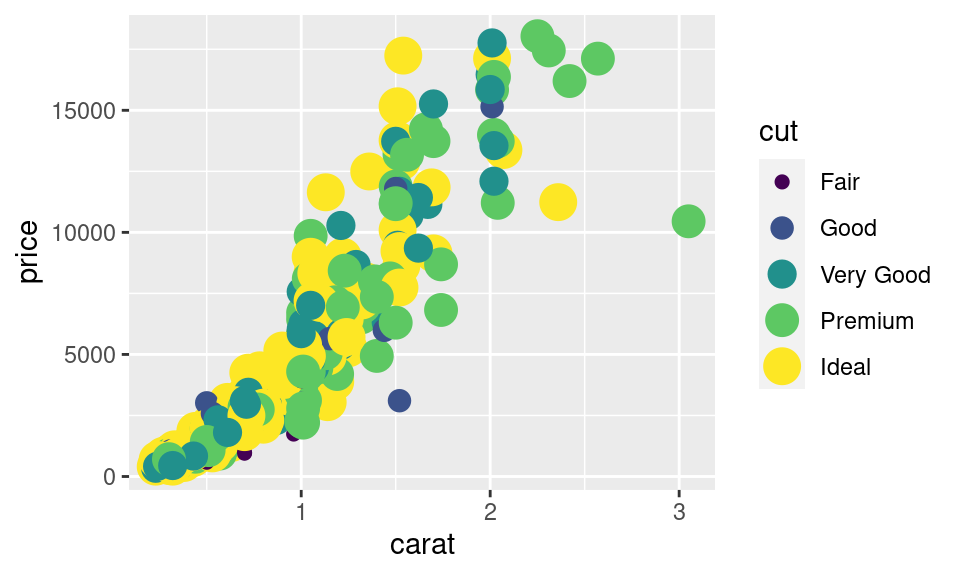 `ggplot2` takovou kombinaci zohlední i v legendě. Tento příklad ukazuje i další vlastnost `ggplot2`. Pokud uživatel požaduje provedení něčeho, co Tvůrce (H. Wickham) nepovažuje za dobrý nápad, vrátí `ggplot2` upozornění (via `message()`).
`ggplot2` poskytuje obrovské množství možností a částečně uživateli radí. Nicméně je na uživateli, aby vše nastavil tak, aby výsledné obrázky splňovaly svůj účel -- jasně čtenáři předávaly určitou informaci. Obrázek použitý v příkladu například trpí zásadní vadou, která se říká "overplotting". Pozorování se vzájemně překrývají a ve výsledný obrázek čtenáři mnoho neřekne. Nemůže vědět, zda se v některém místě vzájemně překrývá málo, nebo mnoho pozorování. Jednoduchou a často dostačující cestou jak bojovat s tímto problémem je nastavení průhlednosti (estetiky `alpha`). Tuto estetiku lze samozřejmě mapovat na proměnnou, ale v tomto případě ji použijeme pro ilustraci nastavení estetiky:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point(alpha = 0.1)
```
`ggplot2` takovou kombinaci zohlední i v legendě. Tento příklad ukazuje i další vlastnost `ggplot2`. Pokud uživatel požaduje provedení něčeho, co Tvůrce (H. Wickham) nepovažuje za dobrý nápad, vrátí `ggplot2` upozornění (via `message()`).
`ggplot2` poskytuje obrovské množství možností a částečně uživateli radí. Nicméně je na uživateli, aby vše nastavil tak, aby výsledné obrázky splňovaly svůj účel -- jasně čtenáři předávaly určitou informaci. Obrázek použitý v příkladu například trpí zásadní vadou, která se říká "overplotting". Pozorování se vzájemně překrývají a ve výsledný obrázek čtenáři mnoho neřekne. Nemůže vědět, zda se v některém místě vzájemně překrývá málo, nebo mnoho pozorování. Jednoduchou a často dostačující cestou jak bojovat s tímto problémem je nastavení průhlednosti (estetiky `alpha`). Tuto estetiku lze samozřejmě mapovat na proměnnou, ale v tomto případě ji použijeme pro ilustraci nastavení estetiky:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point(alpha = 0.1)
```
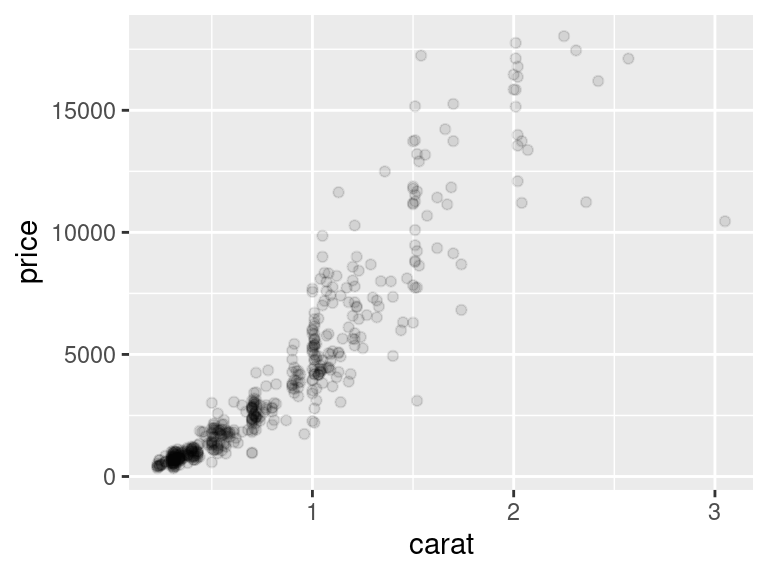 Pokud chce uživatel estetiku nastavit, je potřeba ji deklarovat v příslušné `geom_*()` funkci a mimo funkci `aes()`. Příklad ukazuje, že nastavení průhlednosti problém s overplottingem minimálně zmírnilo.
### Kontrola mapování
Ve všech příkladech jsme dosud pouze mapovali estetiku na určité proměnné. Mapování předává `ggplot2` informaci typu: "barvu puntíků urči podle proměnné `cut`". Jak konkrétně to `ggplot2` provede (t.j. bude mít špatný řez červenou, modrou, zelenou nebo jinou barvu) jsme zatím nijak neovlivňovali.
V této kapitole si ukážeme, jak lze s pomocí funkcí `scale_*_*()` měnit škálování a prvky, které pomáhají čtenáři převést vizualizaci zpět do dat.
Pro tyto účely budeme používat jednoduchou datovou tabulku se 3 pozorováními a 4 sloupci `x`, `y`, `z` a `w`...
```r
xtable <- data_frame(
x = c(1,2,3),
y = c(1,1,1),
z = c("A","B","C"),
w = c(-1,0,1)
)
```
...a jednoduchý bodový graf:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point()
```
Pokud chce uživatel estetiku nastavit, je potřeba ji deklarovat v příslušné `geom_*()` funkci a mimo funkci `aes()`. Příklad ukazuje, že nastavení průhlednosti problém s overplottingem minimálně zmírnilo.
### Kontrola mapování
Ve všech příkladech jsme dosud pouze mapovali estetiku na určité proměnné. Mapování předává `ggplot2` informaci typu: "barvu puntíků urči podle proměnné `cut`". Jak konkrétně to `ggplot2` provede (t.j. bude mít špatný řez červenou, modrou, zelenou nebo jinou barvu) jsme zatím nijak neovlivňovali.
V této kapitole si ukážeme, jak lze s pomocí funkcí `scale_*_*()` měnit škálování a prvky, které pomáhají čtenáři převést vizualizaci zpět do dat.
Pro tyto účely budeme používat jednoduchou datovou tabulku se 3 pozorováními a 4 sloupci `x`, `y`, `z` a `w`...
```r
xtable <- data_frame(
x = c(1,2,3),
y = c(1,1,1),
z = c("A","B","C"),
w = c(-1,0,1)
)
```
...a jednoduchý bodový graf:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point()
```
 `ggplot2` namapoval data na estetiky (pozice) a vykreslil osy, které čtenáři umožňují číst data. Obrázek je takový, jaký asi všichni očekávají. Nicméně to nemusí být to, co uživatel chce. Co může chtít změnit? Například:
- jméno škály (`name`)
- popisky na ose (`labels`)
- pozice "hlavních" popisků na ose (`breaks`)
- pozice "pomocných" popisků/čar na ose (`minor_breaks`)
- interval zobrazený na obrázku -- "jak dlouhá" má být osa (`limits`)
- pozici osy (`position`)
- transformaci hodnot na ose -- například zobrazení logaritmu pozorovaných hodnot (`trans`)
- zobrazení sekundární osy (`sec.axis`)
Úplný výčet možností se samozřejmě liší podle estetiky.
Mapování se řídí pomocí funkcí `scale_*_*()`, která se podobně jako `geom_()` připojují k volání `ggplot()` pomocí funkce `+`. Jména funkcí `scale_*_*()` se mohou zdá komplikovaná, ale opak je pravdou. Ve jejích jménech je totiž systém. Jméno funkce se sestává ze tří částí, spojených znakem "_":
1. Všechna jména začínají `scale`
2. Druhá část jména je jméno estetiky, kterou chceme kontrolovat
3. Poslední část jména je jméno konkrétní škály (to je potřeba si občas pamatovat nebo najít)
Pokud bychom například chtěli změnit jméno osy x (estetika `x`) na našem obrázku, potom budeme chtít použít funkci:
```r
scale_x_continuous()
```
První část jména je daná, druhá je jasná a třetí odkazuje na povahu proměnná `x` v tabulce `xtable`, která je spojitá. (Takto pěkně ale jména škály nefungují vždy. Občas je třeba hledat.)
Pokud známe jméno, je z poloviny vyhráno:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(name = "Tohle je osa x")
```
`ggplot2` namapoval data na estetiky (pozice) a vykreslil osy, které čtenáři umožňují číst data. Obrázek je takový, jaký asi všichni očekávají. Nicméně to nemusí být to, co uživatel chce. Co může chtít změnit? Například:
- jméno škály (`name`)
- popisky na ose (`labels`)
- pozice "hlavních" popisků na ose (`breaks`)
- pozice "pomocných" popisků/čar na ose (`minor_breaks`)
- interval zobrazený na obrázku -- "jak dlouhá" má být osa (`limits`)
- pozici osy (`position`)
- transformaci hodnot na ose -- například zobrazení logaritmu pozorovaných hodnot (`trans`)
- zobrazení sekundární osy (`sec.axis`)
Úplný výčet možností se samozřejmě liší podle estetiky.
Mapování se řídí pomocí funkcí `scale_*_*()`, která se podobně jako `geom_()` připojují k volání `ggplot()` pomocí funkce `+`. Jména funkcí `scale_*_*()` se mohou zdá komplikovaná, ale opak je pravdou. Ve jejích jménech je totiž systém. Jméno funkce se sestává ze tří částí, spojených znakem "_":
1. Všechna jména začínají `scale`
2. Druhá část jména je jméno estetiky, kterou chceme kontrolovat
3. Poslední část jména je jméno konkrétní škály (to je potřeba si občas pamatovat nebo najít)
Pokud bychom například chtěli změnit jméno osy x (estetika `x`) na našem obrázku, potom budeme chtít použít funkci:
```r
scale_x_continuous()
```
První část jména je daná, druhá je jasná a třetí odkazuje na povahu proměnná `x` v tabulce `xtable`, která je spojitá. (Takto pěkně ale jména škály nefungují vždy. Občas je třeba hledat.)
Pokud známe jméno, je z poloviny vyhráno:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(name = "Tohle je osa x")
```
 Jak bylo zmíněno výše, pomocí škál je možné nastavit velké množství parametrů:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(
name = "Tohle je osa x",
breaks = c(1,2,3),
labels = c("málo","víc","málo"),
limits = c(0,4),
position = "top"
)
```
Jak bylo zmíněno výše, pomocí škál je možné nastavit velké množství parametrů:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(
name = "Tohle je osa x",
breaks = c(1,2,3),
labels = c("málo","víc","málo"),
limits = c(0,4),
position = "top"
)
```
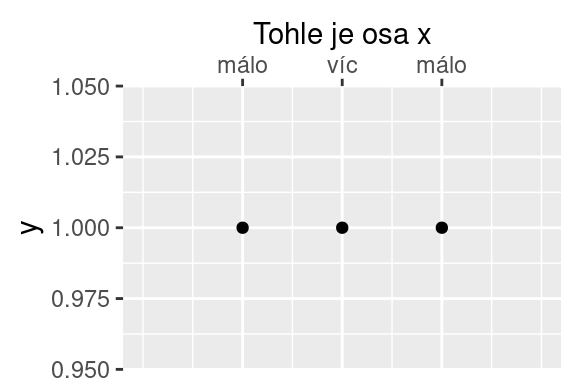 Poněkud specifické je nastavení transformace. V praxi se často používá logaritmická transformace:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(trans = "log10")
```
Poněkud specifické je nastavení transformace. V praxi se často používá logaritmická transformace:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous(trans = "log10")
```
 Řada transformací je pro uživatele připravená (viz `?scale_x_continuous()`). Uživatel má navíc možnost vytvořit vlastní transformace. Pro nejčastější transformace má `ggplot2` předpřipravené škály -- například `log10` nebo `reverse`:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_log10()
```
Řada transformací je pro uživatele připravená (viz `?scale_x_continuous()`). Uživatel má navíc možnost vytvořit vlastní transformace. Pro nejčastější transformace má `ggplot2` předpřipravené škály -- například `log10` nebo `reverse`:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_log10()
```
 V předchozích příkladech jsme volali funkci `scale_x_*()` pro nastavení mapování estetiky `x`. Nicméně ani jednou jsme neupravovali estetiku `y` a taky to fungovalo. Jak je to možné? Pokud není funkce `scale_*_*()` explicitně volána uživatelem, `ggplot2` odhadne, která funkce je nejvhodnější a zavolá ji interně sám. Volání:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point()
```
Je tak ve výsledku ekvivalentní k:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous() +
scale_y_continuous()
```
Pokud se změní povaha podkladových dat, potom se i `ggplot2` rozhodne volat jinou funkci `scale_*_*()`. V případě volání:
```r
xtable %>%
ggplot(
aes(x = factor(x), y = y)
) +
geom_point()
```
kde proměnná `x` je konvertována na faktor. Vrátí `ggplot2` obrázek ekvivalentní volání:
```r
xtable %>%
ggplot(
aes(x = factor(x), y = y)
) +
geom_point() +
scale_x_discrete() +
scale_y_continuous()
```
V předchozích příkladech jsme volali funkci `scale_x_*()` pro nastavení mapování estetiky `x`. Nicméně ani jednou jsme neupravovali estetiku `y` a taky to fungovalo. Jak je to možné? Pokud není funkce `scale_*_*()` explicitně volána uživatelem, `ggplot2` odhadne, která funkce je nejvhodnější a zavolá ji interně sám. Volání:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point()
```
Je tak ve výsledku ekvivalentní k:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
scale_x_continuous() +
scale_y_continuous()
```
Pokud se změní povaha podkladových dat, potom se i `ggplot2` rozhodne volat jinou funkci `scale_*_*()`. V případě volání:
```r
xtable %>%
ggplot(
aes(x = factor(x), y = y)
) +
geom_point()
```
kde proměnná `x` je konvertována na faktor. Vrátí `ggplot2` obrázek ekvivalentní volání:
```r
xtable %>%
ggplot(
aes(x = factor(x), y = y)
) +
geom_point() +
scale_x_discrete() +
scale_y_continuous()
```
 `ggplot2` v tomto případě volá škálu vytvořenou pro mapování diskrétních proměnných.
#### Mapování barev (estetiky `colour` a `fill`)
Pomocí funkcí `scale_*_*()` lze měnit mapování všech estetik. Mezi nejčastější upravované škály patří bezesporu barvy, které se mapují v estetikách `color`/`colour` a `fill`.
Poznámka: `ggplot2` neumí a podle jeho tvůrců nikdy nebude umět vybarvovat texturou ("šrafováním").
Pro ilustraci těchto estetik použijeme následující podobu bodového grafu:
```r
xtable %>%
ggplot(
aes(x = x, y = y, color = z, fill = w)
) +
geom_point(
shape = 21,
stroke = 3,
size = 10
) +
scale_x_continuous(
limits = c(0.5,3.5)
) +
theme(
legend.direction = "horizontal"
) -> p
p
```
`ggplot2` v tomto případě volá škálu vytvořenou pro mapování diskrétních proměnných.
#### Mapování barev (estetiky `colour` a `fill`)
Pomocí funkcí `scale_*_*()` lze měnit mapování všech estetik. Mezi nejčastější upravované škály patří bezesporu barvy, které se mapují v estetikách `color`/`colour` a `fill`.
Poznámka: `ggplot2` neumí a podle jeho tvůrců nikdy nebude umět vybarvovat texturou ("šrafováním").
Pro ilustraci těchto estetik použijeme následující podobu bodového grafu:
```r
xtable %>%
ggplot(
aes(x = x, y = y, color = z, fill = w)
) +
geom_point(
shape = 21,
stroke = 3,
size = 10
) +
scale_x_continuous(
limits = c(0.5,3.5)
) +
theme(
legend.direction = "horizontal"
) -> p
p
```
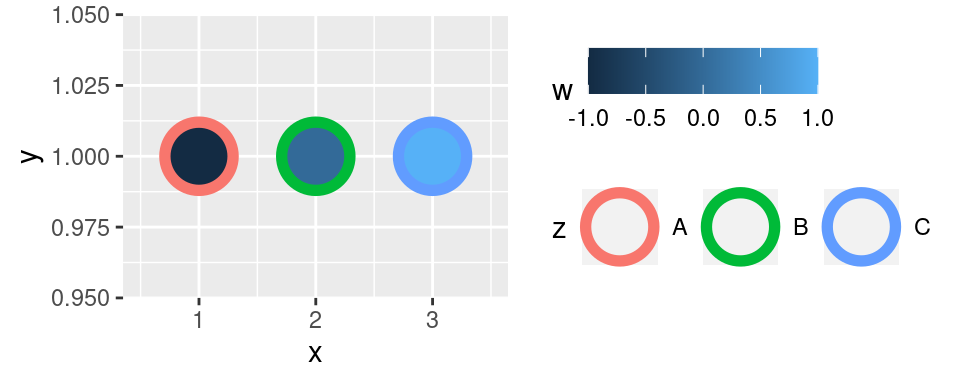 Výsledná podoba obrázku je ovlivněna funkcí `theme()`. Její fungování je popsáno níže. Celá struktura je přiřazená do proměnné `p`. S tou budeme nadále pracovat.
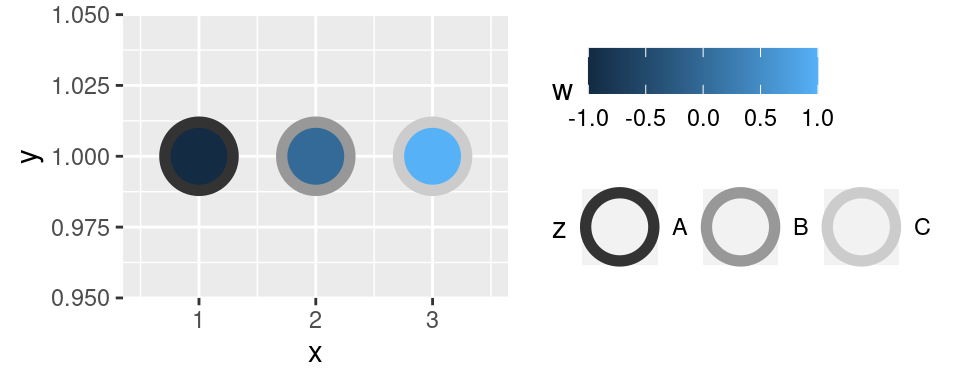
Tento graf mapuje proměnné `z` a `w` na estetiky `color` a `fill`. Ostatní estetiky jsou nastaveny a jsou pro všechny body v grafu shodné.
Proměnná `z` a `w` se liší ve své povaze. `w`je spojitá proměnná a `z` je kategoriální. Práce s barvami by se obecně měla řídit podle povahy zobrazovaných dat:
- Spojité proměnné se typicky zobrazují barevným přechodem -- jak vidíte na obrázku, základní volbou `ggplot2` je přechod z tmavě do světle modré.
- Kategoriální proměnné, jejichž hodnoty jsou "na stejné úrovni". Příkladem takové proměnné mohou být například značky automobilů. V takovém případě je zvolit barvy, které jsou pro vnímání člověka "stejně daleko" od sebe. Příkladem takového výběru barev může být proměnná `z` v ukázkovém obrázku.
- Posledním typem jsou kategoriální proměnné, které vyjadřují sekvenci (např.: malá, střední, velká). V takovém případě je vhodné volit barevný přechod, který je také rozdělen do kroků, které musí být tak velké, aby byly pro člověka jasně odlišitelné.
Při volbě barev je také užitečné myslet na barvoslepé a na tisk na černobílé tiskárně. Jiné barvy jsou také vhodné pro plochy a jiné pro body. Ve výsledku je výběr barev nesmírně složitý. Najít sekvenci barev pro 10 úrovní je těžké, pro 20 úrovní je to nemožné. Moudrým postupem je proto používat uměřený počet barev (úrovní) a v jejich volbě vycházet z doporučení odborníků.
##### Spojité proměnné
Typickým postupem zobrazování spojité proměnné v barvě je použití barevného přechodu (gradientu) mezi dvěma nebo více barvami. `ggplot2` nabízí hned 4 škály založené na gradientech:
`scale_*_gradient()` (identické se `scale_*_continuous()`) je základní volbou, po které u spojitých proměnných `ggplot2` sáhne, pokud uživatel neporoučí jinak. Vykresluje přechod mezi dvěma barvami, které jsou nastavené parametry `low` a `high`:
```r
p + scale_fill_gradient(low = "hotpink", high = "#56B1F7")
```
Výsledná podoba obrázku je ovlivněna funkcí `theme()`. Její fungování je popsáno níže. Celá struktura je přiřazená do proměnné `p`. S tou budeme nadále pracovat.
Tento graf mapuje proměnné `z` a `w` na estetiky `color` a `fill`. Ostatní estetiky jsou nastaveny a jsou pro všechny body v grafu shodné.
Proměnná `z` a `w` se liší ve své povaze. `w`je spojitá proměnná a `z` je kategoriální. Práce s barvami by se obecně měla řídit podle povahy zobrazovaných dat:
- Spojité proměnné se typicky zobrazují barevným přechodem -- jak vidíte na obrázku, základní volbou `ggplot2` je přechod z tmavě do světle modré.
- Kategoriální proměnné, jejichž hodnoty jsou "na stejné úrovni". Příkladem takové proměnné mohou být například značky automobilů. V takovém případě je zvolit barvy, které jsou pro vnímání člověka "stejně daleko" od sebe. Příkladem takového výběru barev může být proměnná `z` v ukázkovém obrázku.
- Posledním typem jsou kategoriální proměnné, které vyjadřují sekvenci (např.: malá, střední, velká). V takovém případě je vhodné volit barevný přechod, který je také rozdělen do kroků, které musí být tak velké, aby byly pro člověka jasně odlišitelné.
Při volbě barev je také užitečné myslet na barvoslepé a na tisk na černobílé tiskárně. Jiné barvy jsou také vhodné pro plochy a jiné pro body. Ve výsledku je výběr barev nesmírně složitý. Najít sekvenci barev pro 10 úrovní je těžké, pro 20 úrovní je to nemožné. Moudrým postupem je proto používat uměřený počet barev (úrovní) a v jejich volbě vycházet z doporučení odborníků.
##### Spojité proměnné
Typickým postupem zobrazování spojité proměnné v barvě je použití barevného přechodu (gradientu) mezi dvěma nebo více barvami. `ggplot2` nabízí hned 4 škály založené na gradientech:
`scale_*_gradient()` (identické se `scale_*_continuous()`) je základní volbou, po které u spojitých proměnných `ggplot2` sáhne, pokud uživatel neporoučí jinak. Vykresluje přechod mezi dvěma barvami, které jsou nastavené parametry `low` a `high`:
```r
p + scale_fill_gradient(low = "hotpink", high = "#56B1F7")
```
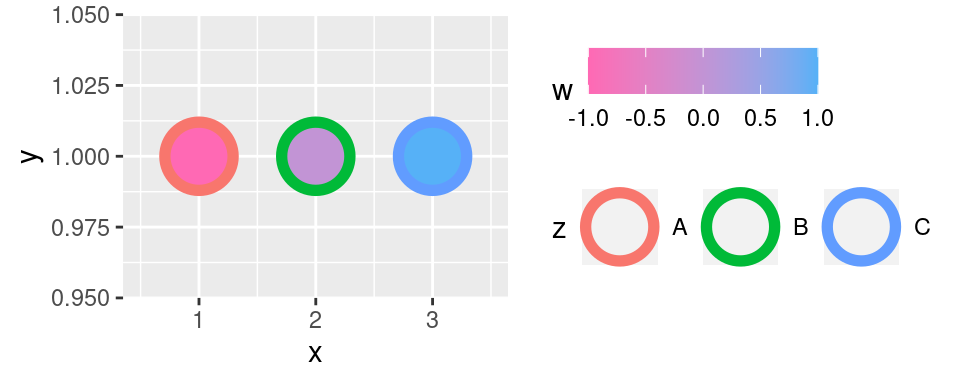 V příkladu je nastaven přechod z tmavě poníkové do modré. Barva je vždy definována jako řetězec (nebo funkcí, která řetězec nebo jejich vektor vytvoří) -- a to buď svým jménem (`"hotpink"`) nebo RGB kódem (`"#56B1F7"`).
`scale_*_gradient2()` je derivátem `scale_*_gradient()` umožňuje vytvořit přechod přes tři barvy (`low`, `mid`, `high`) a specifikovat pozici středního bodu parametrem `midpoint`. (Parametr `midpoint` je defaultně nastaven na hodnotu 0.)
```r
p + scale_fill_gradient2(midpoint = 0.5)
```
V příkladu je nastaven přechod z tmavě poníkové do modré. Barva je vždy definována jako řetězec (nebo funkcí, která řetězec nebo jejich vektor vytvoří) -- a to buď svým jménem (`"hotpink"`) nebo RGB kódem (`"#56B1F7"`).
`scale_*_gradient2()` je derivátem `scale_*_gradient()` umožňuje vytvořit přechod přes tři barvy (`low`, `mid`, `high`) a specifikovat pozici středního bodu parametrem `midpoint`. (Parametr `midpoint` je defaultně nastaven na hodnotu 0.)
```r
p + scale_fill_gradient2(midpoint = 0.5)
```
 `scale_*_gradientn()` umožňuje použít přechod přes tolik barev, kolik si jen srdce uživatele přeje. Z tohoto důvodu neobsahuje žádné základní nastavení:
```r
p + scale_fill_gradientn()
```
```
## Error in scale_fill_gradientn(): argument "colors" is missing, with no default
```
Uživatel musí prostřednictvím parametru `colours` zadat vektor barev, které se mají použít. Domnívám se, že pro uživatele -- neodborníka -- se jedná o nemožný úkol. Je však možné použít předpřipravené palety, které jsou součástí mnoha balíků. Následující příklad využívá paletu `inferno` z balíku **viridis**:
```r
p + scale_fill_gradientn(colours = viridis::inferno(3))
```
`scale_*_gradientn()` umožňuje použít přechod přes tolik barev, kolik si jen srdce uživatele přeje. Z tohoto důvodu neobsahuje žádné základní nastavení:
```r
p + scale_fill_gradientn()
```
```
## Error in scale_fill_gradientn(): argument "colors" is missing, with no default
```
Uživatel musí prostřednictvím parametru `colours` zadat vektor barev, které se mají použít. Domnívám se, že pro uživatele -- neodborníka -- se jedná o nemožný úkol. Je však možné použít předpřipravené palety, které jsou součástí mnoha balíků. Následující příklad využívá paletu `inferno` z balíku **viridis**:
```r
p + scale_fill_gradientn(colours = viridis::inferno(3))
```
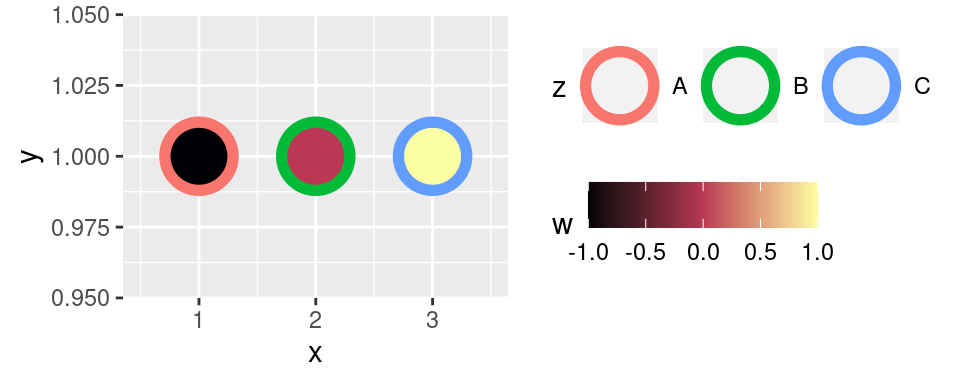 Využití `scale_*_gradientn()` je vhodné spíše v plochách. Nicméně i tam je dobré spolehnout na rady odborníků. Příklad "plošného" obrázku:
Využití `scale_*_gradientn()` je vhodné spíše v plochách. Nicméně i tam je dobré spolehnout na rady odborníků. Příklad "plošného" obrázku:
 Na radách odborníků je zcela postaven `scale_*_distiller()`. Pracuje s ručně vybranými diskrétními paletami, které jsou dostupné na http://colorbrewer2.org/. `scale_*_distiller()` tyto diskrétní palety adaptuje i pro spojité proměnné. Rozumný způsob práce je na webu zvolit vhodnou barevnou škálu a její jméno specifikovat v parametru `palette`. Ten um pracovat s číslem palety i s jejím jménem:
```r
p + scale_fill_distiller(palette = "YlGnBu")
```
Na radách odborníků je zcela postaven `scale_*_distiller()`. Pracuje s ručně vybranými diskrétními paletami, které jsou dostupné na http://colorbrewer2.org/. `scale_*_distiller()` tyto diskrétní palety adaptuje i pro spojité proměnné. Rozumný způsob práce je na webu zvolit vhodnou barevnou škálu a její jméno specifikovat v parametru `palette`. Ten um pracovat s číslem palety i s jejím jménem:
```r
p + scale_fill_distiller(palette = "YlGnBu")
```
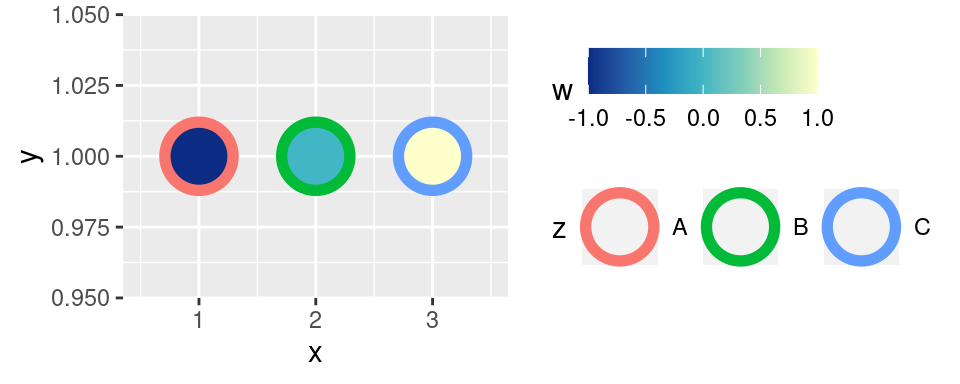 Parametrem `direction`, který nabývá hodnot `1` nebo `-1`, lze pořadí barev obrátit:
```r
p + scale_fill_distiller(palette = "YlGnBu", direction = 1)
```
Parametrem `direction`, který nabývá hodnot `1` nebo `-1`, lze pořadí barev obrátit:
```r
p + scale_fill_distiller(palette = "YlGnBu", direction = 1)
```
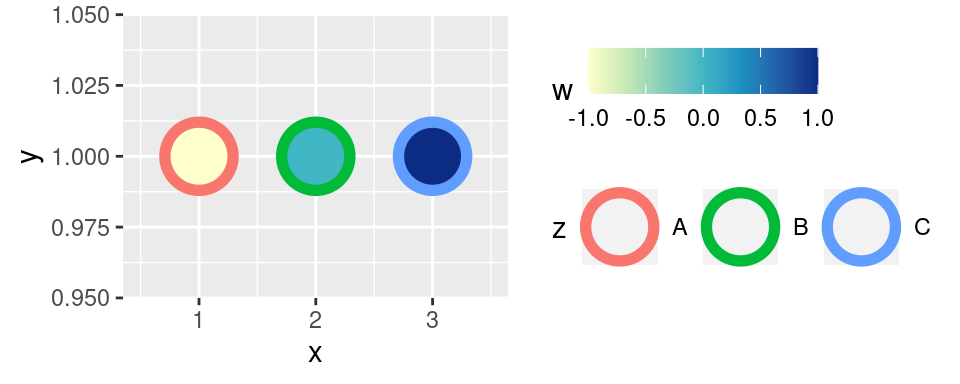 Používání http://colorbrewer2.org/ lze doporučit v maximální rozumné míře.
##### Diskrétní proměnné
Pro diskrétní proměnné je výchozí volbou `scale_*_hue()`. Tato škála vybírá od sebe stejně vzdálené barvy na "HCL wheel" (viz např. Wikipedie). Teoreticky je tak schopna vytvořit barevné schéma pro prakticky neomezený počet kategorií. V praxi od sebe budou barvy při vyšším počtu kategorií nerozpoznatelné.
```r
p + scale_color_hue()
```
Používání http://colorbrewer2.org/ lze doporučit v maximální rozumné míře.
##### Diskrétní proměnné
Pro diskrétní proměnné je výchozí volbou `scale_*_hue()`. Tato škála vybírá od sebe stejně vzdálené barvy na "HCL wheel" (viz např. Wikipedie). Teoreticky je tak schopna vytvořit barevné schéma pro prakticky neomezený počet kategorií. V praxi od sebe budou barvy při vyšším počtu kategorií nerozpoznatelné.
```r
p + scale_color_hue()
```
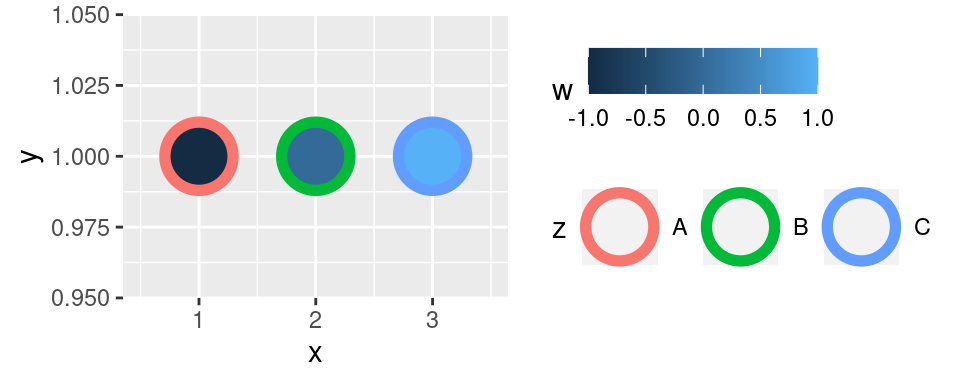 `scale_*_hue()` umožňuje vybrat výchozí bod na HCL wheel a parametrem `direction` směr, jakým se na něm výběr pohybuje:
```r
p + scale_color_hue(direction = -1)
```
`scale_*_hue()` umožňuje vybrat výchozí bod na HCL wheel a parametrem `direction` směr, jakým se na něm výběr pohybuje:
```r
p + scale_color_hue(direction = -1)
```
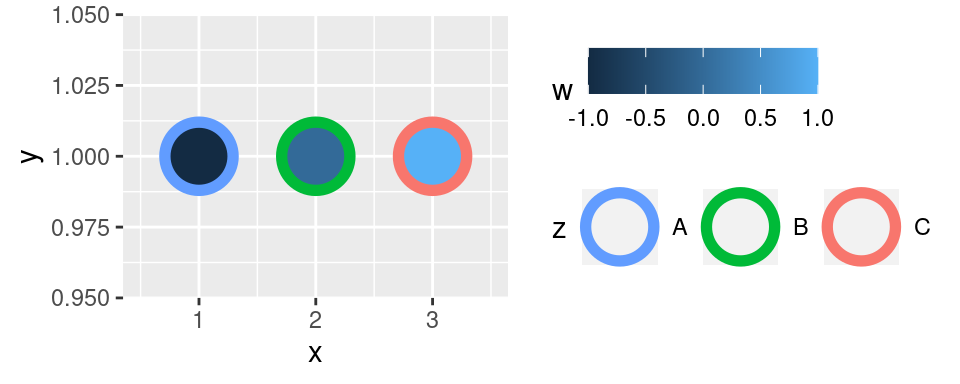 Zejména při finalizaci grafických výstupů je vhodné poohlédnout se po předpřipravených paletách. V samotném `ggplot2` jde o `scale_*_brewer()` -- bratra `scale_*_distiller()` pro diskrétní veličiny.
```r
p + scale_color_brewer(palette = "Set1")
```
Zejména při finalizaci grafických výstupů je vhodné poohlédnout se po předpřipravených paletách. V samotném `ggplot2` jde o `scale_*_brewer()` -- bratra `scale_*_distiller()` pro diskrétní veličiny.
```r
p + scale_color_brewer(palette = "Set1")
```
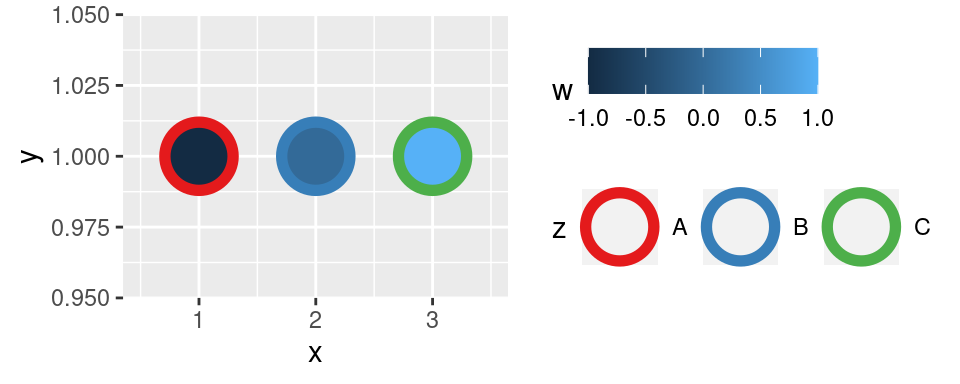 Speciální škálou je `scale_*_grey()`. Ta, jak název napovídá, mapuje do odstínů šedé:
```r
p + scale_color_grey()
```
Speciální škálou je `scale_*_grey()`. Ta, jak název napovídá, mapuje do odstínů šedé:
```r
p + scale_color_grey()
```
 Speciálními případy škál jsou `scale_*_manual()` a `scale_*_identity()`. `scale_*_manual()` umožňuje uživateli vytvořit si vlastní škálu. U barev bude tato možnost využívána asi jen zřídka. Za určitých okolností se však může hodit u jiných estetik -- například u `shape`.
`scale_*_identity()` dokáže vzít proměnnou z datové tabulky a použít ji "tak jak je" pro vykreslení barev, tvarů a podobně.
#### Co jsme zamlčeli...
Všechny krásné škálovací funkce `scale_*_*()` v posledku využívají služeb konstruktorových funkcí `discrete_scale()` a `continuous_scale()`. S těmito funkcemi komunikujete ze `scale_*_*()` přes argument `...`. Pokud tedy budete chtít provádět něco složitějšího, tak se vyplatí projít si nápovědu právě k těmto konstruktorovým funkcím.
## Grupování
U některých funkcí `geom_*()` je mezi estetikami uvedena jedna s názvem `group`. Lehko si můžete ověřit, že se nijak nepřekládá do vizuální podoby. Její funkce je totiž jiná. Sděluje `ggplot2`, že určitá skupina pozorování "patří k sobě" -- tvoří jednu skupinu.
Praktické využití lze ilustrovat na proložení křivky v tabulce `diamonds`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
geom_smooth()
```
Speciálními případy škál jsou `scale_*_manual()` a `scale_*_identity()`. `scale_*_manual()` umožňuje uživateli vytvořit si vlastní škálu. U barev bude tato možnost využívána asi jen zřídka. Za určitých okolností se však může hodit u jiných estetik -- například u `shape`.
`scale_*_identity()` dokáže vzít proměnnou z datové tabulky a použít ji "tak jak je" pro vykreslení barev, tvarů a podobně.
#### Co jsme zamlčeli...
Všechny krásné škálovací funkce `scale_*_*()` v posledku využívají služeb konstruktorových funkcí `discrete_scale()` a `continuous_scale()`. S těmito funkcemi komunikujete ze `scale_*_*()` přes argument `...`. Pokud tedy budete chtít provádět něco složitějšího, tak se vyplatí projít si nápovědu právě k těmto konstruktorovým funkcím.
## Grupování
U některých funkcí `geom_*()` je mezi estetikami uvedena jedna s názvem `group`. Lehko si můžete ověřit, že se nijak nepřekládá do vizuální podoby. Její funkce je totiž jiná. Sděluje `ggplot2`, že určitá skupina pozorování "patří k sobě" -- tvoří jednu skupinu.
Praktické využití lze ilustrovat na proložení křivky v tabulce `diamonds`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
geom_smooth()
```
 V tomto případě se proložila křivka přes všechny pozorování. Můžeme se ale chtít podívat, jestli je závislost stejná pro různé *druhy* kamenů -- například pro skupiny definované kvalitou řezu (`cut`). V tomto případě použijeme estetiku `group`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, group = cut)
) +
geom_point() +
geom_smooth()
```
V tomto případě se proložila křivka přes všechny pozorování. Můžeme se ale chtít podívat, jestli je závislost stejná pro různé *druhy* kamenů -- například pro skupiny definované kvalitou řezu (`cut`). V tomto případě použijeme estetiku `group`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, group = cut)
) +
geom_point() +
geom_smooth()
```
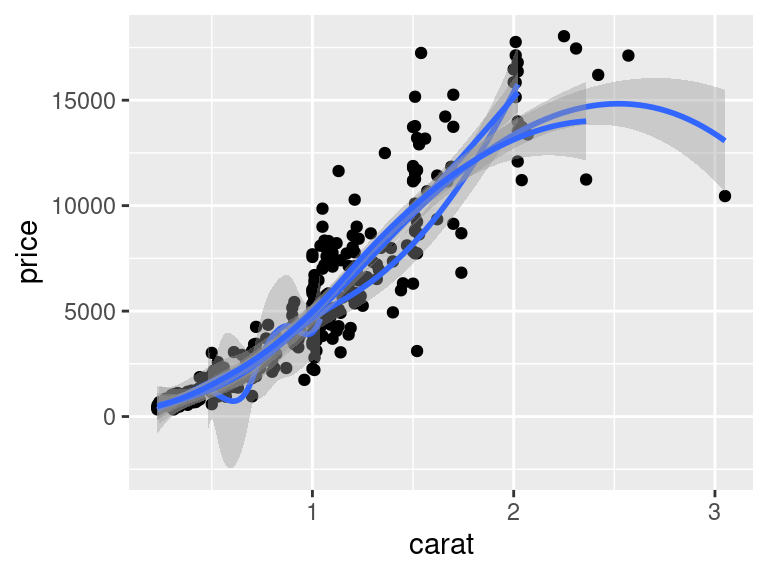 V tomto případě `geom_smooth()`, který estetice `group` rozumí, pracuje s každou skupinou vymezenou hodnotou kategoriální proměnné `cut` zvlášť. Fakticky každou skupinu proloží její vlastní křivkou.
V praxi je často užitečné pro zpřehlednění využít možnosti mapování jedné proměnné na více estetik:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, group = cut, color = cut)
) +
geom_point() +
geom_smooth()
```
V tomto případě `geom_smooth()`, který estetice `group` rozumí, pracuje s každou skupinou vymezenou hodnotou kategoriální proměnné `cut` zvlášť. Fakticky každou skupinu proloží její vlastní křivkou.
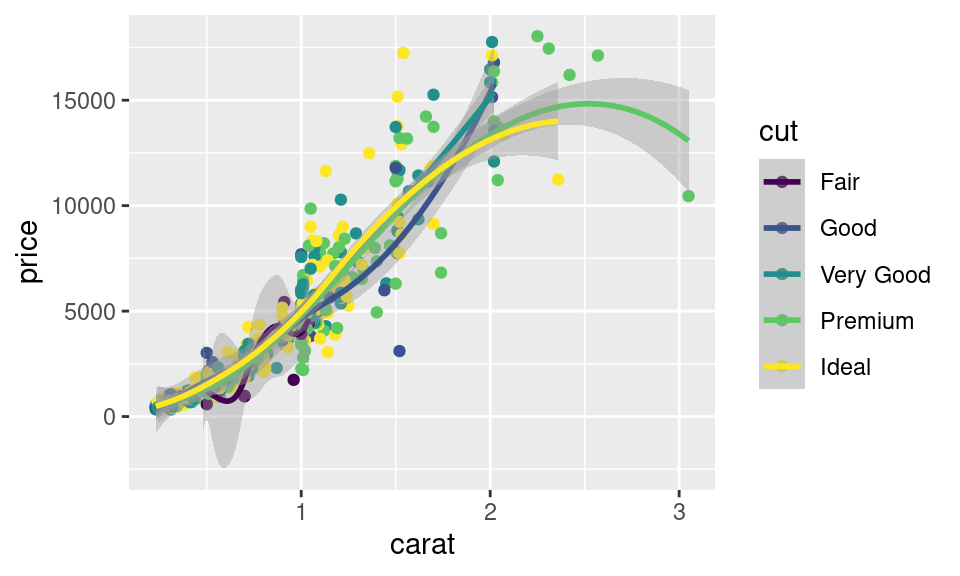
V praxi je často užitečné pro zpřehlednění využít možnosti mapování jedné proměnné na více estetik:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, group = cut, color = cut)
) +
geom_point() +
geom_smooth()
```
 Všiměte si že v tomto případě dostanete stejný výsledek i při namapování kategorické proměnné na estetiku `color`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, color = cut)
) +
geom_point() +
geom_smooth()
```
Všiměte si že v tomto případě dostanete stejný výsledek i při namapování kategorické proměnné na estetiku `color`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price, color = cut)
) +
geom_point() +
geom_smooth()
```
 ## Statistické transformace
`ggplot2` umožňuje nejen vykreslovat samotná data, ale i jejich interně vytvořené statistické transformace. Příkladem může být například proložení křivkou (`geom_smooth()`). Jejich tvorbu mají na starosti funkce `stat_*()`. Vztah mezi funkcemi `geom_*()` a `stat_*()` není úplně jasný. Každá transformace (`stat`) má svůj výchozí (přednastavený) geometrický tvar (`geom`) a každý `geom` má svůj výchozí `stat`. V některých případech tak může být jedno, jestli uživatel volá `geom` nebo ekvivalentní `stat`, Viz například použití `stat_smooth()`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
stat_smooth()
```
## Statistické transformace
`ggplot2` umožňuje nejen vykreslovat samotná data, ale i jejich interně vytvořené statistické transformace. Příkladem může být například proložení křivkou (`geom_smooth()`). Jejich tvorbu mají na starosti funkce `stat_*()`. Vztah mezi funkcemi `geom_*()` a `stat_*()` není úplně jasný. Každá transformace (`stat`) má svůj výchozí (přednastavený) geometrický tvar (`geom`) a každý `geom` má svůj výchozí `stat`. V některých případech tak může být jedno, jestli uživatel volá `geom` nebo ekvivalentní `stat`, Viz například použití `stat_smooth()`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() +
stat_smooth()
```
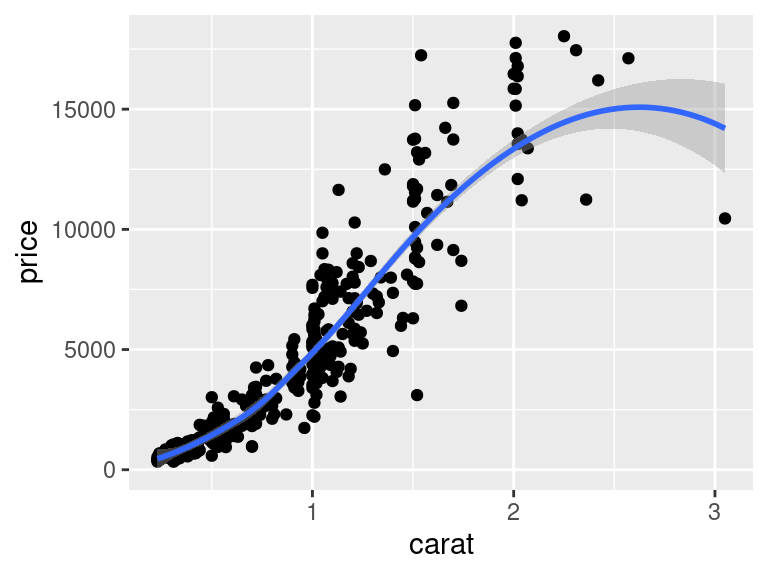 Tato nejednoznačnost vymezení toho, co vlastně dělá `stat_*()` a co `geom_*()` je velmi otravnou nedokonalostí v návrhu `ggplot2` (a v `ggvis` je již vyřešena). Pokud není nevyhnutelné volat přímo `stat_*()` nutné, je lepší vždy používat funkce `geom_*()`.
Pro přímé volání `stat_*()` existovaly v podstatě dva důvody:
1. potřeba specifických nastavení statistických transformací
1. potřeba použití jiného než standardního geomu pro vykreslení statistické transformace
Pohledem do nápovědy zjistíte, že `stat_smooth()` umožňuje mnohem více nastavení vyhlazování:
```r
geom_smooth(mapping = NULL, data = NULL, stat = "smooth",
position = "identity", ..., method = "auto", formula = y ~ x,
se = TRUE, na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)
stat_smooth(mapping = NULL, data = NULL, geom = "smooth",
position = "identity", ..., method = "auto", formula = y ~ x,
se = TRUE, n = 80, span = 0.75, fullrange = FALSE, level = 0.95,
method.args = list(), na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE)
```
V novějších verzích `ggplot2` se však již dají zpravidla předávat hodnoty parametrů pro `stat_*()` prostřednictvím `...` v `geom_*()`. Tato možnost prakticky eliminuje potřebu volat `stat_*()` funkce přímo kvůli nastavení statistických transformací.
Druhý důvod pro přímé použití `stat_*()` funkce však stále trvá. V některých případech můžete potřebovat použít pro vyreslení transformace netypický geom. Příkladem může být například zobrazování jádrové hustoty rozdělení dvou proměnných nikoliv pomocí vrstevnic (standardní zobrazení), ale pomocí barevných polygonů. (Výsledkem by byly například barevné plochy s barvou sytější tam, kde je odhadnuta vyšší hustota.) Tyto úlohy jsou však bezpochyby z kapitoly pro pokročilé.
## Pozicování
V `ggplotu2` existuje hned několik způsobů, jak je možné ovlivnit pozici vykresleného geomu (tj. geometrického objektu reprezentujícího data) na stránce. První možností bylo použití škál -- například jejich logaritmická transformace.
`ggplot2` však v tomto ohledu nabízí mnohem více možností. Místem kde začít hledat je parametr `position` ve funkci `layer()`. Smyslem jeho použití je předejít překryvu pozorování ve výsledném obrázku. Parametr může nabývat následujících hodnot:
- `identity`...je základní volba pro většinu funkcí `geom_*()`. Prakticky znamená, že z hlediska modifikace pozice geomu předává instrukci "nedělej nic a kresli na skutečnou pozici".
- `jitter`...ke skutečné pozici přidává náhodnou chybu
- `dodge`...geomy skládá vedle sebe
- `stack`...staví komínky -- skládá geomy nad sebe
- `nudge`...u překrývajících se geomů přidává ke skutečné pozici definovanou vzdálenost na ose `x` a `y`
- `jitterdodge`...kombinuje `jitter` a `dodge`
V následujícím textu jsou blíže ukázány nejčastěji používané varianty změny pozic: `jitter`, `dodge`, `stack` a navíc poněkud specifická varianta `fill`. Varianty `nudge` a `jitterdodge` jsou specifické pro určité méně geomy a jejich přímé volání je v podstatě výjimečné.
### `jitter`
`position = "jitter"` je populární volba zejména u bodových grafů, ve kterých je velký problém s overplottingem. Toto použití je tak typické, že existuje dokonce speciální `geom_*()` funkce: `geom_jitter()`. Ta je ekvivalentní k `geom_point(position = "jitter")`.
`geom_jitter()` přidává ke skutečné pozici pozorování náhodnou složku, která je generovaná z uniformního rozdělení:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_jitter(color = "red") +
geom_point()
```
Tato nejednoznačnost vymezení toho, co vlastně dělá `stat_*()` a co `geom_*()` je velmi otravnou nedokonalostí v návrhu `ggplot2` (a v `ggvis` je již vyřešena). Pokud není nevyhnutelné volat přímo `stat_*()` nutné, je lepší vždy používat funkce `geom_*()`.
Pro přímé volání `stat_*()` existovaly v podstatě dva důvody:
1. potřeba specifických nastavení statistických transformací
1. potřeba použití jiného než standardního geomu pro vykreslení statistické transformace
Pohledem do nápovědy zjistíte, že `stat_smooth()` umožňuje mnohem více nastavení vyhlazování:
```r
geom_smooth(mapping = NULL, data = NULL, stat = "smooth",
position = "identity", ..., method = "auto", formula = y ~ x,
se = TRUE, na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)
stat_smooth(mapping = NULL, data = NULL, geom = "smooth",
position = "identity", ..., method = "auto", formula = y ~ x,
se = TRUE, n = 80, span = 0.75, fullrange = FALSE, level = 0.95,
method.args = list(), na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE)
```
V novějších verzích `ggplot2` se však již dají zpravidla předávat hodnoty parametrů pro `stat_*()` prostřednictvím `...` v `geom_*()`. Tato možnost prakticky eliminuje potřebu volat `stat_*()` funkce přímo kvůli nastavení statistických transformací.
Druhý důvod pro přímé použití `stat_*()` funkce však stále trvá. V některých případech můžete potřebovat použít pro vyreslení transformace netypický geom. Příkladem může být například zobrazování jádrové hustoty rozdělení dvou proměnných nikoliv pomocí vrstevnic (standardní zobrazení), ale pomocí barevných polygonů. (Výsledkem by byly například barevné plochy s barvou sytější tam, kde je odhadnuta vyšší hustota.) Tyto úlohy jsou však bezpochyby z kapitoly pro pokročilé.
## Pozicování
V `ggplotu2` existuje hned několik způsobů, jak je možné ovlivnit pozici vykresleného geomu (tj. geometrického objektu reprezentujícího data) na stránce. První možností bylo použití škál -- například jejich logaritmická transformace.
`ggplot2` však v tomto ohledu nabízí mnohem více možností. Místem kde začít hledat je parametr `position` ve funkci `layer()`. Smyslem jeho použití je předejít překryvu pozorování ve výsledném obrázku. Parametr může nabývat následujících hodnot:
- `identity`...je základní volba pro většinu funkcí `geom_*()`. Prakticky znamená, že z hlediska modifikace pozice geomu předává instrukci "nedělej nic a kresli na skutečnou pozici".
- `jitter`...ke skutečné pozici přidává náhodnou chybu
- `dodge`...geomy skládá vedle sebe
- `stack`...staví komínky -- skládá geomy nad sebe
- `nudge`...u překrývajících se geomů přidává ke skutečné pozici definovanou vzdálenost na ose `x` a `y`
- `jitterdodge`...kombinuje `jitter` a `dodge`
V následujícím textu jsou blíže ukázány nejčastěji používané varianty změny pozic: `jitter`, `dodge`, `stack` a navíc poněkud specifická varianta `fill`. Varianty `nudge` a `jitterdodge` jsou specifické pro určité méně geomy a jejich přímé volání je v podstatě výjimečné.
### `jitter`
`position = "jitter"` je populární volba zejména u bodových grafů, ve kterých je velký problém s overplottingem. Toto použití je tak typické, že existuje dokonce speciální `geom_*()` funkce: `geom_jitter()`. Ta je ekvivalentní k `geom_point(position = "jitter")`.
`geom_jitter()` přidává ke skutečné pozici pozorování náhodnou složku, která je generovaná z uniformního rozdělení:
```r
xtable %>%
ggplot(
aes(x = x, y = y)
) +
geom_jitter(color = "red") +
geom_point()
```
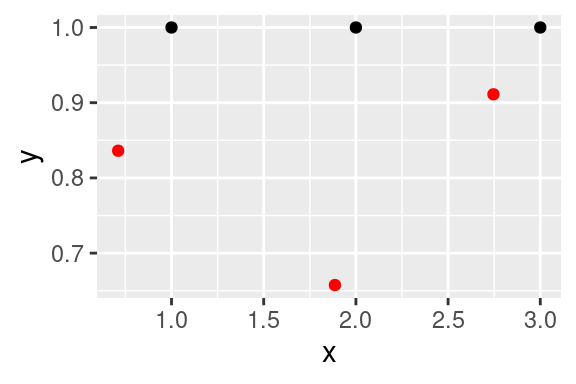 V obrátku vidíte skutečnou pozici pozorování vykreslenou pomocí `geom_point()` a červené tečky ukazující posunuté hodnoty vykreslené pomocí `geom_jitter()`. Protože je chyba náhodná, bude obrázek při každém vykreslení vypadat jinak.
Pomocí parametrů `width` a `height` je možná nastavit šířku a výšku obdélníku, ve kterém se posunutá pozorování budou nacházet. Protože se náhodná složka generuje z uniformního rozdělení, je každý posun stejně pravděpodobný. Skutečná pozorovaná hodnota je pak právě ve středu obdélníku. To ilustruje následující obrázek:
```r
xtable2 <- data_frame(
x = rep(1:2,1000),
y = rep(1:2,1000)
)
```
```r
xtable2 %>%
ggplot(
aes(x = x, y = y)
) +
geom_jitter(
alpha = 0.05,
color = "red"
) +
geom_point()
```
V obrátku vidíte skutečnou pozici pozorování vykreslenou pomocí `geom_point()` a červené tečky ukazující posunuté hodnoty vykreslené pomocí `geom_jitter()`. Protože je chyba náhodná, bude obrázek při každém vykreslení vypadat jinak.
Pomocí parametrů `width` a `height` je možná nastavit šířku a výšku obdélníku, ve kterém se posunutá pozorování budou nacházet. Protože se náhodná složka generuje z uniformního rozdělení, je každý posun stejně pravděpodobný. Skutečná pozorovaná hodnota je pak právě ve středu obdélníku. To ilustruje následující obrázek:
```r
xtable2 <- data_frame(
x = rep(1:2,1000),
y = rep(1:2,1000)
)
```
```r
xtable2 %>%
ggplot(
aes(x = x, y = y)
) +
geom_jitter(
alpha = 0.05,
color = "red"
) +
geom_point()
```
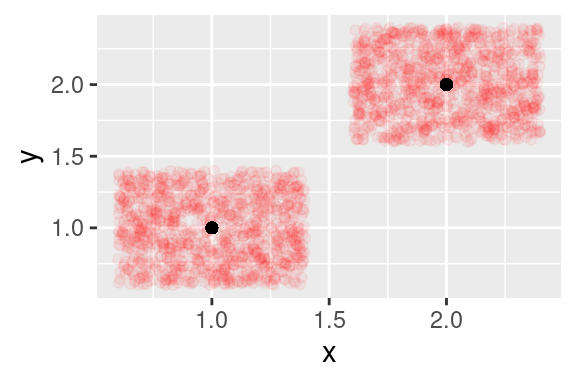 Posunutá pozorování (červené tečky) tvoří mračno rovnoměrně vyplňující celý obdélník za pozorovanou hodnotou (černá tečka), která je přesně v jeho středu.
### `stack`
Typické použití této změny této modifikace pozice je u sloupcových grafů. Ty se v `ggplot2` tvoří pomocí `geom_bar()` a jejich základní nestavení je, že mají být použity k vykreslení rozdělení diskrétní proměnné.
Pro použití `geom_bar()` vytvoříme novou tabulku `occupation`:
```r
occupation <- data_frame(
sex = rep(c("male","female"),100),
occupation = sample(c("A","B","C","D"), 200, replace = TRUE, prob = abs(rnorm(4))),
age = sample(c("old","young"), 200, replace = TRUE)
)
```
Tabulka obsahuje povolání (A, B, C nebo D), pohlaví a věkovou kohortu 200 lidí. Zajímá nás rozdělení povolání ve vzorku:
```r
occupation %>%
ggplot(
aes(x = occupation)
) +
geom_bar()
```
Posunutá pozorování (červené tečky) tvoří mračno rovnoměrně vyplňující celý obdélník za pozorovanou hodnotou (černá tečka), která je přesně v jeho středu.
### `stack`
Typické použití této změny této modifikace pozice je u sloupcových grafů. Ty se v `ggplot2` tvoří pomocí `geom_bar()` a jejich základní nestavení je, že mají být použity k vykreslení rozdělení diskrétní proměnné.
Pro použití `geom_bar()` vytvoříme novou tabulku `occupation`:
```r
occupation <- data_frame(
sex = rep(c("male","female"),100),
occupation = sample(c("A","B","C","D"), 200, replace = TRUE, prob = abs(rnorm(4))),
age = sample(c("old","young"), 200, replace = TRUE)
)
```
Tabulka obsahuje povolání (A, B, C nebo D), pohlaví a věkovou kohortu 200 lidí. Zajímá nás rozdělení povolání ve vzorku:
```r
occupation %>%
ggplot(
aes(x = occupation)
) +
geom_bar()
```
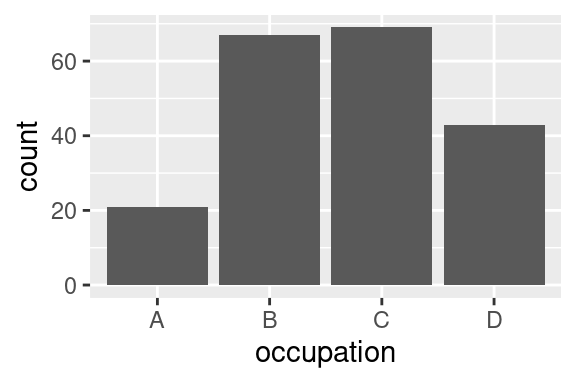 `geom_bar()` v základním nastavení, tedy se `stat = "count"`, provádí statistickou transformaci dat. Zjistí absolutní četnost jednotlivých variant proměnné v estetice `x` a tyto četnosti následně vykreslí formou sloupcového grafu.
Obrázek momentálně nijak nezohledňuje pohlaví, ale to se dá změnit. Lze ho namapovat například (a typicky) na estetiku `fill`:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar()
```
`geom_bar()` v základním nastavení, tedy se `stat = "count"`, provádí statistickou transformaci dat. Zjistí absolutní četnost jednotlivých variant proměnné v estetice `x` a tyto četnosti následně vykreslí formou sloupcového grafu.
Obrázek momentálně nijak nezohledňuje pohlaví, ale to se dá změnit. Lze ho namapovat například (a typicky) na estetiku `fill`:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar()
```
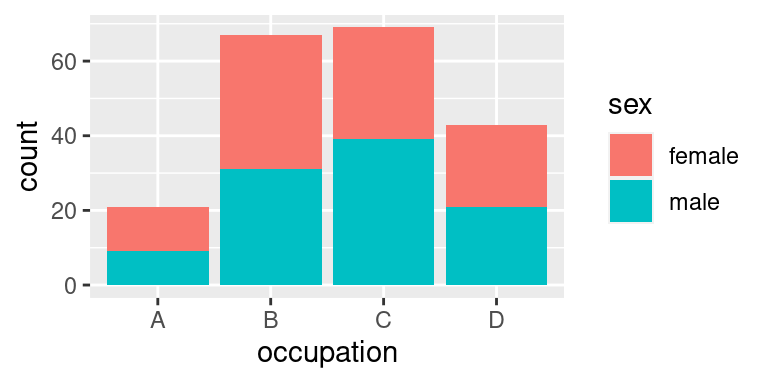 Ve výsledku dodá statistická transformace provedená `stat_count()` pro každé povolání dvě hodnoty: počet mužů a počet žen. Ty by se v logicky měly kreslit přes sebe -- patří v obrázku na jedno místo. Očekávali bychom tedy tento obrázek:
Ve výsledku dodá statistická transformace provedená `stat_count()` pro každé povolání dvě hodnoty: počet mužů a počet žen. Ty by se v logicky měly kreslit přes sebe -- patří v obrázku na jedno místo. Očekávali bychom tedy tento obrázek:
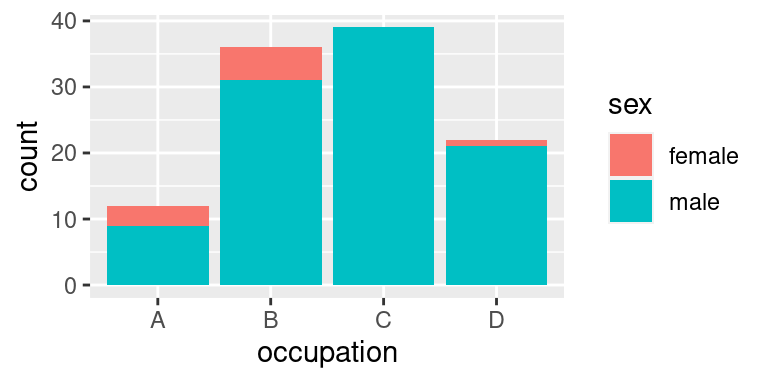 Takový obrázek však není příliš užitečný, protože poskytuje spolehlivou informaci pouze o maximálních hodnotách. Proto již v základním nastavení `geom_bar()` používá `position = "stack`, která počet žen a mužů postaví nad sebe -- do jednoho komínku.
Poznámka: "Špatný" obrázek můžete vykreslit s `geom_bar(position = "identity)`.
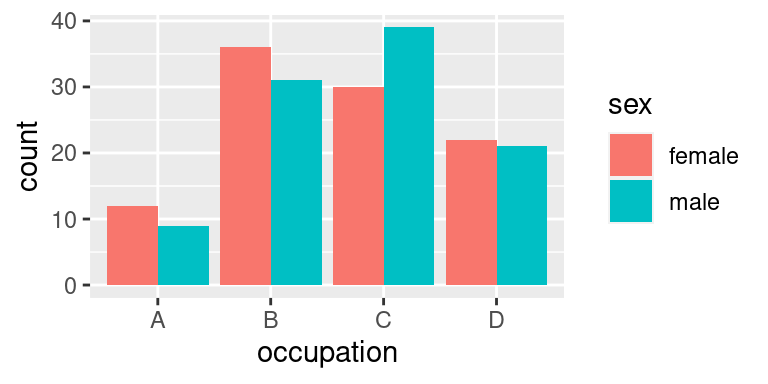
### `dodge`
Dalším typickým řešením u sloupcových grafů je vykreslení hodnot vedle sebe. Tento způsob čtenáři lépe předává informaci o počtu mužů a žen napříč povoláními. Horizontální posunutí sloupců zajišťuje `position = "dodge"`:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar(position = "dodge")
```
Takový obrázek však není příliš užitečný, protože poskytuje spolehlivou informaci pouze o maximálních hodnotách. Proto již v základním nastavení `geom_bar()` používá `position = "stack`, která počet žen a mužů postaví nad sebe -- do jednoho komínku.
Poznámka: "Špatný" obrázek můžete vykreslit s `geom_bar(position = "identity)`.
### `dodge`
Dalším typickým řešením u sloupcových grafů je vykreslení hodnot vedle sebe. Tento způsob čtenáři lépe předává informaci o počtu mužů a žen napříč povoláními. Horizontální posunutí sloupců zajišťuje `position = "dodge"`:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar(position = "dodge")
```
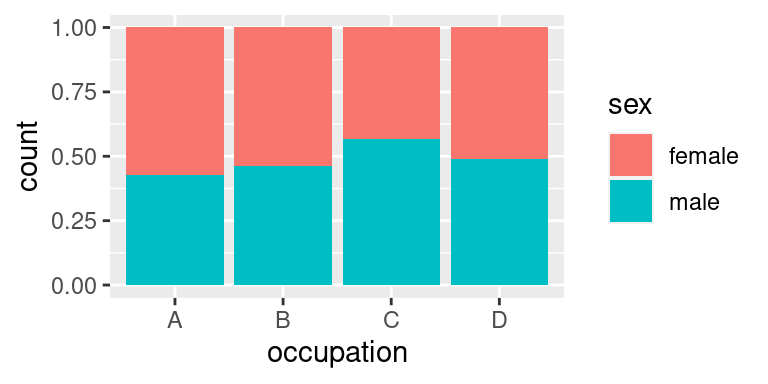
 ### `fill`
Poněkud specifickou úpravou pozice je `fill`, která upravuje nejen pozici, ale vlastně provádí i další statistickou transformaci. Nevrací totiž absolutní, ale relativní četnost:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar(position = "fill")
```
### `fill`
Poněkud specifickou úpravou pozice je `fill`, která upravuje nejen pozici, ale vlastně provádí i další statistickou transformaci. Nevrací totiž absolutní, ale relativní četnost:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar(position = "fill")
```
 ### Facetování: na půli cesty mezi grupováním a pozicováním
Výše popsané pozicování mělo pozici geomů vlastně v rámci jednoho obrázku. Facetování k problému přistupuje jinak -- rozlamuje původně jeden obrázek na více dílčích obrázků (facet). `ggplot2` umožňuje vytvářet buď matice dílčích obrázků pomocí `facet_grid()` nebo prosté rozlomení do více obrázků pomocí `facet_wrap()`.
Nejjednodušší příklad je použití `facet_wrap()`. Řekněme, že budeme chtít rozdělit obrázek s rozdělením povolání podle pohlaví:
```r
occupation %>%
ggplot(
aes(x = occupation)
) +
geom_bar() -> p
p + facet_wrap("sex")
```
### Facetování: na půli cesty mezi grupováním a pozicováním
Výše popsané pozicování mělo pozici geomů vlastně v rámci jednoho obrázku. Facetování k problému přistupuje jinak -- rozlamuje původně jeden obrázek na více dílčích obrázků (facet). `ggplot2` umožňuje vytvářet buď matice dílčích obrázků pomocí `facet_grid()` nebo prosté rozlomení do více obrázků pomocí `facet_wrap()`.
Nejjednodušší příklad je použití `facet_wrap()`. Řekněme, že budeme chtít rozdělit obrázek s rozdělením povolání podle pohlaví:
```r
occupation %>%
ggplot(
aes(x = occupation)
) +
geom_bar() -> p
p + facet_wrap("sex")
```
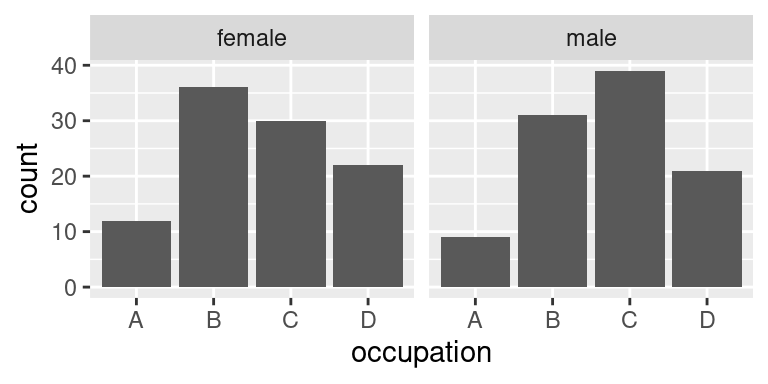 `facet_wrap()` rozdělil celkový obrázek na dva dílčí podle hodnot proměnné `sex`. Ta je v příkladu určena svým jménem (*character*). Další možností je její určení pomocí jednostranné rovnice (*formula*, blíže viz přednáška o ekonometrii v R):
```r
p + facet_wrap(~ sex)
```
Vytvářet dílčí obrázky lze i podle kombinace více proměnných -- můžeme chtít například samostatné dílčí obrázky pro kombinaci pohlaví a věku. V tomto případě se pro specifikaci proměnných použije vektor jejich jmen:
```r
p + facet_wrap(c("sex","age"))
```
`facet_wrap()` rozdělil celkový obrázek na dva dílčí podle hodnot proměnné `sex`. Ta je v příkladu určena svým jménem (*character*). Další možností je její určení pomocí jednostranné rovnice (*formula*, blíže viz přednáška o ekonometrii v R):
```r
p + facet_wrap(~ sex)
```
Vytvářet dílčí obrázky lze i podle kombinace více proměnných -- můžeme chtít například samostatné dílčí obrázky pro kombinaci pohlaví a věku. V tomto případě se pro specifikaci proměnných použije vektor jejich jmen:
```r
p + facet_wrap(c("sex","age"))
```
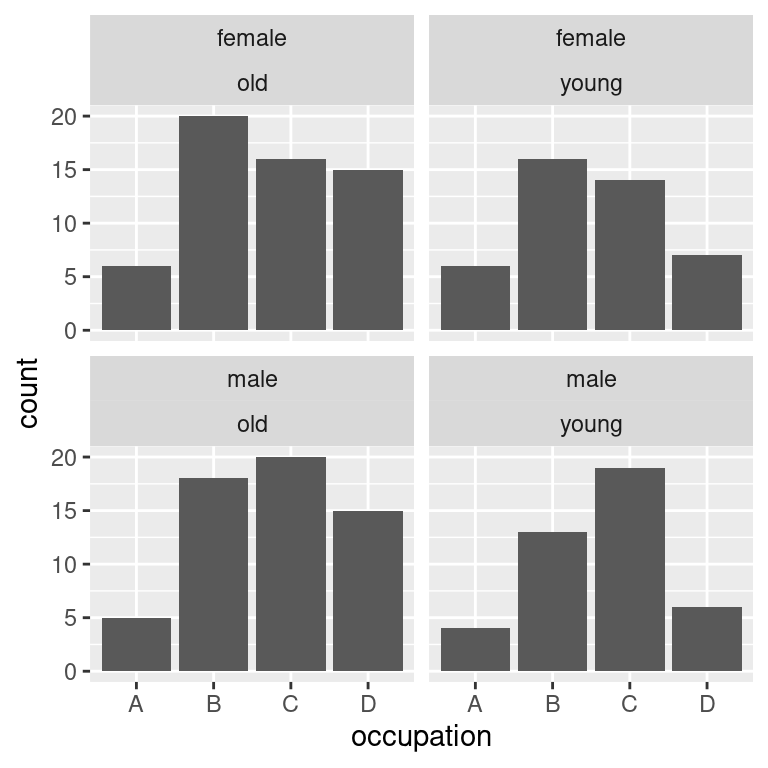 Nebo alternativně:
```r
p + facet_wrap(~ sex + age)
```
Použít pro tyto aplikace `facet_wrap()` je možné, ale často je vhodnější sáhnout po `facet_grid()`, který je přímo navržen pro rozlomení obrázku podle kombinace více proměnných. `facet_grid()` vyžaduje specifikaci facetování pomocí objektu třídy `formula`:
```r
p + facet_grid(sex ~ age)
```
Nebo alternativně:
```r
p + facet_wrap(~ sex + age)
```
Použít pro tyto aplikace `facet_wrap()` je možné, ale často je vhodnější sáhnout po `facet_grid()`, který je přímo navržen pro rozlomení obrázku podle kombinace více proměnných. `facet_grid()` vyžaduje specifikaci facetování pomocí objektu třídy `formula`:
```r
p + facet_grid(sex ~ age)
```
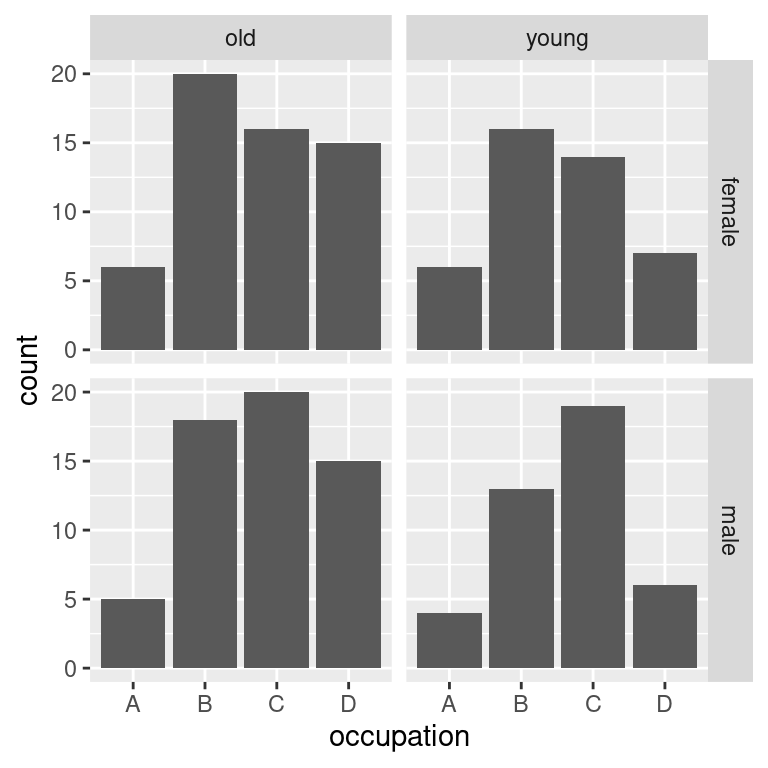 Na levé straně rovnice (na levé straně `~`) je proměnná (nebo jejich kombinace spojená `+`), která má tvořit řádky a na levé straně je proměnná nebo jejich kombinace, která má tvořit sloupce.
Funkce vytvářející facetování mají i další užitečné parametry. Pro `facet_wrap()` jsou specifické parametry `ncol` a `nrow`, které určují formát výstupní tabulky dílčích obrázků -- kolik má mít sloupců a kolik řádků. Stačí přitom zadat jen jeden z těchto parametrů:
```r
p + facet_wrap(c("sex","age"), nrow = 1)
```
Na levé straně rovnice (na levé straně `~`) je proměnná (nebo jejich kombinace spojená `+`), která má tvořit řádky a na levé straně je proměnná nebo jejich kombinace, která má tvořit sloupce.
Funkce vytvářející facetování mají i další užitečné parametry. Pro `facet_wrap()` jsou specifické parametry `ncol` a `nrow`, které určují formát výstupní tabulky dílčích obrázků -- kolik má mít sloupců a kolik řádků. Stačí přitom zadat jen jeden z těchto parametrů:
```r
p + facet_wrap(c("sex","age"), nrow = 1)
```
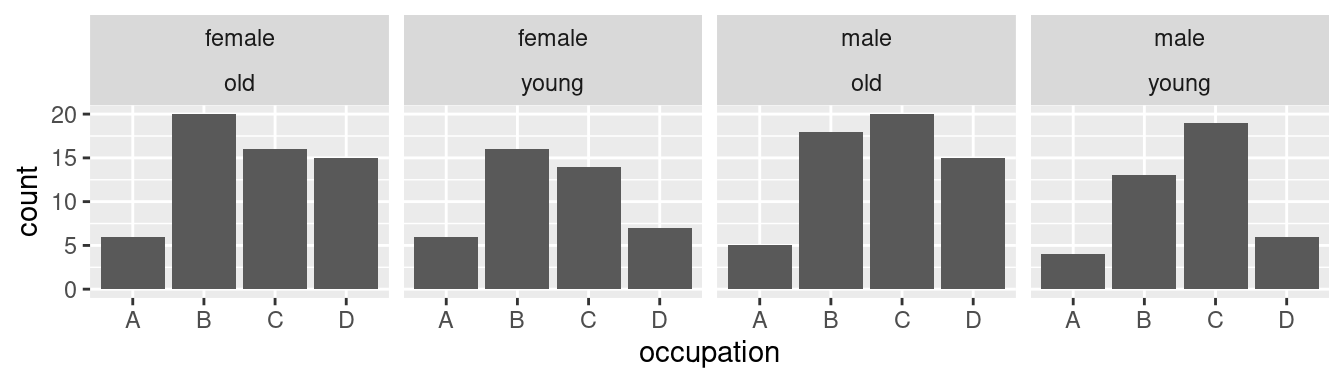 Užitečný, ale pro správné čtení dat velmi ošemetný, parametr je `scales`. Ten umožňuje uvolnit škály v jednotlivých dílčích obrázcích. Základní hodnotou je `fixed`. V tomto případě jsou měřítka na všech dílčích obrázcích stejná. Varianty `free`, `free_y` a `free_x` umožňují uvolnit měřítka na všech osách nebo jen na ose `x` popřípadě `y`:
```r
p + facet_wrap(c("sex","age"), nrow = 1, scales = "free_y")
```
Užitečný, ale pro správné čtení dat velmi ošemetný, parametr je `scales`. Ten umožňuje uvolnit škály v jednotlivých dílčích obrázcích. Základní hodnotou je `fixed`. V tomto případě jsou měřítka na všech dílčích obrázcích stejná. Varianty `free`, `free_y` a `free_x` umožňují uvolnit měřítka na všech osách nebo jen na ose `x` popřípadě `y`:
```r
p + facet_wrap(c("sex","age"), nrow = 1, scales = "free_y")
```
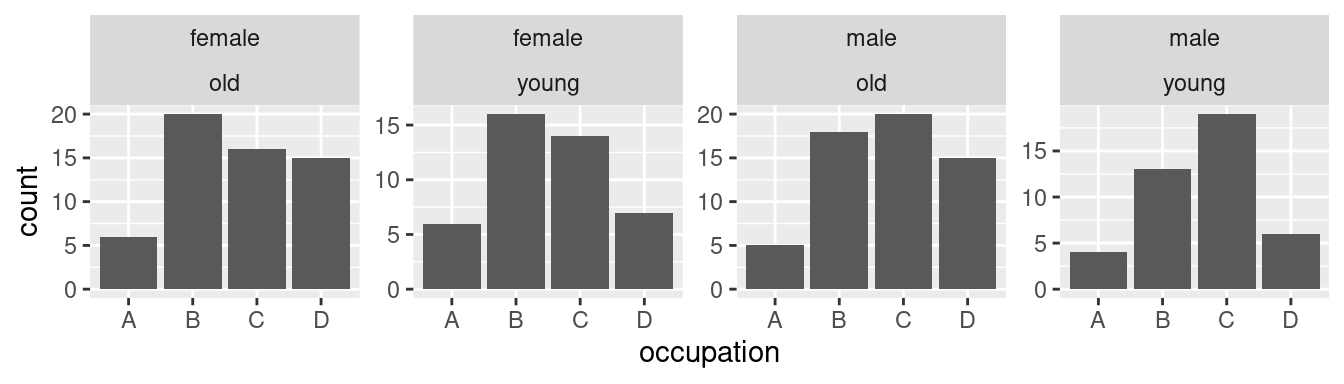 Příklad ilustruje, že uvolnění os může být pro čtenáře velmi zavádějící. Stejná výška sloupce totiž v různých dílčích obrázcích znamená jinou pozorovanou hodnotu.
## Souřadnicové systémy
*ggplot2* podporuje řadu souřadnicových systémů. Základní volbou je lineární `coord_cartesian()`, ale podporovány jsou i nelineární souřadnicové systémy, které se ovšem používají pouze ve velmi specifických případech jako je například vykreslování map (`coord_map()`). Dalším příkladem nelineárního systému je `coord_polar()`.
Základní volbou aplikovanou v téměř všech voláních *ggplot2* je bezpochyby lineární systém, ve kterém je pozice prvků určena jejich souřadnicemi na ose `x` a `y`. Základní funkcí je `coord_cartesian()`, ale *ggplot2* obsahuje i její různé mutace a transformace:
- `coord_fixed()` udržuje konstantní zadaný poměr stran.
- `coord_equal()` je zkratka pro `coord_fixed()` s poměrem stran 1.
- `coord_flip()` prohazuje osy `x` a `y`.
- `coord_trans()` umožňuje provést transformaci os.
- `coord_sf()` je speciální funkce pro práci s mapami.
Fungování `coord_flip()` je možné ilustrovat pomocí jednoduchého bodového grafu. V definici mapování je váha (`carat`) namapována na osu `x` a cena na osu `y`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() -> p
```
Použití `coord_flip()` prohodí osy `x` a `y` -- výsledek tedy odpovídá použití `aes(y = carat, x = price)`:
```r
p + coord_flip()
```
Příklad ilustruje, že uvolnění os může být pro čtenáře velmi zavádějící. Stejná výška sloupce totiž v různých dílčích obrázcích znamená jinou pozorovanou hodnotu.
## Souřadnicové systémy
*ggplot2* podporuje řadu souřadnicových systémů. Základní volbou je lineární `coord_cartesian()`, ale podporovány jsou i nelineární souřadnicové systémy, které se ovšem používají pouze ve velmi specifických případech jako je například vykreslování map (`coord_map()`). Dalším příkladem nelineárního systému je `coord_polar()`.
Základní volbou aplikovanou v téměř všech voláních *ggplot2* je bezpochyby lineární systém, ve kterém je pozice prvků určena jejich souřadnicemi na ose `x` a `y`. Základní funkcí je `coord_cartesian()`, ale *ggplot2* obsahuje i její různé mutace a transformace:
- `coord_fixed()` udržuje konstantní zadaný poměr stran.
- `coord_equal()` je zkratka pro `coord_fixed()` s poměrem stran 1.
- `coord_flip()` prohazuje osy `x` a `y`.
- `coord_trans()` umožňuje provést transformaci os.
- `coord_sf()` je speciální funkce pro práci s mapami.
Fungování `coord_flip()` je možné ilustrovat pomocí jednoduchého bodového grafu. V definici mapování je váha (`carat`) namapována na osu `x` a cena na osu `y`:
```r
diamonds %>%
ggplot(
aes(x = carat, y = price)
) +
geom_point() -> p
```
Použití `coord_flip()` prohodí osy `x` a `y` -- výsledek tedy odpovídá použití `aes(y = carat, x = price)`:
```r
p + coord_flip()
```
 `coord_flip()` je užitečné u některých specifických geomů -- například u boxplotů, která zobrazují základní charakteristiky rozdělení spojité proměnné.
`coord_trans()` umožňuje transformovat osy podobným způsobem jako `scale_*_*()` funkce. Stejně jako ostatní funkce odvozené od `coord_cartesian()` umožňuje nastavit interval zobrazený na osách. Podobnou možnost mají opět i `scale_*_*()` funkce.
Nabízí se tedy otázka, na co jsou vlastně funkce `coord_*()` užitečné. Pro demonstraci odpovědi nasimulujeme velmi specifickou tabulku:
```r
cltable <- data_frame(
x = c(
rnorm(300, sd = 2),
rnorm(40, sd = 0.5) + 10
),
y = c(
rnorm(300, sd = 1),
rnorm(40, sd = 0.5) + 5
)
)
cltable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) -> p
p
```
`coord_flip()` je užitečné u některých specifických geomů -- například u boxplotů, která zobrazují základní charakteristiky rozdělení spojité proměnné.
`coord_trans()` umožňuje transformovat osy podobným způsobem jako `scale_*_*()` funkce. Stejně jako ostatní funkce odvozené od `coord_cartesian()` umožňuje nastavit interval zobrazený na osách. Podobnou možnost mají opět i `scale_*_*()` funkce.
Nabízí se tedy otázka, na co jsou vlastně funkce `coord_*()` užitečné. Pro demonstraci odpovědi nasimulujeme velmi specifickou tabulku:
```r
cltable <- data_frame(
x = c(
rnorm(300, sd = 2),
rnorm(40, sd = 0.5) + 10
),
y = c(
rnorm(300, sd = 1),
rnorm(40, sd = 0.5) + 5
)
)
cltable %>%
ggplot(
aes(x = x, y = y)
) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) -> p
p
```
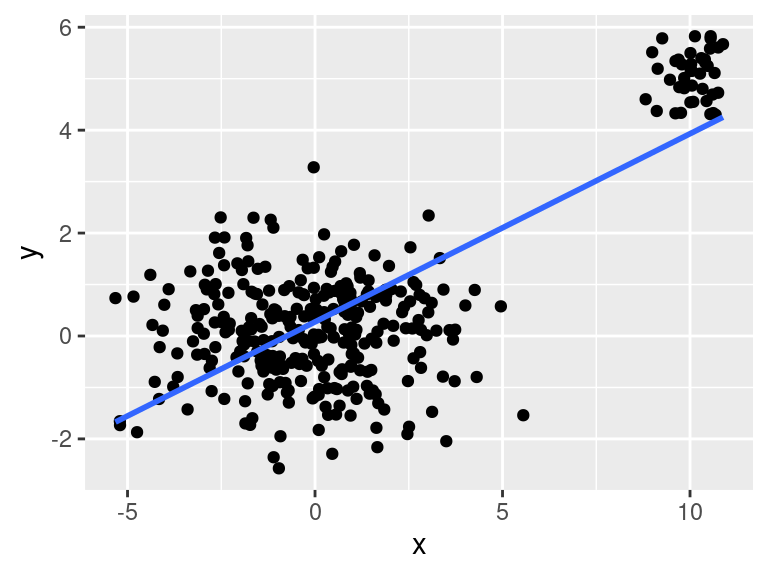 Simulovaná data obsahují dva shluky pozorování. Pokud je proložíme regresní přímkou (tj. vykreslíme statistickou transformaci dat) získáme (falešné) zdání existence rostoucího vztahu mezi veličinou na ose `x` a na ose `y`.
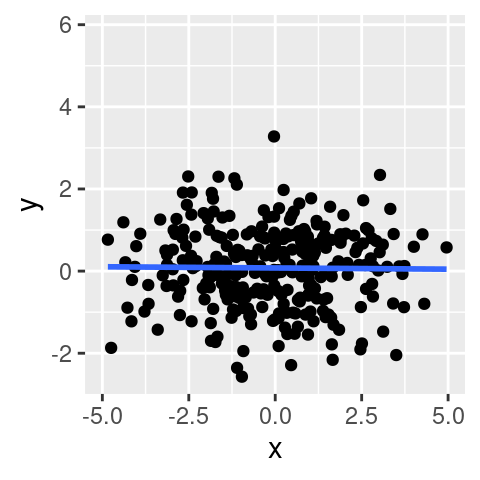
Řekněme, že z nějakých důvodů budeme chtít omezit zobrazené hodnoty na ose `x` na interval $[-5,5]$. To lez provést buď pomocí funkcí `scale_x_*()` nebo `coord_*()`:
```r
p + scale_x_continuous(limits = c(-5,5))
```
Simulovaná data obsahují dva shluky pozorování. Pokud je proložíme regresní přímkou (tj. vykreslíme statistickou transformaci dat) získáme (falešné) zdání existence rostoucího vztahu mezi veličinou na ose `x` a na ose `y`.
Řekněme, že z nějakých důvodů budeme chtít omezit zobrazené hodnoty na ose `x` na interval $[-5,5]$. To lez provést buď pomocí funkcí `scale_x_*()` nebo `coord_*()`:
```r
p + scale_x_continuous(limits = c(-5,5))
```
 ```r
p + coord_cartesian(xlim = c(-5,5))
```
```r
p + coord_cartesian(xlim = c(-5,5))
```
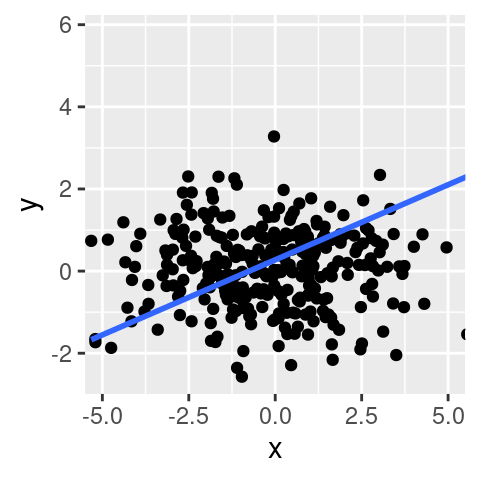 Rozdíl je zjevný. Při použití `scale_x_*()` je regresní přímka prakticky vodorovná. Naopak při použití `coord_*()` je stále rostoucí. Rozdíl je v tom, kdy je aplikované statistická transformace (v tomto případě vyhlazení). Při použití `scale_*_*()` funkce je nejprve omezen rozsah dat a následně je aplikována transformace. Výsledek tak může být zavádějící. Naproti tomu při použití `coord_*()` je nejprve aplikována transformace a následně je omezen rozsah zobrazených dat. Transformace tak reflektuje i ta pozorování, která nejsou zobrazená.
`coord_*()` tak nabízí možnost skutečně "zazoomovat" část obrázku, aniž by to ovlivnilo obrázek samotný.
## Vzhled obrázků
Vzhled obrázků, nebo přesněji prvky, které nemají vztah k datům se v *ggplot2* ovládají pomocí funkce `theme()`. Ta umožňuje změnit vzhled obrázků k nepoznání: můžete mít obrázek, který vypadá, jako by byl vytvořen v Excelu, Stata, nebo jako by vyšel v The Economist.
Funkce `theme()` má obrovské množství parametrů a nebylo by praktické je nastavovat vždy u každého obrázku. Proto v *ggplot2* existuje řada předpřipravených kompletních témat (vzhledů). Například `theme_bw()`, `theme_classic()` nebo `theme_void()`. Základní vzhled obrázků potom odpovídá `theme_gray()`. Nápověda *ggplot2* obsahuje hrubá doporučení, kdy je vhodné použít které téma.
### Ukázky předpřipravených témat
Pro ukázky použijeme již známý sloupcový graf:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar() -> p
```
Populární téma je `theme_bw()`, které *ggplot2* doporučuje například pro prezentace:
```r
p + theme_bw()
```
Rozdíl je zjevný. Při použití `scale_x_*()` je regresní přímka prakticky vodorovná. Naopak při použití `coord_*()` je stále rostoucí. Rozdíl je v tom, kdy je aplikované statistická transformace (v tomto případě vyhlazení). Při použití `scale_*_*()` funkce je nejprve omezen rozsah dat a následně je aplikována transformace. Výsledek tak může být zavádějící. Naproti tomu při použití `coord_*()` je nejprve aplikována transformace a následně je omezen rozsah zobrazených dat. Transformace tak reflektuje i ta pozorování, která nejsou zobrazená.
`coord_*()` tak nabízí možnost skutečně "zazoomovat" část obrázku, aniž by to ovlivnilo obrázek samotný.
## Vzhled obrázků
Vzhled obrázků, nebo přesněji prvky, které nemají vztah k datům se v *ggplot2* ovládají pomocí funkce `theme()`. Ta umožňuje změnit vzhled obrázků k nepoznání: můžete mít obrázek, který vypadá, jako by byl vytvořen v Excelu, Stata, nebo jako by vyšel v The Economist.
Funkce `theme()` má obrovské množství parametrů a nebylo by praktické je nastavovat vždy u každého obrázku. Proto v *ggplot2* existuje řada předpřipravených kompletních témat (vzhledů). Například `theme_bw()`, `theme_classic()` nebo `theme_void()`. Základní vzhled obrázků potom odpovídá `theme_gray()`. Nápověda *ggplot2* obsahuje hrubá doporučení, kdy je vhodné použít které téma.
### Ukázky předpřipravených témat
Pro ukázky použijeme již známý sloupcový graf:
```r
occupation %>%
ggplot(
aes(x = occupation, fill = sex)
) +
geom_bar() -> p
```
Populární téma je `theme_bw()`, které *ggplot2* doporučuje například pro prezentace:
```r
p + theme_bw()
```
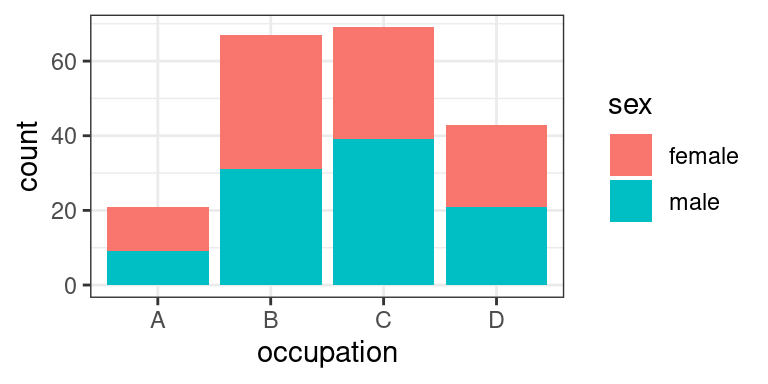 Klasicky vypadající téma s minimem čar je `theme_classic()`:
```r
p + theme_classic()
```
Klasicky vypadající téma s minimem čar je `theme_classic()`:
```r
p + theme_classic()
```
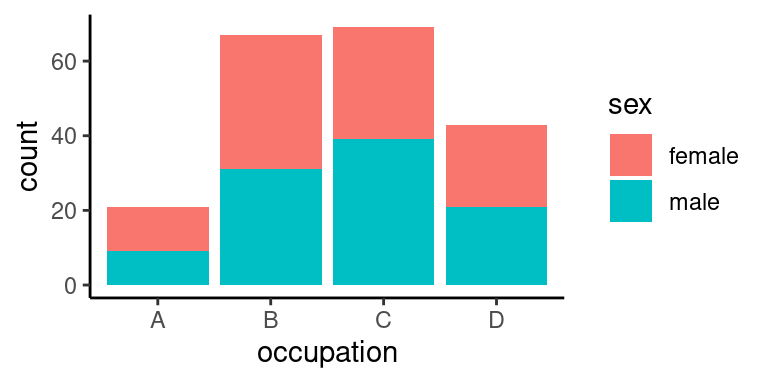 Například pro kreslení map oceníte velmi speciální téma `theme_void()`, které zahodí všechny čáry:
```r
p + theme_void()
```
Například pro kreslení map oceníte velmi speciální téma `theme_void()`, které zahodí všechny čáry:
```r
p + theme_void()
```
 Sbírku předpřipravených témat obsahuje například balík *ggthemes*. Kromě různých `theme_*()` obsahuje balík i řadu `scale_*_*()` a několik `geom_*()` funkcí.
Například minimalistické téma vytvořené podle Tufteho doporučení obsahuje `ggthemes::theme_tufte()`:
```r
p + ggthemes::theme_tufte()
```
Sbírku předpřipravených témat obsahuje například balík *ggthemes*. Kromě různých `theme_*()` obsahuje balík i řadu `scale_*_*()` a několik `geom_*()` funkcí.
Například minimalistické téma vytvořené podle Tufteho doporučení obsahuje `ggthemes::theme_tufte()`:
```r
p + ggthemes::theme_tufte()
```
 ### Modifikace témat
*ggplot2* umožňuje vytvářet vlastní předpřipravená témata, ale většinou bohatě postačuje použít předpřipravené a upravit ho, to lze zařídit následujícím způsobem:
```r
p +
theme_classic() +
theme(
panel.grid.major = element_line(size = 0.2)
)
```
### Modifikace témat
*ggplot2* umožňuje vytvářet vlastní předpřipravená témata, ale většinou bohatě postačuje použít předpřipravené a upravit ho, to lze zařídit následujícím způsobem:
```r
p +
theme_classic() +
theme(
panel.grid.major = element_line(size = 0.2)
)
```
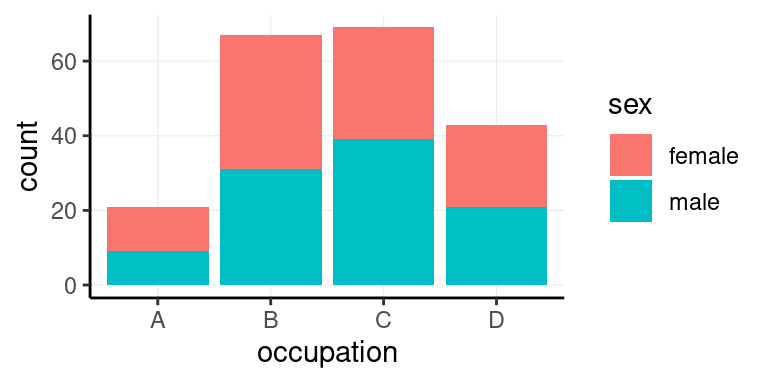 U `theme()` funguje vrstvení stejně, jako u všeho ostatního. Volání jednotlivých funkcí modifikuje podkladovou datovou strukturu. Zavolání funkce `theme_classic()` tedy nastaví všechny parametry tak, jak to odpovídá `theme_classic` -- to znamená, žádné linky na pozadí. Následné volání `theme()` přepíše to, co před tím nastavilo volání `theme_classic()` a linky přidá. Žádný další parametr nebyl v `theme()` zadán a proto se nic jiného nezmění.
Pokud by funkce byly volány v opačném pořadí, potom by byl výsledek následující:
```r
p +
theme(
panel.grid.major = element_line(size = 0.2)
) +
theme_classic()
```
U `theme()` funguje vrstvení stejně, jako u všeho ostatního. Volání jednotlivých funkcí modifikuje podkladovou datovou strukturu. Zavolání funkce `theme_classic()` tedy nastaví všechny parametry tak, jak to odpovídá `theme_classic` -- to znamená, žádné linky na pozadí. Následné volání `theme()` přepíše to, co před tím nastavilo volání `theme_classic()` a linky přidá. Žádný další parametr nebyl v `theme()` zadán a proto se nic jiného nezmění.
Pokud by funkce byly volány v opačném pořadí, potom by byl výsledek následující:
```r
p +
theme(
panel.grid.major = element_line(size = 0.2)
) +
theme_classic()
```
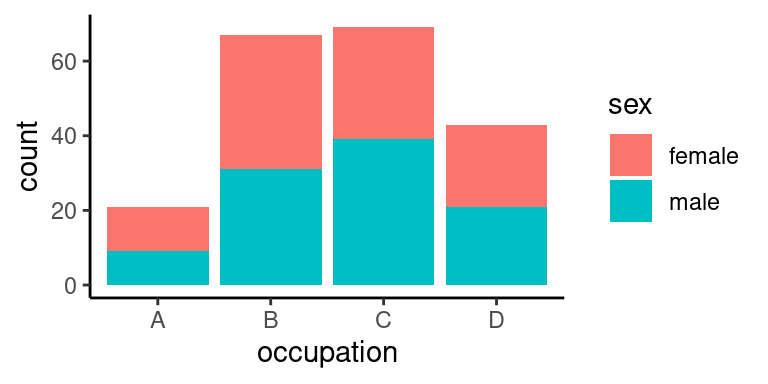 Výsledek by přesně odpovídal `theme_classic`. `theme_classic()` totiž bez milosti přepíše veškeré formátování vytvořené v předchozích voláních `theme()` nebo `theme_*()`.
Samotné volání `theme()` ve výše uvedeném příkladu vypadá skutečně velmi krypticky, ale není to tak, protože, podobně jako (skoro) ve všem v `ggplot2`, za ním stojí promyšlený systém.
Funkce `theme()` má opravdu mnoho parametrů (viz `?theme`), jejich jména odpovídají jménům jednotlivých grafických prvků. Jména jsou naštěstí často velmi výstižná, intuitivní, a navíc je RStudio zvládá (u novějších verzí *ggplot2*) našeptávat.
Formátování grafických prvků se ve většině případů provádí pomocí volání jedné z následujících funkcí:
```r
element_text(family = NULL, face = NULL, colour = NULL, size = NULL,
hjust = NULL, vjust = NULL, angle = NULL, lineheight = NULL,
color = NULL, margin = NULL, debug = NULL)
element_line(colour = NULL, size = NULL, linetype = NULL,
lineend = NULL, color = NULL)
element_rect(fill = NULL, colour = NULL, size = NULL, linetype = NULL,
color = NULL)
element_blank()
```
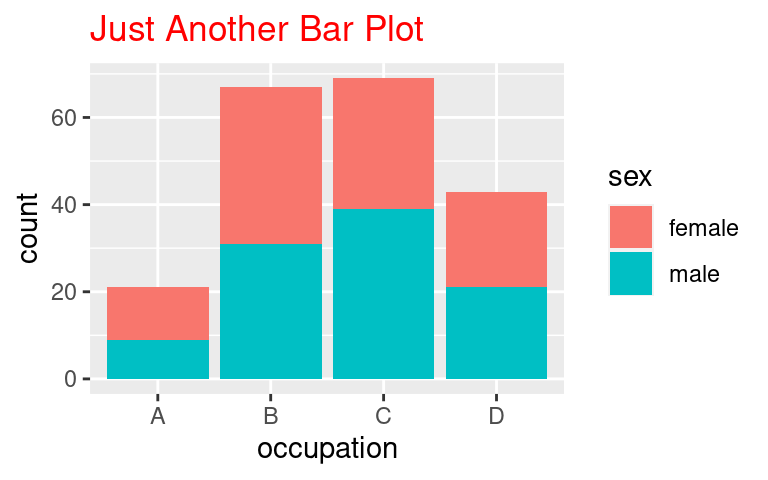
Tu správnou lze uhodnout. Pokud chcete upravit formátování prvku, který je ve své podstatě text, potom chcete použít `element_text()`. Příkladem může být modifikace titulku (`plot.title`) obrázku:
```r
p +
labs(
title = "Just Another Bar Plot"
) +
theme(
plot.title = element_text(colour = "red")
)
```
Výsledek by přesně odpovídal `theme_classic`. `theme_classic()` totiž bez milosti přepíše veškeré formátování vytvořené v předchozích voláních `theme()` nebo `theme_*()`.
Samotné volání `theme()` ve výše uvedeném příkladu vypadá skutečně velmi krypticky, ale není to tak, protože, podobně jako (skoro) ve všem v `ggplot2`, za ním stojí promyšlený systém.
Funkce `theme()` má opravdu mnoho parametrů (viz `?theme`), jejich jména odpovídají jménům jednotlivých grafických prvků. Jména jsou naštěstí často velmi výstižná, intuitivní, a navíc je RStudio zvládá (u novějších verzí *ggplot2*) našeptávat.
Formátování grafických prvků se ve většině případů provádí pomocí volání jedné z následujících funkcí:
```r
element_text(family = NULL, face = NULL, colour = NULL, size = NULL,
hjust = NULL, vjust = NULL, angle = NULL, lineheight = NULL,
color = NULL, margin = NULL, debug = NULL)
element_line(colour = NULL, size = NULL, linetype = NULL,
lineend = NULL, color = NULL)
element_rect(fill = NULL, colour = NULL, size = NULL, linetype = NULL,
color = NULL)
element_blank()
```
Tu správnou lze uhodnout. Pokud chcete upravit formátování prvku, který je ve své podstatě text, potom chcete použít `element_text()`. Příkladem může být modifikace titulku (`plot.title`) obrázku:
```r
p +
labs(
title = "Just Another Bar Plot"
) +
theme(
plot.title = element_text(colour = "red")
)
```
 Pokud je prvek svým charakterem čára, potom se jeho formátování nastavuje pomocí `element_line()` (viz modifikace čar na pozadí výše). Prvky, které jsou ve své podstatě čtyřúhelník se potom modifikují pomocí `element_rect()`. Příkladem může být změna barvy pozadí grafu na poníkovou:
```r
p +
theme(
panel.background = element_rect(fill = "pink")
)
```
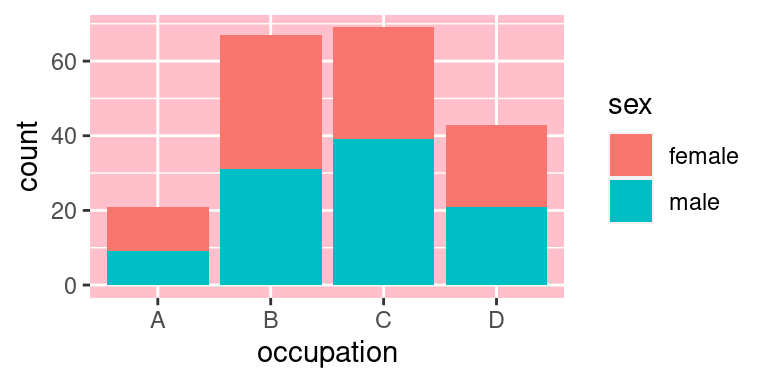
Pokud je prvek svým charakterem čára, potom se jeho formátování nastavuje pomocí `element_line()` (viz modifikace čar na pozadí výše). Prvky, které jsou ve své podstatě čtyřúhelník se potom modifikují pomocí `element_rect()`. Příkladem může být změna barvy pozadí grafu na poníkovou:
```r
p +
theme(
panel.background = element_rect(fill = "pink")
)
```
 Speciální funkce je potom `element_blank()`, která způsobí, že se daný prvek z obrázku kompletně vypustí:
```r
p +
theme(
legend.title = element_blank()
)
```
Speciální funkce je potom `element_blank()`, která způsobí, že se daný prvek z obrázku kompletně vypustí:
```r
p +
theme(
legend.title = element_blank()
)
```
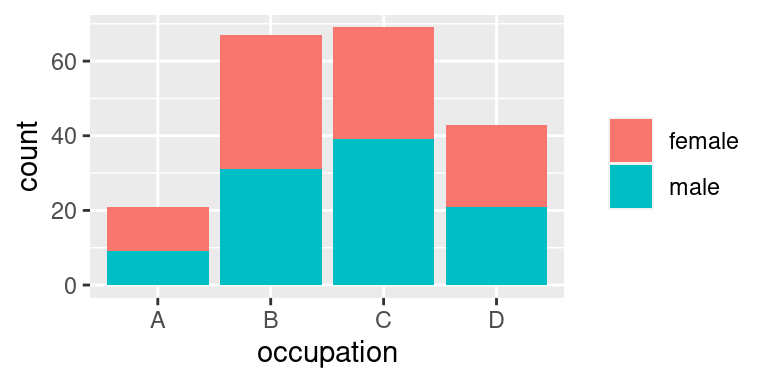 Například toto volání vypustilo jméno legendy a to zcela. Špinavé triky typu `scale_fill_discrete(name = "")` sice způsobí, že jméno "nebude vidět". Respektive se vykreslí prázdný řetězec. Místo pro titulek však bude alokováno a bude tak rozhazovat uspořádání obrázku. `element_blank()` je správná cesta.
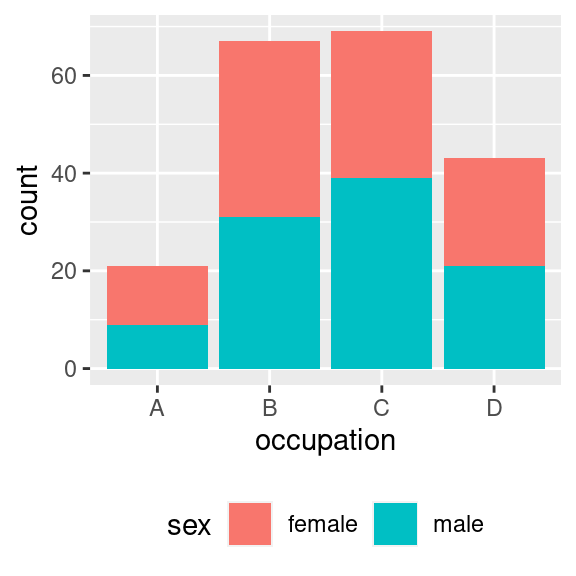
Některé parametry v `theme()` se nastavují pomocí speciálních funkcí -- typicky jde o nastavení velikostí pomocí funkce `unit()`. Další parametry se nastavují prostým zadáním hodnoty. Příkladem může být pozice a orientace legendy:
```r
p +
theme(
legend.position = "bottom",
legend.direction = "horizontal"
)
```
Například toto volání vypustilo jméno legendy a to zcela. Špinavé triky typu `scale_fill_discrete(name = "")` sice způsobí, že jméno "nebude vidět". Respektive se vykreslí prázdný řetězec. Místo pro titulek však bude alokováno a bude tak rozhazovat uspořádání obrázku. `element_blank()` je správná cesta.
Některé parametry v `theme()` se nastavují pomocí speciálních funkcí -- typicky jde o nastavení velikostí pomocí funkce `unit()`. Další parametry se nastavují prostým zadáním hodnoty. Příkladem může být pozice a orientace legendy:
```r
p +
theme(
legend.position = "bottom",
legend.direction = "horizontal"
)
```
 ## Ukládání obrázků
Vytvořené obrázky je možné ukládat s použitím funkce `ggsave()`:
```r
ggsave(filename, plot = last_plot(), device = NULL, path = NULL,
scale = 1, width = NA, height = NA, units = c("in", "cm", "mm"),
dpi = 300, limitsize = TRUE, ...)
```
V základním nastavení `plot = last_plot()` funkce `ggsave()` ukládá poslední vykreslený obrázek. Do parametru `plot` je však možné přiřadit i obrázek (datovou strukturu) uloženou v proměnné. To je velmi užitečné například při tvorbě obrázků, jejichž vykreslování je velmi náročné -- komplikovaných map, bodových grafů s opravdu velkým počtem pozorování a podobně.
Jméno souboru, do kterého se má obrázek uložit se definuje v parametru `filename` jako řetězec. `ggsave()` řetězec analyzuje a podle přípony zvolí exportní formát obrázku. `ggsave()` umožňuje formáty do vektorových formátů i bitmap:
- vektorové formáty: eps, ps, tex (pictex), pdf, svg a wmf (pouze ve Windows)
- bitmapy: jpeg, tiff, png, bmp
Formát (výstupní zařízení) lze zadat přímo pomocí parametru `device`.
První rozhodnutí je, zda použít vektorový formát nebo bitmapu. Uložení do bitmapy znamená uložení "fotografie" obrázku. Takto uložený obrázek může být menší (přesněji nikdy nebude velký) a lze očekávat, že půjde vložit do libovolného dokumentu. Na druhou stranu nepůjde zvětšovat bez různých zkreslení a šumů a výstup nikdy nebude kvalitnější než v případě použití vektorové grafiky.
Vektorové formáty ukládají data, která popisují, kde co na obrázku je. Na rozdíl od bitmap je lze libovolně škálovat bez ztráty kvality a občas přijde vhod i možnost je upravovat (např. posunovat popisky u `geom_label()`/`geom_text`). Schopnost různých WYSIWYG editorů (např. MS Word atp.) pracovat s vektorovými formáty je navíc omezená a je lepší ji řádně otestovat. Nevýhodou je také jejich velká velikost v případě, že objektů v obrázku je mnoho nebo mají složité tvary.
Příkladem obrázku, u kterého se dramaticky liší velikost podle použitého formátu je následující mapa ČR s katastrálními územími obcí. Zobrazená bitmapa (png) má přibližně 0,1 MB. Stejná mapa ve vektorovém formátu má téměř 11,6 MB.

Další parametry `ggsave()` umožňují přesné nastavení výstupu co do rozměrů a rozlišení (pouze pro bitmapy). Při vhodném nastavení těchto parametrů vzhledem k výsledné publikaci lze dosáhnout dobrých výsledků i při používání bitmap. Ve většině případů je však doporučeníhodné používání vektorových formátů.
## Co dělat a co nedělat
*ggplot2* a jeho rozšíření nabízí ohromnou škálu možností. Před tím než začnete kreslit je dobré se rozmyslet, zda je vůbec rozumné kreslit. Často je užitečnější a pro čtenáře srozumitelnější prezentovat data v podobě tabulky -- a to zejména pokud je jich málo. Pokud se rozhodnete kreslit, potom se vždy musíte snažit, aby obrázek čtenáři srozumitelně komunikoval nezkreslenou informaci.
Tufte (2001) formuluje jednoduché doporučení, které byste měli mít vždy v paměti:
*Graphical excellence is that which gives to the viewer the greatest number of ideas in the shortest time with the least ink in the smallest space.*
## Ukládání obrázků
Vytvořené obrázky je možné ukládat s použitím funkce `ggsave()`:
```r
ggsave(filename, plot = last_plot(), device = NULL, path = NULL,
scale = 1, width = NA, height = NA, units = c("in", "cm", "mm"),
dpi = 300, limitsize = TRUE, ...)
```
V základním nastavení `plot = last_plot()` funkce `ggsave()` ukládá poslední vykreslený obrázek. Do parametru `plot` je však možné přiřadit i obrázek (datovou strukturu) uloženou v proměnné. To je velmi užitečné například při tvorbě obrázků, jejichž vykreslování je velmi náročné -- komplikovaných map, bodových grafů s opravdu velkým počtem pozorování a podobně.
Jméno souboru, do kterého se má obrázek uložit se definuje v parametru `filename` jako řetězec. `ggsave()` řetězec analyzuje a podle přípony zvolí exportní formát obrázku. `ggsave()` umožňuje formáty do vektorových formátů i bitmap:
- vektorové formáty: eps, ps, tex (pictex), pdf, svg a wmf (pouze ve Windows)
- bitmapy: jpeg, tiff, png, bmp
Formát (výstupní zařízení) lze zadat přímo pomocí parametru `device`.
První rozhodnutí je, zda použít vektorový formát nebo bitmapu. Uložení do bitmapy znamená uložení "fotografie" obrázku. Takto uložený obrázek může být menší (přesněji nikdy nebude velký) a lze očekávat, že půjde vložit do libovolného dokumentu. Na druhou stranu nepůjde zvětšovat bez různých zkreslení a šumů a výstup nikdy nebude kvalitnější než v případě použití vektorové grafiky.
Vektorové formáty ukládají data, která popisují, kde co na obrázku je. Na rozdíl od bitmap je lze libovolně škálovat bez ztráty kvality a občas přijde vhod i možnost je upravovat (např. posunovat popisky u `geom_label()`/`geom_text`). Schopnost různých WYSIWYG editorů (např. MS Word atp.) pracovat s vektorovými formáty je navíc omezená a je lepší ji řádně otestovat. Nevýhodou je také jejich velká velikost v případě, že objektů v obrázku je mnoho nebo mají složité tvary.
Příkladem obrázku, u kterého se dramaticky liší velikost podle použitého formátu je následující mapa ČR s katastrálními územími obcí. Zobrazená bitmapa (png) má přibližně 0,1 MB. Stejná mapa ve vektorovém formátu má téměř 11,6 MB.

Další parametry `ggsave()` umožňují přesné nastavení výstupu co do rozměrů a rozlišení (pouze pro bitmapy). Při vhodném nastavení těchto parametrů vzhledem k výsledné publikaci lze dosáhnout dobrých výsledků i při používání bitmap. Ve většině případů je však doporučeníhodné používání vektorových formátů.
## Co dělat a co nedělat
*ggplot2* a jeho rozšíření nabízí ohromnou škálu možností. Před tím než začnete kreslit je dobré se rozmyslet, zda je vůbec rozumné kreslit. Často je užitečnější a pro čtenáře srozumitelnější prezentovat data v podobě tabulky -- a to zejména pokud je jich málo. Pokud se rozhodnete kreslit, potom se vždy musíte snažit, aby obrázek čtenáři srozumitelně komunikoval nezkreslenou informaci.
Tufte (2001) formuluje jednoduché doporučení, které byste měli mít vždy v paměti:
*Graphical excellence is that which gives to the viewer the greatest number of ideas in the shortest time with the least ink in the smallest space.*