Interaktivní osnova
[Vítek Novotný] Word Embeddings: Towards Fast, Interpretable, and Accurate Information Retrieval Systems 15. 10. 2020
Readings
Bojanowski et al. (2017) [3] and Section 2.2 from Mikolov et al. (2017) [7].
Abstract
Word embeddings produced by shallow neural networks (Word2Vec [1], GloVe [2], fastText [3], ...) provide strong baselines for many NLP tasks such as semantic text similarity, [4] text classification, [5] and information retrieval. [6] Unlike state-of-the-art language models, which are accurate but also slow, black-boxed, and monolithic, word embeddings lend themselves to solutions that are fast, interpretable, and modular. Improving the accuracy of word embeddings provides an important counterbalance to the ever-increasing computational and architectural complexity of state-of-the-art language models.
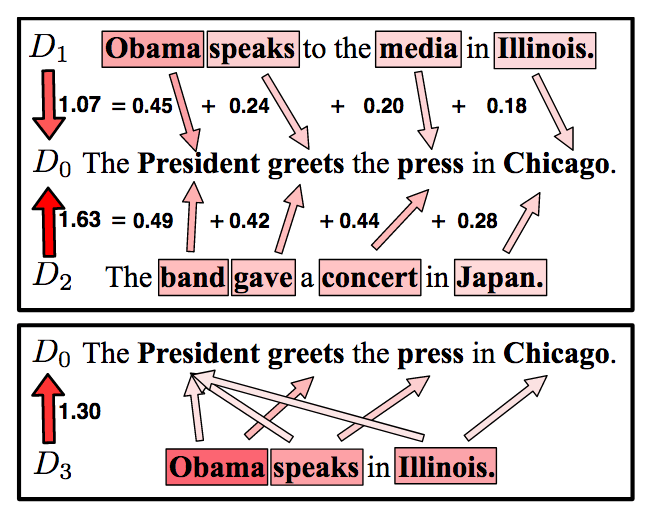
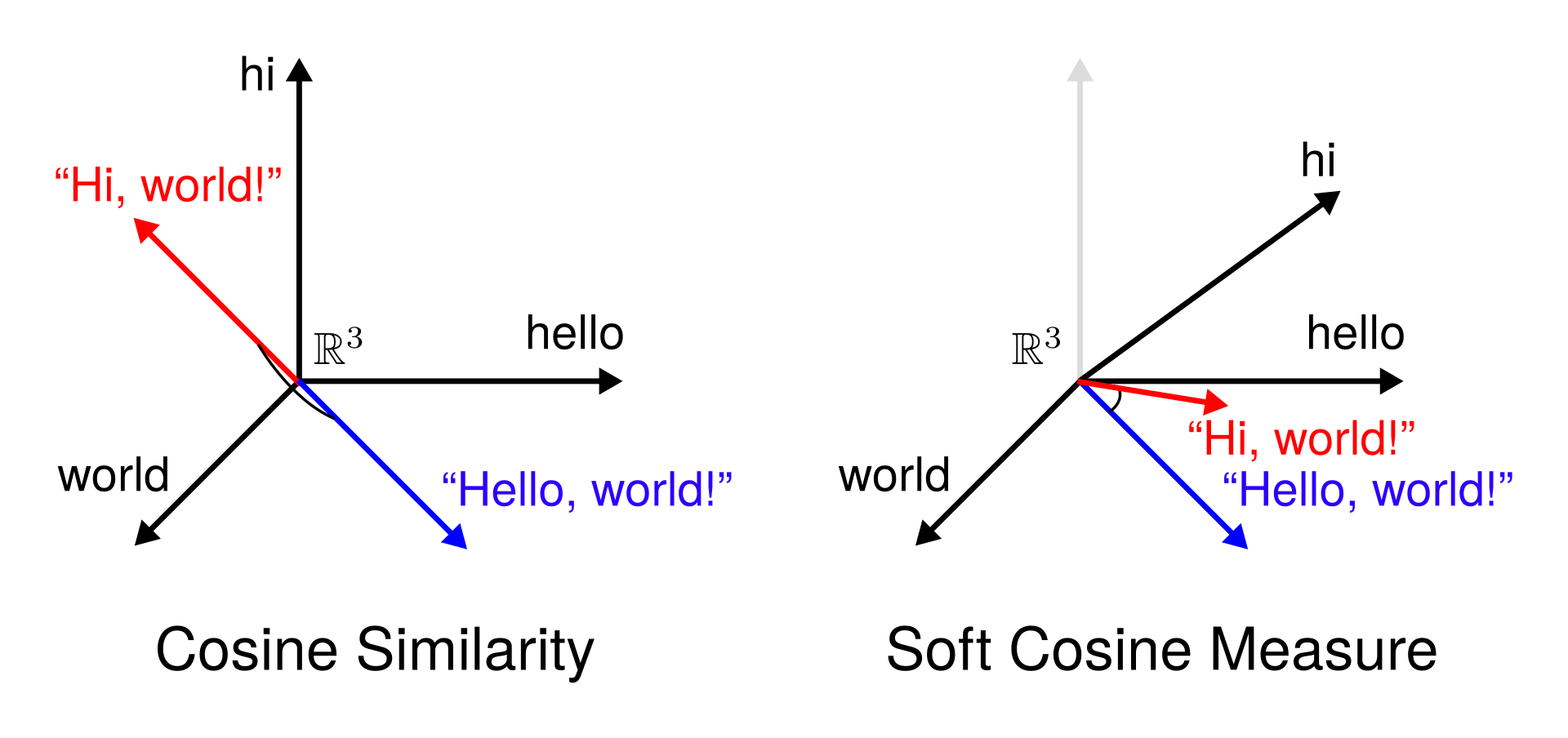
In
2017, Mikolov et al. [7, Section 2.2] introduced position-dependent
weighting to the context vector computation in the fastText CBOW model.
On Common Crawl, this extension has led to a 5 % improvement on the English word analogy task. Despite the usefulness of the position-dependent weighting extension, it has not been publicly implemented yet. We propose to add this extension to Gensim's fastText and be the first publicly available implementation of the extension. (See the topics for your bachelor thesis and master thesis.)
In previous work, the optimization of fastText subword sizes has been largely neglected, and non-English fastText language models were trained using subword sizes optimized for English and German. In our work, we train English, German, Czech, and Italian fastText language models on Wikipedia, and we optimize the subword sizes on the English, German, Czech, and Italian word analogy tasks. We show that the optimization of subword sizes results in a 5% improvement in the Czech word analogy task. We also show that computationally expensive hyperparameter optimization can be replaced with cheap n-gram frequency analysis. (See the topics for your bachelor thesis and master thesis.)
Word Embeddings: Towards Fast, Interpretable, and Accurate Information Retrieval Systems
Video recording for the 2020-10-15 talk by Vítek Novotný
Literature
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781. https://arxiv.org/pdf/1301.3781.pdf
- Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 1532-1543.
https://nlp.stanford.edu/pubs/glove.pdf
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135-146.
https://www.aclweb.org/anthology/Q17-1010.pdf
- Charlet, D., & Damnati, G. (2017). Simbow at semeval-2017 task 3: Soft-cosine semantic similarity between questions for community question answering. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). 315-319. https://www.aclweb.org/anthology/S17-2051.pdf
- Kusner, M., et al. From word embeddings to document distances. In: International conference on machine learning. 2015. p. 957-966. http://proceedings.mlr.press/v37/kusnerb15.pdf
- Novotný, V., Sojka, P., Štefánik, M., & Lupták, D. (2020). Three is Better than One: Ensembling Math Information Retrieval Systems. In CEUR Workshop Proceedings, Greece, vol. 2020. ISSN 1613-0073.
http://www.dei.unipd.it/~ferro/CLEF-WN-Drafts/CLEF2020/paper_235.pdf
- Mikolov, T., Grave, E., Bojanowski, P., Puhrsch, C., & Joulin, A. (2017). Advances in pre-training distributed word representations. arXiv preprint arXiv:1712.09405. https://arxiv.org/pdf/1712.09405.pdf