Mimo SPSS existují i další programy pro statistickou analýzu. Mezi nejznámnější free programy patří např.
Seminární cvičení
Základy práce s programem IBM SPSS
SPSS je široce používaný program pro statistickou analýzu v sociálních vědách. Kromě statistické analýzy je tento software vybaven funkcemi pro správu dat (pokročilé filtrování dat, propojování souborů, transformace dat) a dokumentace k datům (v datovém souboru jsou kromě samotných dat uložena i dokumentační metadata). Významnou funkcí SPSS je mimo sofistikované interaktivní uživatelské rozhraní možnost využití i poměrně komplexního interního skriptovacího jazyka.
Tento software jsme zvolili pro výuku hlavně ze dvou důvodů - a) je poměrně uživatelsky přívětivý (v konkurenci statistických programů) a b) v rámci sociálně-vědních disciplín má zřejmě nejrozšířenější uživatelskou základnu, což se pozitivně projevuje množstvím volně dostupných návodů na Internetu. I když jde o komerční produkt, studenti a zaměstnanci Masarykovy univerzity mají možnost využít SPSS v rámci univerzitní multilicence.
Programy pro statistickou analýzu dat
Instalace IBM SPSS
Instalační soubor IBM SPSS získáte po přihlášení na webovou stránku inet.muni.cz kde se proklikejte přes provozní služby -> software -> nabídka softwaru. Zde klikněte na tlačítko ZÍSKAT pro verzi SPSS Statistics 25. Na následující stránce si vyberte správný ISO soubor (buď kombinovaný pro Windows a Mac nebo zvlášť pro Linux), stáhněte, a pro pozdější použití si do schránky zkopírujte uvedený autorizační kód. Po dokončení stahování stačí ve Windows 10 kliknout na získaný ISO soubor pravým tlačítkem, zvolit PŘIPOJIT, a v průzkumníku se vám objeví virtuální disk s instalací SPSS. Instalaci spustíte klasicky přes setup.exe ukrytý ve složce windows. Po několika potvrzujících kliknutích (Python Essentials nepotřebujete, instalace je popsána podrobněji zde) je SPSS nainstalováno. Po instalaci se objeví okénko pro aktivaci produktu (Licence authorization wizzard), kde zvolíte možnost Authorized User Licence (I purchased a single copy of the product) a v následujícím okénku vložíte autorizační kód, který je uveden na stejné stránce, kde jste si stahovali instalační ISO soubor (v řádku mezi oběma odkazy). Tímto je instalace dokončena a můžete SPSS spustit.
Problémy s instalací
IBM SPSS se nehodí instalovat na starších strojích, jde o poměrně náročný program co se týče výkonu počítače. Pokud SPSS neběží dostatečně svižně nebo se vůbec nepodaří nainstalovat, doporučujeme instalaci programu PSPP, který se snaží vizuálně (uživatelské prostředi) co nejvíce napodobit SPSS, ale je méně náročný na instalaci a běh programu (za cenu jistých ústupků v kvalitě ovládání). Dokáže nativně pracovat s datovými soubory SPSS (soubory s příponou .sav).
Orientace v IBM SPSS
Program SPSS využívá tři základní typy oken, které jsou obvykle souběžně otevřeny:
- datové okno (data window)
- výsledkové okno (output window)
- syntaxové okno (syntax window)
Datové okno SPSS
Datové okno obsahuje naši datovou matici. Data jsou v okně uspořádána standardním způsobem - v každém řádku je jeden případ (case) a jednotlivé sloupce představují proměnné. Všimněte si, že v záhlaví datové matice je zvláštní řádek vyhrazený pro pojmenování jednotlivých proměnných (na rozdíl od Excelu). Data je možné v buňkách upravovat prostým přepisem, ale pokud máme datovou matici kompletní, neměli bychom mít žádný důvod to dělat; veškeré operace s daty bychom měli provádět pomocí funkcí SPSS. Pokud chceme upravovat názvy proměnných, jejich typ či jiná metadata, je třeba si toto okno přepnout z výchozího DATA VIEW do VARIABLE VIEW pomocí záložky dole.
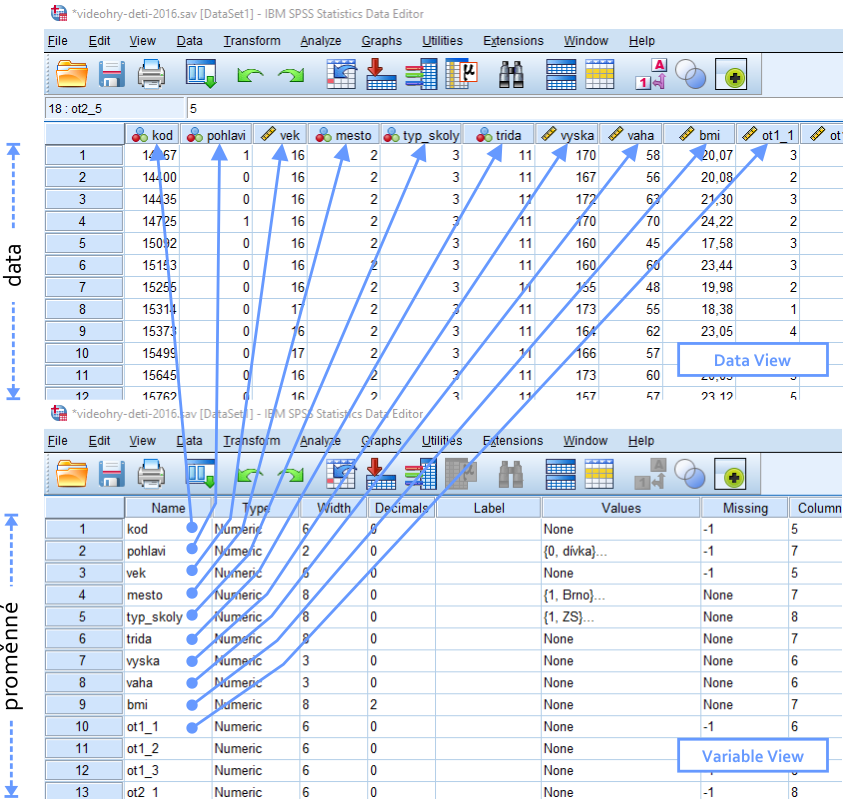
SPSS layout
Datové okno v zobrazení Data View (nahoře) a Variable View (dole).
Pokud se přepneme do VARIABLE VIEW, nevidíme již samotná data, ale pouze seznam našich proměnných (v řádcích) a jednotlivé kategorie metadat (ve sloupcích) pro tyto proměnné. Projděme si význam některých metadat, která jsou pro nás nejužitečnější:
- Name. Jak lze předpokládat, jedná se o název proměnné. Toto pojmenování se pak objevuje v záhlaví sloupce, když se přepneme zpátky do DATA VIEW.
- Type. Z nabízených typů proměnné využíváme zejména typ Numeric (kvantifikované údaje, prostě čísla), String (nekvantifikovatelné údaje, např. emailové adresy respondentů, přepisy odpovědí na otevřené otázky v dotazníku, apod.) a Date (datum - užitečné pro časové značky).
- LABEL. Zde máme možnost si poznamenat význam proměnné, pokud to není zjevné z krátkého pojmenování v poli Name. Je užitečné si sem např. přepsat celé znění položky dotazníku.
- VALUES. V poli hodnoty je vhodné si zapsat význam jednotlivých kódů odpovědí. Napříkad pokud se v dotazníku ptáme respondenta na věk a nabízíme výběr ze tří věkových kategorií, v datové matici je zřejmě zakódujeme čísly 1, 2, a 3. Zde si pak poznamenáme, že kód 1 znamená věkovou kategorii 6 až 9, kód 2 věk 10 až 13 a kód 3 kategorii 14 až 18 let.
- MISSING. Při sběru dat pomocí dotazníku se běžně stává, že respondent u některé otázky neoznačí žádnou odpověď (ať již z přehlédnutí nebo neochoty odpovědět). V takovém případě při přepisu dotazníku do datové matice zadáme hodnotu, která je mimo očekávaný rozsah proměnné. Například pokud repospodent zapomene vyplnit svůj věk, zapíšu kód 999, nebo pokud vynechá položku s 5-bodovou Likertovou škálou, zapíšu hodnotu 9. Šlo by sice buňku ponechat jednoduše prázdnou (tzv. system missing), ale zvykem je používat missing hodnotu, aby bylo jasné, že respondent skutečně otázku nezodpověděl a nejde třeba o přehlédnutí kodéra při přepisu dat. Hodnotu uvedenou jako missing pak SPSS při všech analýzách jednoduše ignoruje, jako by tam nebyla.
Výsledkové okno
Ve výsledkovém okně (Output window) SPSS postupně vypisuje výstupy našich analýz. Nejde o interaktivní výsledky - pokud změním datovou matici, výsledkové tabulky se nepřepíšou; je potřeba analýzu vyvolat znovu. Nové výsledky se jednoduše zařadí na konec výpisu a je možné se kdykoli podívat nahoru na předchozí výsledky (pro snadnou orientaci je vlevo stromová struktura historie provedených analýz a jejich výstupů).
Při výpisu výsledku SPSS defaultně používá k označení výstupů krátké názvy proměnných z (Name) a jejich číselné hodnoty z datové matice, ale v nastavení SPSS (Edit -> Options -> Output -> Labelling) je možné výpis přepnout na používání metadat Label a Values. V praxi se pak ale výpis stává často nepřehledným.
Syntaxové okno
Syntaxové okno se hodí zejména pokročilým uživatelům, začátečním se s ním vůbec nemusí setkat. Jde o to, že každou analýzu nebo funkci, kterou v SPSS provedu pomocí dialogových oken, lze přepsat do interního programovacího jazyka (SPSS syntaxe). Většina dialogových oken má tlačítko PASTE, kterým se naklikaná analýza přepíše do syntaxového okna ve formě několika řádek programového kódu.
Výhoda SPSS syntaxe tkví v tom, že se mi takto zaznamenává historie provedených analýz, které mohu kdykoli později zopakovat spuštěním příslušné části kódu. Hodí se to i tehdy, pokud opakuji stejnou sadu analýz na různých datových maticích (které mají stejnou strukturu, tj. proměnné).
Základní manipulace s daty v IBM SPSS
Na tomto místě si představíme několik málo funkcí, které jsou při manipulaci s daty nejčastěji používané a užitečné. Všechny tyto funkce jsou přístupné přes horní menu, v položkách DATA a TRANSFORM.
Řazení dat (DATA -> SORT CASES)
Datovou matici je možné si kdykoli seřadit podle jedné nebo více proměnných, buď vzestupně či sestupně. Tato funkce nemění data, změna je pouze v jejich zobrazení. Pořadí případů nemá na výsledky analýz žádný vliv.
Porovnávání dle skupin (DATA -> SPLIT FILE)
Tato funkce nastaví chování SPSS tak, aby se výsledky všech následujících analýz počítaly zvlášť pro jednotlivé skupiny definované některou (kategoriální) proměnnou. Nejčastěji si skupiny dělíme např. dle pohlaví (porovnání chlapců a dívek) nebo např. národnosti.
Výběr podskupin (DATA -> SELECT CASES)
V některých případech potřebujeme počítat analýzy pro určitý podsoubor případů v našich datech (například pokud chceme analyzovat data pouze u skupiny osob, které na určitou otázku odpověděly kladně). SPSS na základě tohoto výběru bude brát v úvahu pouze data osob, které kritérium splňují, a ostatní případy v datové matici bude ignorovat. Úspěšné nastavení této funkce poznáte podle toho, že čísla řádků osob, které kritérium nesplňují, jsou v DATA VIEW přeškrtnutá.
Vytváření nových proměnných (TRANSFORM -> COMPUTE VARIABLE)
Představme si situaci, kdy získáme data o posledním vysvědčení žáků 8 tříd všech základních škol v Brně a chtěli bychom na základě těchto dat identifikovat skupinu žáků s průměrným prospěchem vyšším než 1,5 (například pro udělení prospěchového stipendia). Pomocí funkce COMPUTE VARIABLE můžeme jednoduše nadefinovat výpočet nové proměnné, která bude představovat aritmetický průměr ze známek vybraných předmětů. Nově vypočtená proměnná se zadaným názvem se objeví v datové matici úplně na konci a bude obsahovat studijní průměr pro každého jednotlivého žáka. Posléze můžeme data jednoduše vzestupně seřadit dle této nové proměnné a vybrat ty s průměrem nad 1,5.
Překódování proměnných (TRANSFORM -> RECODE INTO SAME/DIFFERENT VARIABLE)
Tato funkce má nepřeberné množství různých využití. Jedním z typických případů je např. překódování spojité proměnné do kategorií. Představme si, že v datové matici existuje proměnná IQ, na základě které bychom chtěli respondenty rozdělit do tří skupin - (1) podprůměrně inteligentních, (2) průměrně inteligentních, (3) nadprůměrně inteligentních. Za tím účelem pomocí této funkce překódujeme proměnnou IQ do proměnné pojmenované např. INTELEKT tím způsobem, že hodnoty IQ menší než 90 mají být v proměnné INTELEKT kódovány číslem 1, hodnoty IQ mezi 90 a 110 číslem 2, a hodnoty IQ větší než 110 číslem 3. Proměnná IQ zůstane samozřejmě v datové matici zachována, ale přibyde nová proměnná INTELEKT, která bude obsahovat hodnoty v rozsahu 1 až 3 (samozřejmě si nezapomeneme do metadat poznamenat, že hodnota 1=podprůmerné IQ, 2=průměrné IQ, 3=nadprůměrné IQ). Následně můžeme tyto proměnnou využít ve funkci SPLIT FILE nebo SELECT CASES a počítat další analýzy pro tyto 3 skupiny zvlášť.