Při analýze kvalitativních dat obvykle mluvíme o různých způsobech analýzy transkriptů (z individuálních rozhovorů, skupinových rozhovorů, z pozorování atd.) nebo zkoumání různých dokumentů (např. politických strategií, novinových zpráv) či artefaktů (např. fotografií, výrobků dětí ve škole). Cílem kvalitativní analýzy dat je materiál podrobit systematické analýze a interpretaci.
V kvalitativním výzkumu existují různé analytické strategie při práci s daty, které jsou zpravidla spjaté s různými tradicemi kvalitativního výzkumu (např. etnografie, fenomenologie, zakotvená teorie, případová studie, biografie atd.). Patří k nim např. psaní analytických poznámek (tzv. memopoznámek), různé formy zobrazování dat, konstantní srovnávání, identifikace hlavních kategorií a jejich vzájemných vztahů, kódování, analýza deviantních případů atd. (viz Creswell, 1998)
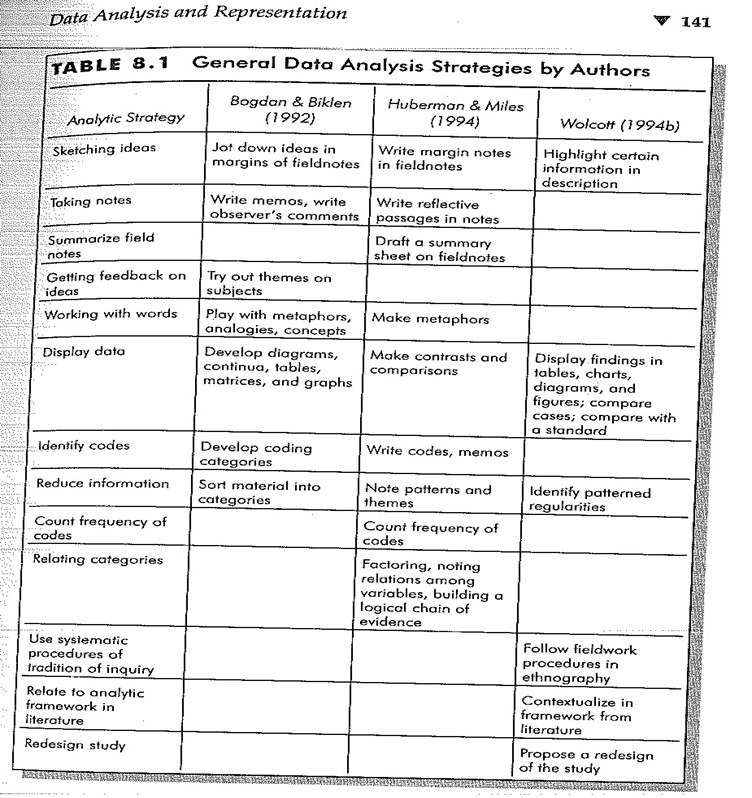
Postup kvalitativní analýzy dat
- třídění dat, jejich kódování a kategorizace
- formulace základních (jádrových) tvrzení
- interpretace
- komparace (typologizace)
- teoretická generalizace
(Švaříček & Šedová, 2013)
Nejrozšířenější strategií analýzy kvalitativních dat je tzv. otevřené kódování, tedy hledání významových kategorií zastupujících nejvýznamnější témata v datech. Jde o techniku vyvinutou v rámci zakotvené teorie (Glaser & Strauss, 1967), která je však hojně využívána i v dalších tradicích kvalitativního výzkumu. Nejprve data (např. přepisy rozhovorů, terénní poznámky atd.) pozorně a opakovaně čteme a označujeme si analyticky významná místa, přičemž hlavním měřítkem významu datových úryvků jsou naše výzkumné otázky. K takovým důležitým úryvkům si píšeme poznámky či komentáře, z nichž tvoříme první kódy. Popsaná strategie vede ke vzniku induktivních kódů, které jsou zakotveny v našich datech, tj. z nich pomyslně „vyrostly“. Induktivní strategii tvorby kódů je možné kombinovat i s deduktivnějšími postupy, kdy je zpravidla část kódů odvozena z teorie. Takový postup je typický pro kódování dat větším počtem výzkumníků v týmových výzkumných projektech (např. v týmu předem sdílený kódovací strom je doplněný o induktivní kódy tvořené individuálními výzkumníky).
Kód je obvykle slovo nebo fráze, která vystihuje shrnující znak určité skupiny textových nebo vizuálních dat. Kód nám říká, čeho se daná datová sekvence týká, jakému jevu se věnuje. Pod jedním kódem tedy shromažďujeme úryvky, které spolu tematicky souvisí. Kód by se měl v datech objevovat opakovaně (tj. měl by být dostatečně „sycen“). Pokud se různé kódy v datech potkávají, ukazuje to na jejich potenciální vztahy a zároveň na analytickou důležitost kódovaného datového segmentu.
Chyby v kódování
- kódování příliš dlouhých datových úryvků
- kódování příliš krátkých datových úryvků, které samy o sobě nenesou význam
- příliš obecné kódy
- příliš konkrétní kódy
- příliš mnoho kódů
- málo kódů
- triviální kódy
- komplikovaně pojmenované kódy
- kódy mnohovýznamové, kombinující více významů či vlastností, sledující více dimenzí daného jevu
- přehnané použití tzv. in vivo kódů (tedy kódů využívajících jazyka samotných informantů) - výzkumník by měl jít hlouběji pod povrchový význam sdělení (tzn. nereprodukovat pouze to, co řekl informant)
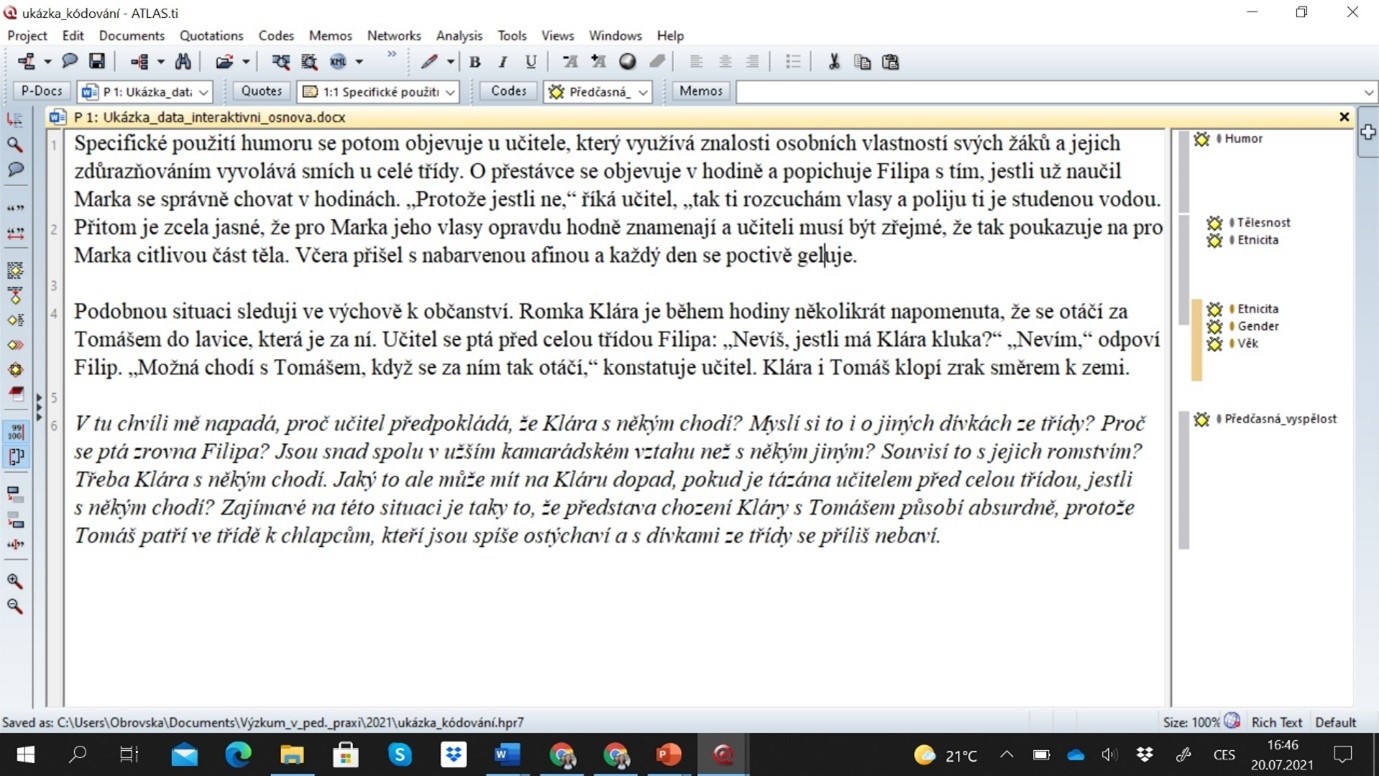
Atlas.ti
Ukázka části okódovaných terénních poznámek z výzkumu etnicity v třídních kolektivech (Obrovská, 2018) v programu Atlas.ti
A co dál? Aneb další analytické kroky po dokončení kódování
Po fázi kódování následuje fáze kategorizování, kdy významově příbuzné kódy shlukujeme do obecnějších kategorií nebo naopak kódy obecnější povahy štěpíme do dílčích sub-kódů. V další fázi analýzy hledáme vztahy mezi identifikovanými kategoriemi, které pak tvoří kostru analytického „příběhu“ či hlavní argumentační linie výsledné studie či výzkumné zprávy. Vztahy mezi kategoriemi je vhodné nějak graficky znázornit (prostřednictvím schématu, diagramu, modelu apod.). Zjištění vznikají z kódů, které jsou dostatečně nasycené a vztahují se k celému soboru případů (pokud je náš výzkumný vzorek tvořen větším počtem aktérů či případů).
V datové ukázce výše se ukázal být významným úryvek, který byl kódovaný třemi v datech silně sycenými kódy souběžně (věk, etnicita a gender). Vztahy mezi těmito kódy při analýze jednání vyučujících ve vztahu k romským žákům a žákyním ve vyučovacích hodinách a rovněž v triangulaci s analýzou rozhovorů s vyučujícími poukázaly na existenci „pedagogického diskurzu o předčasném dospívání romských žáků“. Za jádrové tvrzení lze v tomto kontextu považovat následující zjištění: skrze pedagogický diskurz o předčasném dospívání byly vyučujícími zdůrazňovány určité aspekty chování romského žactva, které je mohly stavět do nepříznivého světla.
Toto zjištění je ve studii Obrovské (2016, p. 72) podloženo citací úryvku z okódovaných terénních poznámek (viz výše):
Následující promluva zachycuje učitelův předpoklad, že romská dívka Klára s někým chodí, který se snaží ověřit u romského chlapce Filipa.
Ve výchově k občanství je romská dívka Klára během hodiny několikrát napomenuta, že se otáčí za Tomášem, který sedí v lavici za ní. Učitel se ptá Filipa: „Nevíš, jestli má Klára kluka?“ „Nevím, jak to mám vědět?“ odpoví Filip. „Možná chodí s Tomášem, když se za ním tak otáčí,“ konstatuje učitel. Klára i Tomáš klopí zrak směrem k zemi.
(terénní poznámky, 30.1. 2014)
V této situaci učitel očekává, že Klára s někým chodí nebo by s někým chodit mohla, přičemž podobnou predikci k ostatním dívkám ve třídě nevznáší, přestože u propadlých a starších dívek Zuzky a Nikoly by z hlediska vývojové logiky, kterou jsou učitelé zvyklí uplatňovat, působila adekvátněji. Zasazení této promluvy do žánru humoru nevyvazuje Kláru z důsledků, které pro ni tato očekávání mají. A právě těch se chtěla Klára vyvarovat, když intenzivně pracovala na tom, aby se od představy chození s někým distancovala. Zaznamenala jsem, jak ostentativně setřásala ruce Filipa, Marka a Petra, které se jí občas o přestávkách snaží dotýkat, nebo ukrýváním se na záchod (viz níže), svou vytrvalou péčí o vzhled ne/vyřčená podezření spíše potvrzuje. Klára totiž patří k nejvíce upraveným a nejhezčím dívkám ve třídě. Klára si pravidelně rovnala své kudrnaté vlasy žehličkou na vlasy a pečlivě upravená, i když v nesportovním oblečení, bývala i v hodinách tělocviku. Její práce na vzhledu může být strategií zvyšování statusu v kolektivu, protože dívky z etnických menšin bývají v kontextu desegregované třídy daleko méně sebevědomé a častěji se přizpůsobují požadavkům školy než jejich chlapečtí vrstevníci, jak si všímá i Youdell (2003).
Citovaná část článku Obrovské (2016) ukazuje, jak lze dále jádrové tvrzení podložené ilustrativní citací z dat interpretačně rozvíjet. V tomto případě autorka k rozvíjení teze o pedagogickém diskurzu o předčasném dospívání romských žáků využívá kontrastování s dalšími případy či typy případů (tj. vztahování se vyučujících ke starším majoritním dívkám) a rovněž vztahuje předpoklady vyučujících o předčasné vyspělosti romského žactva k „práci“ na vzhledu pozorované u některých romských dívek, kterou interpretuje s odkazem na již exitující výzkumy (viz Youdell, 2003) jako možnou strategii zvyšování sociálního postavení romských dívek mezi vrstevníky v etnicky smíšených kolektivech.
Následující schéma publikované v knize Obrovské (2018, p. 181) ukazuje možnosti vizualizace vztahů mezi hlavními analytickými kategoriemi, když vzájemně provazuje identifikovaný pedagogický diskurz o předčasném dospívání se strategiemi participace romských dívek v kolektivu (kam spadá rovněž práce na vzhledu či femininitě) a jejich dopady na sociální pozici těchto dívek v kolektivu třídy.
Softwarové programy určené pro kvalitativní analýzu dat
Kódování, stejně jako i další analytické postupy v kvalitativním výzkumu, významně usnadňují specializované softwarové programy k tomu určené - k nejznámějším patří Atlas.ti, Nudist, NVivo, MAXQDA atd. Pomocí těchto programů můžeme efektivně propojit různé texty a typy promluv získané na různých místech v různých časech.
Co umí program Atlas.ti?
- Třídění dokumentů do tzv. primárních rodin (např. učitelé, učitelé-muži, učitelky-ženy, rodiče apod.) umožňuje optimalizovat počet dokumentů, s nímž pracujeme; v důsledku je naše analýza zaměřenější
- Informace o míře zakotvenosti kódů jedním kliknutím myši
- Zobrazení úryvků kódovaných určitým kódem v tzv. síťových náhledech, které umožňují vizualizaci dat
- Tvorba vztahů mezi kódy a jejich zobrazení v síťových náhledech
- Vytváření vztahů mezi úryvky (tzv. hyperlinky)
- Synchronizace přepisu rozhovoru s audionahrávkou
- Analytické nástroje – např. vyhledávání úryvků náležejících pod definovanou kombinaci kódů
- Automatické kódování
Literatura
Creswell, J. W. (1998). Qualitative Inquiry and Research Design. Choosing among Five Traditions. SAGE Publications.
Glaser, B. G., & Strauss, A. L. (1967). The Discovery the Grounded Theory. Strategies for Qualitative Research. Aldine publishing company.
Obrovská, J. (2016). Frajeři, rapeři a propadlíci: etnografie etnicity a etnizace v desegregované školní třídě. Sociologický časopis, 52(1), 53–78. https://dx.doi.org/10.13060/00380288.2016.52.1.242
Obrovská, J. (2018). Roma Identity and Ritual in the Classroom. The Institutional Embeddedness of Ethnicity. Palgrave Macmillan.
Švaříček, R., & Šeďová, K. (2013). Jak psát kvalitativně orientované výzkumné studie. Kvalita v kvalitativním výzkumu. Pedagogická orientace, 23(4), 478–510. http://dx.doi.org/10.5817/PedOr2013-4-478
Youdell, D. (2003). Identity Traps or How Black Students Fail: The Intersections between Biohraphical, Sub-cultural, and Learner Identities. British Journal of Sociology of Education, 24(1), 3–20. 10.1080/01425690301912