Sečíst skóry, získat deskriptivní statistiky a vypočítat vnitřní konzistenci je snažší v drag and drop aplikacích, jako je SPSS, JASP, nebo jamovi.
Využití nástrojů AI v psychologii
Využití AI při statistické analýze dat
Instrukce pro přednášku
Na přednášce budeme společně analyzovat data, proto si prosím s sebou přineste notebook. Nainstalujte si prosím do svého počítače R a RStudio z níže uvedeného odkazu a stáhněte si dataset z odkazu.
Pouze pro jistotu, pokud nemáte účet na Copilotovi nebo Open AI, založte si ho prosím 😊
Fiktivní DP: Vliv psychologické flexibility na duševní zdraví
V rámci své diplomové práce zkoumáte, zda má psychologická flexibilita vliv na duševní zdraví dospělým osob v Česku. Máte podrobně nastudovanou literaturu, stanové výzkumné otázky a hypotézy. K operacionalizaci duševního zdraví jste si vybrali Depression Anxiety Stress Scela (DASS-21) a Škálu spokojenosti se životem (SWLS). Zjišťujete však, že v současné době není v češtině dostupný žádný dotazník psychologické flexibility. Vaším prvním krokem je tak překlad dotazníku Comprehensive assessment of Acceptance and Commitment Therapy processes (CompACT), který jste si vybrali k operacionalizaci psychologické flexibility.
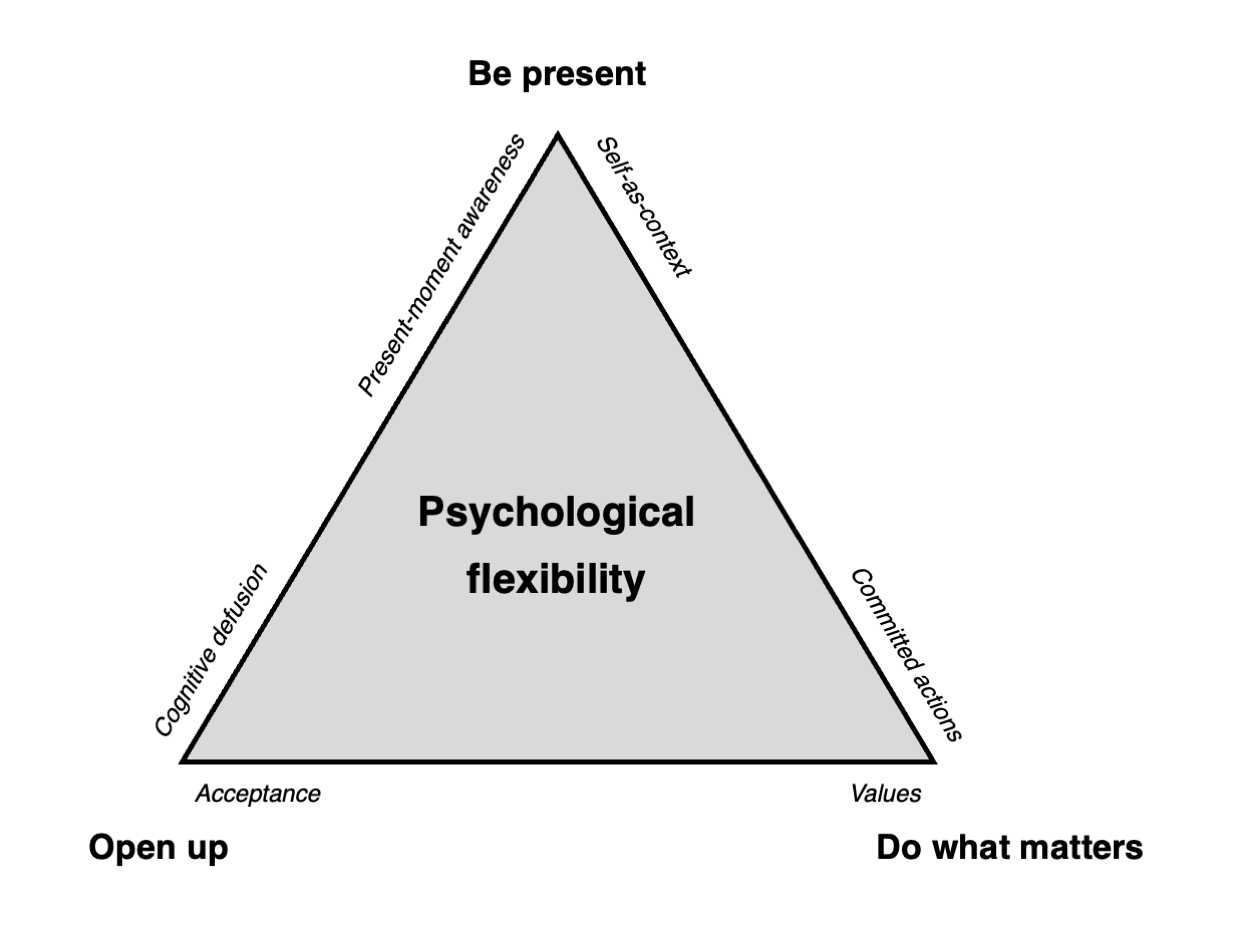
Psychologická flexibilita
Psychologická flexibilita je schopnost být přítomný/á, otevřený/á prožitům a dělat to, na čem nám záleží. CompACT dotazník má tři škály (otevřenost vůči zkušenosti, vědomé chování, hodnotné jednání), které jsou zasazené do kontextu Triflex modelu:
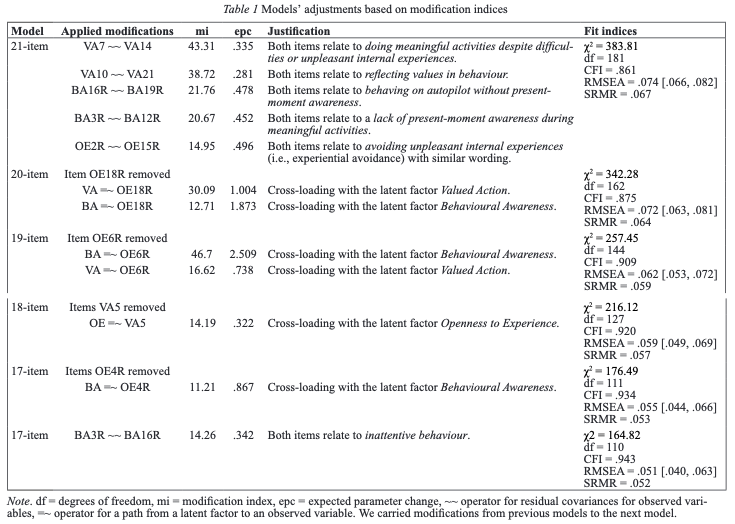
Základní psychometrické charakteristiky – společná analýza
Máte posbíraná data. Než se ale pustíte do regresní analýzy, je nutné ověřit alespoň základní psychometrické vlastnosti nově přeloženého dotazníku – faktorovou strukturu a reliabilitu.
Kód pro CFA a McDonaldovu omegu
Samostatný úkol
Vaším úkolem v druhé části přednášky bude za pomoci AI zjistit, zda faktory psychologické flexibility predikují aspekty duševního zdraví. K analýze dat použijte robustní regresi.
Prompty, finální verze vašich kódů, výstupy z RStudia a vaše závěry uložte do textového souboru a nahrajte do odevzdávárny. Kódy, ke kterým jsem s pomocí AI došel já, se vám zobrazí při rozkliknutí klíče.
Zadání
1. část
Jaký je rozdíl mezi lineární regresí a robustní regresí? Pokud nevíte, co je to lineární regrese, zkuste se zeptat AI.
2. část
Než se pustíte do analýzy, je nutné sečíst skóry pro jednotlivé škály, protože ty v datasetu nejsou. Spuštění kódu níže v RStudiu spočítá a vytvoří tyto proměnné:
|
Proměnná |
Název |
|
Otevřenost vůči zkušenosti |
OE |
|
Vědomé chování |
BA |
|
Hodnotné jednání |
VA |
|
Deprese |
D |
|
Úzkost |
A |
|
Stres |
S |
|
Well-being |
WB |
Kód pro sečtení položek do skórů subškál
3. část
Spočítejte základní deskriptivní statistiky pro výše uvedené proměnné a věk respondentů. Zjistěte, jaké mají zastoupení jednotlivá pohlaví mezi respondenty.
Kód pro deskriptivní statistiky
Kód pro deskriptivní statistiky
TIP
4. část
Které balíčky pro R lze využít pro robustní regresi?
Jeden z balíčků si vyberte a nechte si vygenerovat kód, pomocí kterého robustní regresi provedete.
Porovnejte výsledky s lineární regresí. Rozdíl v kódech je minimální, AI vám poradí.
Kód pro regrese
5. část
Za pomoci AI zjistěte, co vám říkají jednotlivé části výstupů robustní regrese. Výsledky analýz zpracujte tak, jako byste psali report výsledků výzkumu.
Kód pro export outputu
Odevzdávárna pro samostatný úkol
Obrázky pro přednášku

Zapojení se do výzkum
Na závěr bych vás rád poprosil o zapojení se do výzkumu, jehož cílem je ověřit psychometrické vlastnosti dalších zahraničních metod posuzujících psychologickou flexibilitu. Momentálně nám chybí zejména muži, ale každé vyplnění je pro nás velmi cenné. Předem děkujeme všem za zapojení se.