In [9]:
%matplotlib inline
import matplotlib.pyplot as pl
dece=allregio[3]
for i in [8,2,3,10]:
sel=allregio[0]==i
pl.semilogy(dece[sel],label=rnames[i-1])
pl.grid()
pl.xlabel("days")
pl.legend()
Out[9]:

Opět bereme data ze záznamů italských statistiků, tentokráte za celé regiony, počítat budeme ale přímo oběti (tento počet se narozdíl od jiných vyvíjí nezávisle na intenzitě testování). Pokusil jsem se úlohu sestavit tak, aby šla řešit jako lineární problém, tedy analyticky maticovým aparátem. Výhodou je, že nejsme závislí na dobrém odhadu počátečních hodnot - výsledek této analýzy lze použít jako vstup složitějšího nelineárního modelu.
import numpy as np
dat=np.load("select_regio.npz",allow_pickle=True)
allregio=dat['arr_0']#.reshape(1)[0]
rnames=[a for a in dat['arr_1'] if len(a)>0]#.reshape(1)[0]
%matplotlib inline
import matplotlib.pyplot as pl
dece=allregio[3]
for i in [8,2,3,10]:
sel=allregio[0]==i
pl.semilogy(dece[sel],label=rnames[i-1])
pl.grid()
pl.xlabel("days")
pl.legend()
Nezávislou proměnnou je čas (ve dnech). Exponenciální nárůst zde byl postrachem všech epidemiologů. Pokud by trval, v logaritmické škále by sledované počty rostly lineárně. Vlivem různých opatření (a změny chování obyvatel) se sklon v log. škále postupně snižoval. První možností, jak tomu uzpůsobit použitý model, je změnit lineární trend na kvadratický (přidání kvadratického členu).
sel=allregio[0]==8 #Emilia Romagna
zmax=sum(sel)
fmax=30
x=np.r_[4:zmax]
pl.plot(x,np.log(dece[sel][4:]))
z=np.polyfit(x[:fmax-4],np.log(dece[sel][4:fmax]),2)
pl.plot(x,np.polyval(z,x))
pl.grid()
pl.ylabel("log(deaths)")
pl.title('quadratic fit')

Zdá se, že to funguje jen v na krátkém úseku grafu a zjevně nám nedává možnost předpovídat do budoucna.
Lepší volbou bude předpokládat přibližování se nějaké mezní hodnotě $l_m$ - průběh přibližování může být opět exponencielou, nyní se záporným exponentem $$\log(y)=l_m-l_0\ \exp(-l_1\ x).$$
Zvolíme (odhadneme) nějakou hodnotu $l_m$ a vyneseme proměnnou $z=\log(l_m-\log(y))$, která by v tomto modelu měla být lineární funkcí $x$.
sel2=x<45
lmax=8.5
x2=x[sel2]
y2=dece[sel][4:][sel2]
pl.plot(x2,np.log(lmax-np.log(y2)))

Volbu mezní hodnoty $l_m$ lze se (iterativní cestou) vylepšit tak, aby se tato závislost $z$ na $x$ co nejvíce podobala přímce - optimalizujeme na hodnotu reziduální sumy čtverců po tomto fitu (funkce chi2lin níže). Hodnota se liší o 0.25 od původního odhadu.
from scipy import optimize as op
def chi2lin(l):
ys=np.log(l-np.log(y2))
idx=np.polyfit(x2,ys,1)
return sum((ys-np.polyval(idx,x2))**2)
lbest=op.fmin(chi2lin,[8])[0]
ys=np.log(lbest-np.log(y2))
idx=np.polyfit(x2,ys,1)
pl.plot(x2,np.log(lbest-np.log(y2)))
pl.plot(x2,idx[1]+idx[0]*x2)
lbest
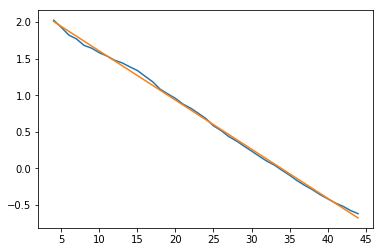
Korektní řešení problému musí zohlednit i nejistoty/rozptyl zadaných hodnot (v podobě váhové matice). Problémem je, že transformací se mění původní rozdělení veličiny na mnohdy výrazně asymetrické. Podíváme se na to blíže v numerickém experimentu...
Simulovaný vzorek $10^4$ měření se střední hodnotou 7. Pokud bychom chtěli aplikovat pravidlo pro transformaci proměnných, museli bychom diskrétní rozdělení aproximovat nějakým spojitým. Učinili jsme pokus s $\Gamma$ a normálním rozdělením.
jn=7
from scipy import stats as st
sm1=st.poisson(jn).rvs(10000)
pl.hist(sm1,np.r_[:20]);
bpars=st.gamma.fit(sm1);
pl.plot(np.r_[:20],st.gamma(*bpars).pdf(np.r_[:20])*1e4)
npars=st.norm.fit(sm1);
pl.plot(np.r_[:20],st.norm(*npars).pdf(np.r_[:20])*1e4)
pl.legend(["norm. rozdel.","gamma rozdel.","y"])
bpars

Po zlogaritmování rozptyl nové proměnné $t=\log(y)$ bude $D(t)=D(y)/y^2$, pokud jde o Poissonovská data (D(y)=y), pak D(t)=1/y, váhová matice na diagonále má tedy hodnoty rovné měřeným hodnotám. Správně by byla předpokládaná hodnota rozptylu rovna očekávané hodnotě $y$, což by měla být velikost modelu v daném bodě $x$ (pokud je model správný) - pak by ovšem váhová matice závisela na parametrech modelu, tím pádem by se problém nedal řešit přímo analyticky (sada podmínek na první derivace sumy čtverců reziduí by nebyla sadou lineárních rovnic).
sm1s=sm1[sm1>0]
zoo=st.norm(0.,0.1).rvs(len(sm1s)) #blurring
pl.hist(np.log(sm1s)+zoo,np.r_[1:3:0.1]);
pl.title("distrib. log(y)");

sig2=np.std(np.log(sm1s))
print('sigma testovaci sady:',sig2)
print('teoreticka hodnota',1/np.sqrt(jn))
Další transformací $\log\ y \to z$ se rozdělení opět změní...
lx=lbest
pl.hist(np.log(lx-np.log(sm1s))+zoo,np.r_[1.2:2.3:0.04]);
sig3=np.std(np.log(lx-np.log(sm1s)))
print('sigma testovaci sady:',sig3)
print('teoreticka hodnota',(1/jn**0.5/(lx-np.log(jn))))
pl.title("distrib. z=log(l_m-log(y))")
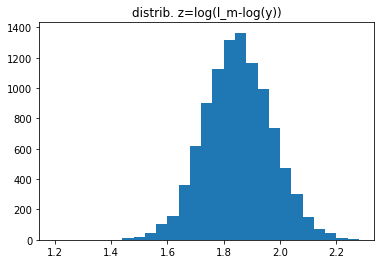
#vypocet z rozdeleni velic. t
mn2=np.mean(np.log(sm1s))
sig2/(lx-mn2)
Hodnoty rozptylu spočítané z testovacího vzorku tedy neodpovídají zcela pravidlu $$\sigma^2_t=\sigma^2_y \left(\frac{\partial t}{\partial y}\right)^2$$ - důvodem je hlavně asymetrie rozdělení. Uvedený vztah se odvozuje z Taylorova rozvoje jen do 1. řádu, zde už mají vliv i vyšší derivace. Pro řádový odhad je ale toto pravidlo dostatečné.
V logaritmické škále použití váhy $w=1/\sigma=\sqrt{y}$ dá výsledek dosti blízký fitování zcela bez vah.
pl.plot(x2,np.log(y2))
ind2=np.polyfit(x2,np.log(y2),2)
ind2w=np.polyfit(x2,np.log(y2),2,w=np.sqrt(y2))
pl.plot(x2,np.polyval(ind2,x2),label="bez vah")
pl.plot(x2,np.polyval(ind2w,x2),label="s vahami")
pl.grid()
pl.ylabel("log(deaths)")
pl.title('quadratic fit')
pl.legend();

Výpočet s vahami v explicitním maticovém zápise:
xp=np.r_[:len(y2)]
wmat2=np.eye(len(y2))
wmat2[xp,xp]=y2 # 1/D(ys)
amat2=np.array([np.ones_like(x2),x2,x2**2]).T
hess2=amat2.T@wmat2@amat2
par2=np.linalg.inv(hess2)@amat2.T@wmat2@np.log(y2)
res2=np.log(y2)-amat2@par2
chi2=res2@wmat2@res2
par2,chi2
Kovarianční matice ukazuje silnou míru koerelace.
cov2=np.linalg.inv(hess2)
err2=np.sqrt(cov2.diagonal())
err2,cov2/err2[:,np.newaxis]/err2[np.newaxis,:]
Nejistoty parametrů opravíme o odhad $\sigma$ získaný ze sumy čtverců reziduí a počtu stupňů volnosti (zde určujeme 3 parametry).
sigma2=chi2/(len(y2)-2)
np.sqrt(sigma2)
Hodnota je blízká jedné tj. hypotéza Poissonovsky rozdělené veličiny (a spočtené nejistoty pro odvozené veličiny) zjevně neyla daleko od pravdy.
Pokud vezmeme tuto hypotézu za danou, můžeme testovat goodness-of-fit daného modelu, tedy jestli spočtené chi2 nepřekračuje kvantil $\chi^2$ rozdělené s příslušnou hladinou významnosti. Pro dof=39 dostáváme tyto hodnoty:
from scipy import stats as st
dof=len(y2)-2
qvant=np.r_[0.05,0.01,0.002]
for a,b in zip(qvant,st.chi2(dof).isf(qvant)):
print('%.1f%%: %.2f'%(100*(1-a),b))
Pro naši hodnotu 63.4 lze tedy uvedený model na hladině významnosti 99% (s 1% rizikem, že je model správný a takto vysokou hodnotu jsme dostali "náhodou") zamítnout. Alternativním vysvětlením ale může být i to, že neplatí hypotéza o poissonovském rozdělení měřených hodnot.
Vynechána je část výpočtu, která bude vaším zápočtovým úkolem... Podíváme se teď na určení nejistoty parametru $l$...
def chi2lin(l):
ys=np.log(l-np.log(y2))
idx=np.polyfit(x2,ys,1)
return sum((ys-np.polyval(idx,x2))**2)
#lbest=op.fmin(chi2lin,[8])[0]-
ys=np.log(lbest-np.log(y2))
idx1=np.polyfit(x2,ys,1)
dif1=lambda l:l-np.exp(np.polyval(idx1,x2))-np.log(y2)
dif2=lambda l:l-np.exp(np.polyval(np.polyfit(x2,np.log(l-np.log(y2)),1),x2))-np.log(y2)
Nejistotu určení parametru $l$ zjistíme z druhé derivace (zde difference druhého řádu) minimalizované veičiny ($\chi^2$) v závislosti na $l$. Pokud necháme ostatní parametry konstatní (řez funkcí 3 parametrů), bude se $\chi^2$ měnit podstatně rychleji (modrá křivka níže), než když minimalizujeme v každém bodě $l$ funkci i vzhledem k ostatním parametrům (pohybujeme se podél "údolí" - hlavní osy elips - kontur minimalizované funkce).
wmat=np.eye(len(wmat))
chi1=lambda l:dif1(l)@wmat@dif1(l)
dd=0.01
fvar=np.r_[1.-dd:1.+dd:31j]
profl1=[chi1(lbest*f) for f in fvar]
chi2=lambda l:dif2(l)@wmat@dif2(l)
#fvar=np.r_[1.-dd:1.+dd:31j]
profl2=[chi2(lbest*f) for f in fvar]
pl.plot(lbest*fvar,profl1)
pl.plot(lbest*fvar,profl2)
pl.xlabel('l limit')
pl.ylabel('chi2')
pl.legend(['cut','minimize'])

Hodnota nejistoty je spočtena, jak jsme zvyklí, z převrácené hodnoty druhé derivace - rychle se měnící funkce určuje polohu minima přesněji než "plochá" varianta. Jako nejistotu $l_m$ budeme ale brát to druhé číslo - z derivace "podél údolí".
ip=15
it=5
der2=[(prof[ip-it]+prof[ip+it]-2*prof[ip])/(dd*lbest*it)**2*ip**2 for prof in [profl1,profl2]]
sig2=1/np.sqrt(der2)
sig2
Předpověď modelu v bodě $x_e$ pak je dána $y_e=\exp(p_2\ x_e^2 + p_1\ x_e + p_0)$, nejistota pak pomocí vektoru parciálních derivací $$D_i=\frac{\partial y_e}{\partial p_i}$$ se spočte pomocí kovarianční matice $V$ těchto parametrů
$$D(y_e)=D^T\ V\ D$$
x_e=40
D=[1,x_e,x_e**2]
cov2=np.linalg.inv(hess2)
sig_ye=np.sqrt(D@cov2@D)
sig_ye
V případě polynomu jsou parciální derivace rovny prislušným mocninám, resp. prvkům modelové matice. Pokud polynomem fitujeme logaritmus $y$, pak dostáváme relativní nejistoty.
Na grafu jsme pro srovnání vynesli (červeně) i "nejistotu" modelu bez započítání korelací mezi parametry (pokud vezmeme pouze diagonální členy kovarianční matice) - je vidět, že dostáváme hodnoty až 30x vyšší.
#wmat2=np.eye(len(y2))
#wmat2[xp,xp]=y2 # 1/D(ys)
xf=np.r_[1:45]
amat2=np.array([np.ones_like(xf),xf,xf**2])
yf=np.exp(amat2.T@par2)
resig2_yf=(amat2*(cov2@amat2)).sum(0)
pl.xlabel('days')
pl.ylabel("model uncertainty");
pl.plot(np.sqrt(resig2_yf)*yf)
pl.twinx();
cov2d=cov2*np.eye(len(cov2))
resig2_df=(amat2*(cov2d@amat2)).sum(0)
pl.plot(np.sqrt(resig2_df)*yf,'r')
pl.ylabel("model unc. [correlation removed]");

pl.plot(x2,y2)
#pl.plot(x,dece[sel][4:])
sig_yf=np.sqrt(resig2_yf*sigma2)*yf
sig_yf_sm=np.sqrt((resig2_yf*yf**2+yf)*sigma2)
pl.plot(xf,yf)
pl.fill_between(xf,yf-sig_yf_sm*3,yf+sig_yf_sm*3,alpha='.2')
pl.fill_between(xf,yf-sig_yf*3,yf+sig_yf*3,alpha='.4')
pl.xlabel('days')
pl.title('3-sigma band')
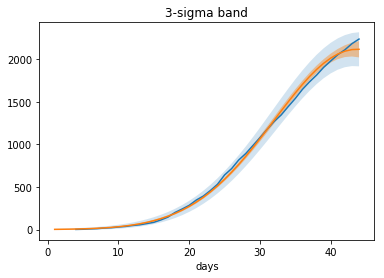
Poslední graf ukazuje 3-sigma pás kolem modelu - oranžově samotnou nejistotu modelu, modře pak kombinovanou s (poissonovským) rozptylem jednotlivých měřených bodů - v aproximaci normálním rozdělením očekáváme, že pouze 0.3% naměřených hodnot bude ležet mimo tento pás.