In [9]:
%matplotlib inline
from matplotlib import pyplot as pl
y1=ydata(x)
par1=cov.dot(amat.dot(y1))
pl.plot(x,y1-par1[0]*x-par1[1],'x')
pl.title("residuals")
pl.grid()

nlev šumu (normálně rozdělená data) import numpy as np
global ares1,ares2
a0,b0=3.,4.
nlev=0.2
x=np.r_[:4:41j][1:]
ydata=lambda x:x*a0+b0+np.random.normal(0,nlev,size=x.shape)
hess=np.array([[sum(x**2),x.sum()],[x.sum(),len(x)]])
amat=np.array([x,x/x])
cov=np.linalg.inv(hess)
ares1=np.zeros_like(x)
ares2=np.zeros_like(x)
def ahat(y):
global ares1,ares2
pars=cov.dot(amat.dot(y))
vres=y-amat.T.dot(pars)
ares1+=vres
ares2+=vres**2
s0=(vres**2).sum()
return list(pars)+[s0]
pars=np.array([ahat(ydata(x)) for i in range(1000)])
print("prum. hodnota 1000 op. (pars+chi2)")
pars.mean(0)
#ahat(ydata(x))
Průměrná hodnota parametrů se liší minimálně o pravé hodnoty $[3,4]$. Poslední číslo je suma čtverců reziduí, očekávaná hodnota je $(n-2)\ \sigma^2=1.52$.
%matplotlib inline
from matplotlib import pyplot as pl
y1=ydata(x)
par1=cov.dot(amat.dot(y1))
pl.plot(x,y1-par1[0]*x-par1[1],'x')
pl.title("residuals")
pl.grid()
Průměr a směrod. odchylka reziduí v každém ze 40 bodů - rezidua jsou konstantní a jejich rozptyl také.
stres=ares2/1000-(ares1/1000)**2
pl.errorbar(x,ares1/1000,np.sqrt(stres))
pl.grid()
pl.title("residual distribution")

Rozdělení sumy čtveců reziduí by mělo odpovídat $\chi^2_{(n-k)}$, kde $n-k=38$ je počet stupňů volnosti.
pl.hist(pars[:,2],30)
pl.xlabel("chi2 distribuce")

Porovnání (kumulativní) distribuční funkce s teoretickou (Kolmogorovův test):
from scipy import stats
chi2=stats.chi2(len(x)-2)
pl.plot(np.r_[:60]*nlev**2,chi2.cdf(np.r_[:60]))
zchi2=np.sort(pars[:,2])
pl.plot(zchi2,np.r_[:1:1j*len(zchi2)])
pl.legend(["teoret. chi2","numer. experiment"])
pl.grid()
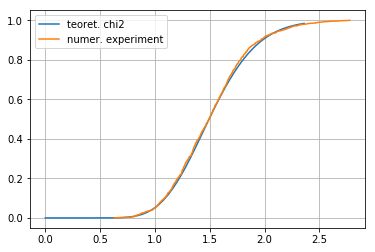
Velikost rozptylu měřených hodnot - téměř totéž co rozptyl reziduí - odhadujeme (pokud ji neznáme předem) z podílu $\chi_2/(n-k)$. Jak je z rozdělení vidět, pro některé "vzorky" můžeme dostat dosti odlišné hodnoty od vstupní $\sigma^2=0.04$.
Fitováním na celou sadu 1000 vzorků ověříme, zda $\sigma$ určená ze sumy čtvercu reziduí odpovídá hodnotě nlev vstupující do simulace...
from scipy import optimize as op
op.fmin(lambda p:stats.kstest(pars[:,2],stats.chi2(len(x)-2,scale=p).cdf).statistic,[nlev**2])
pl.plot(pars[:,0],pars[:,1],'.')
pl.title("1000 opakovani")
pl.xlabel("slope")
pl.ylabel("offset")

errs=np.sqrt(cov.diagonal())
print("teorie - kovarianční matice: stderr*noise level:",errs*nlev)
print("simulace - směrod.odchylka rekonstr. parametrů :",pars.std(0)[:2])
# simulovaná korelační matice
np.corrcoef(pars[:,0],pars[:,1])
cov/errs[:,np.newaxis]/errs[np.newaxis,:]
pro konkrétní sadu dat $y_1$ budeme měnit parametry $a, b$ faktorem 0.9 - 1.1 - suma reziduí by na nich měla záviset formou dvourozměrné paraboly - $a_0, b_0$ je odhad parametrů = poloha minima.
$$\chi^2(a,b)=\frac{1}{1-\rho^2}\left[\frac{(a-a_0)^2}{\sigma^2_a} -2\rho \frac{(a-a_0)(b-b_0)}{\sigma_a\sigma_b} + \frac{(b-b_0)^2}{\sigma^2_b} \right]$$
res2act=lambda ab:y1-par1[0]*(1+ab[0])*x-par1[1]*(1+ab[1]) # rezidua
chi2act=lambda ab:(res2act(ab)**2).sum() #chi 2
ndiv=21
gsiz=0.1
ab0=np.mgrid[-gsiz:gsiz:1j*ndiv,-gsiz:gsiz:1j*ndiv].swapaxes(0,2).reshape(ndiv*ndiv,2)
smap=np.array([chi2act(p) for p in ab0]).reshape(ndiv,ndiv)
pl.imshow(smap,extent=[1-gsiz,1+gsiz,1-gsiz,1+gsiz],origin="lower")
pl.xlabel('slope /a/')
pl.ylabel('offset /b/')
pl.colorbar()

Kvadratický profil je nejlépe vidět na řezech - např. při konstantním $a$. Je zřejmé, jak se posouvá poloha minima = teoretický průběh při zafixování $a=a_0+c$ je $$\chi^2(b\ |\ a=a_0+c) = \frac{1}{1-\rho^2}\left[\frac{c^2}{\sigma^2_a} -2\rho \frac{c\ (b-b_0)}{\sigma_a\sigma_b} + \frac{(b-b_0)^2}{\sigma^2_b} \right] =$$ $$=\frac{1}{1-\rho^2} \left[ \frac{(b-b_0-c\rho\sigma_b/\sigma_a)^2}{\sigma^2_b} + \frac{c^2\ (1-\rho^2)}{\sigma^2_a}\right].$$
Poloha minima se tak posouvá úměrně $c$ faktorem $\rho\sigma_b/\sigma_a$ - v našem případě je $\rho$, takže s rostoucím $a$ klesá.
Druhý zlomek v závorce ukazuje, jak se mění $\chi^2$ podél "údolí" minima, tedy když první zlomek je nulový = opět jde o parabolu, druhá derivace podle $c$ (totéž co podle $a$) je rovna $1/sigma_a^2$, tedy nejistota odhadu proměnné $a$ je $sigma_a$: pro každou hodnotu $a=a_0+c$ hledáme nejmenší možnou hodnotu $\chi^2$ prohledáváním všech možných $b$.
Pokud by $b$ bylo fixní, je (analogicky podle vzorce výše, jen se záměnou $a \leftrightarrow b$, 2.derivace rovna $1/sigma_a^2/(1-\rho^2)$, tedy nejistota se zmenší faktorem $(1-\rho)$. Pokud určujeme dvě (či více) korelovaných veličin zároveň, jsou jejich nejistoty větší, než pokud můžeme jednu (či více) z nich zafixovat (určit nějakým jiným měřením). Korelace způsobuje, že se můžeme pohybovat podél "pozvolnějšího" údolí - nárůst $\chi^2$ podél jedné osy můžeme kompenzovat pohybem podél druhé osy - druhé korelované proměnné.
Následující graf ukazuje takovéto řezy (a pohyb minima).
for k in [0,ndiv//2,ndiv-1]:
pl.plot(par1[1]*(1+ab0[k::ndiv,1]),smap[k],label="slope=%.3f"%(par1[0]*(1+ab0[k,0])))
pl.ylabel("chi2")
pl.xlabel("offset")
pl.legend()

Pokusíme se proložit mapu $\chi^2$ 2-rozměrnou parabolou (je to opět aplikace lineárního modelu v trochu komplikovanější situaci)...
amat=np.array([ab0[:,0]**2,ab0[:,1]**2,ab0[:,0]*ab0[:,1]])
nhess=amat.dot(amat.T)
nhess
px=np.linalg.inv(nhess).dot(amat).dot(smap.ravel()-smap.min())
px
Koeficienty jsou $p_a=D/\sigma_a^2$, $p_b=D/\sigma_b^2$ a $p_{ab}=2D \rho/\sigma_a \sigma_b$, kde $D=1/(1-\rho^2)$, odtud můžeme dopočítat např. korelační koeficient jako $p_{ab}^2 / p_a p_b=4\rho^2$.
rho=px[2]/np.sqrt(px[0]*px[1])/2.
Dd=1/(1-rho**2)
np.sqrt(Dd/px[0]),np.sqrt(Dd/px[1]),rho
Analýzu minima rozdělení chi2 (funkce chi2act) můžeme shrnout do jedné funkce:
def min_scan(ndiv=21,gsiz=0.1):
#chi2act=lambda ab:(res2act(ab)**2).sum()
ab0=np.mgrid[-gsiz:gsiz:1j*ndiv,-gsiz:gsiz:1j*ndiv].swapaxes(0,2).reshape(ndiv*ndiv,2)
amat=np.array([ab0[:,0]**2,ab0[:,1]**2,ab0[:,0]*ab0[:,1]])
nhess=amat.dot(amat.T)
smap=np.array([chi2act(p) for p in ab0]).reshape(ndiv,ndiv)
#nhess
px=np.linalg.inv(nhess).dot(amat).dot(smap.ravel()-smap.min())
rho=px[2]/np.sqrt(px[0]*px[1])/2.
Dd=1/(1-rho**2)
return np.sqrt(Dd/px[0])*par1[0],np.sqrt(Dd/px[1])*par1[1],rho
min_scan()
Ve skutečnosti nepotřebujeme podrobnou mapu, stačí nám na určení 3 parametrů mnohem méně bodů:
#s mnohem méně body
min_scan(ndiv=3,gsiz=0.3)
Poslední prvek je korelace, ktera odpovídá předpovědi z kovarianční matice cov.
Porovnání prvních dvou (relativní nejistoty) se skutečnými dává velmi dobrou shodu.
V eliptické metrice můžeme určovat vzdálenost bodu od "pravé" hodnoty pomocí vzorce analogického vztahu pro $\chi^2$ (pro $\rho=0$, $\sigma_a=\sigma_b$ přechází na prostou kartézskou vzdálenost). Tyto vzdálenosti (přesněji čtverce vzdáleností) mají rozdělení $\chi^2_2$ (tedy 2 stupně volnosti). Zde je uplatněn faktor $1/\sigma^2$.
zpars=pars[:,:2]-np.r_[a0,b0][np.newaxis,:]
dst=(zpars[:,:2].dot(hess)*zpars[:,:2]).sum(1)
np.median(dst)
pl.hist(dst/nlev**2,30)
op.fmin(lambda p:stats.kstest(dst/nlev**2,stats.chi2(2,scale=p).cdf).statistic,[1])

1-stats.chi2(3).cdf(9)
stats.chi2(3).isf(0.01)
dst.mean()/nlev**2