In [2]:
# renormalizovane mereni
m1, m2 = measure(2000,frac=0.7)
plot(m1,m2,'.')
m1.std(),m2.std()
Out[2]:
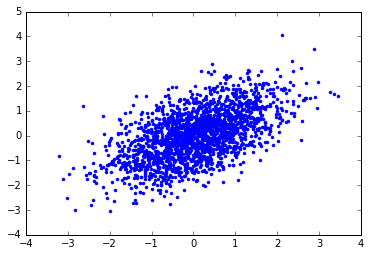
body ze sady 2 proměnných definují eliptickou oblast
budeme se detailněji zabývat analýzou této elipsy
%matplotlib inline
from matplotlib.pyplot import plot,hist
import numpy as np
from scipy import stats
def measure(n,frac=0.5,norm=True):
"Measurement model, return two coupled measurements."
l1 = np.random.normal(size=n)
l2 = np.random.normal(scale=0.5, size=n)
rep=l1+frac*l2, frac*l1-l2
if norm:
rep=[rep[0]/rep[0].std(),rep[1]/rep[1].std()]
return rep
# renormalizovane mereni
m1, m2 = measure(2000,frac=0.7)
plot(m1,m2,'.')
m1.std(),m2.std()
# korelacni koeficient je zde roven dot(m1,m2)
r=0.3
dd=measure(1000,r)
#skut. korel. koeficient vs. hodnota se zadanymi E(x), V(x)
np.corrcoef(*dd)[0,1],np.array(dd).prod(0).sum()/999.
m1, m2 = measure(2000,frac=0.5)
# mereni vzdalenosti v elipticke metrice
rep=hist(np.sqrt(m1**2+m2**2-m1*m2*0.5*2),30)
from matplotlib import pyplot as pl
pl.xlabel("vzdalenost od stredu")

plot(rep[1][1:],np.cumsum(rep[0])/2000,'d')
pl.grid()
pl.xlabel("kumul.dist.")
pl.title("kovariance")

np.corrcoef(m1,m2)[0][1]
rep1=hist(abs(m1),30)
pl.xlabel("vzdal. od pocatku ve smeru X")
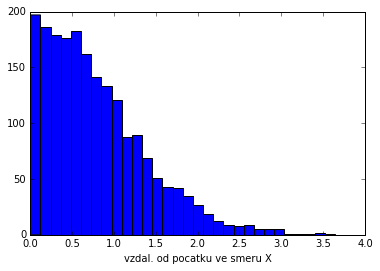
# porovnani kupulativnich distribuci
plot(rep[1][1:],np.cumsum(rep1[0])/2000,'+')
plot(rep[1][1:],np.cumsum(rep[0])/2000,':')
grid()
pl.xlabel("kumul. vzdalenost")
pl.legend(["1-rozmerne","2-rozmerne"],loc=4)

rozdělení do tříd podle proměnné $m_1$ i $m_2$ vycházejí identicky (standardizované NP na průměr 0 a rozptyl 1)
#pouzivame balik NDImage pro rozdeleni dat do skupin
from scipy import ndimage as ni
ysum=ni.sum(m2,(m1*5.).astype(int),range(-12,13))
ymean=ni.mean(m2,(m1*5.).astype(int),range(-12,13))
ystd=ni.standard_deviation(m2,(m1*5.).astype(int),range(-12,13))/np.sqrt(ysum/ymean)
ysum2=ni.sum(m1,(m2*5.).astype(int),range(-12,13))
ymean2=ni.mean(m1,(m2*5.).astype(int),range(-12,13))
ystd2=ni.standard_deviation(m1,(m2*5.).astype(int),range(-12,13))/np.sqrt(ysum2/ymean2)
from matplotlib.pyplot import errorbar
errorbar(np.arange(-12,13)/5.,ymean,ystd)
errorbar(np.arange(-12,13)/5.,ymean2,ystd2)
pl.grid()
pl.legend(["m1 vs. m2","m2 vs. m1"],loc=2)

proložení přímkou dá tento sklon
np.polyfit(np.arange(-12,13)/5.,ymean2,1,w=1/ystd2)
zkusíme totéž zautomatizovat pro různé míry korelace
# analyza z prumetu
def analelli(r,siz=2000,plot=False,nsig=2.2,div=5.):
m1, m2 = measure(siz,frac=r)
ipts=range(-int(nsig*div),int(nsig*div)+1)
ysum=ni.mean(m2,(m1*div).astype(int),ipts)
ymean=ni.mean(m2,(m1*div).astype(int),ipts)
ystd=ni.standard_deviation(m2,(m1*div).astype(int),ipts)/np.sqrt(ysum/ymean)
ysum2=ni.sum(m1,(m2*div).astype(int),ipts)
ymean2=ni.mean(m1,(m2*div).astype(int),ipts)
ystd2=ni.standard_deviation(m1,(m2*div).astype(int),ipts)/np.sqrt(ysum2/ymean2)
pts=np.arange(-nsig*div,nsig*div+1)/5.
if plot:
from matplotlib.pyplot import errorbar
errorbar(pts,ymean,ystd)
errorbar(pts,ymean2,ystd2)
f1=np.polyfit(pts,ymean,1,w=1/ystd)
f2=np.polyfit(pts,ymean2,1,w=1/ystd2)
return f1,f2
# simulace pro ruzne korelacni koef.
ook=[analelli(r,5000) for r in np.r_[-0.5:0.9:0.1]]
rs=np.r_[-0.5:0.9:0.1]
plot(rs,np.array(ook)[:,0,0],'+',ms=13)
plot(rs,np.array(ook)[:,1,0],'r+',ms=13)
pl.grid()
pl.xlabel("korel. koeficient")
pl.ylabel(u"sklon průměrovaných dat")
pl.legend(["m1 vs m2","m2 vs m1"],loc=2)
pl.xlim(-.6,1)

závislost není lineární = generovaná data nedosahují požadované míry korelace pro velké (absolutní) hodnoty $r$
opravíme výpočtem skutečných korelačních koeficientů
#vypocteme skutečné korelační koeficienty (průměr z 30 opakování)
cook=np.array([[np.array(measure(1000,r)).prod(0).sum()/999. for r in np.r_[-0.5:0.9:0.1]] for i in range(30)])
cavg=cook.mean(0)
plot(cavg,np.array(ook)[:,0,0],'+',ms=10)
plot(cavg,np.array(ook)[:,1,0],'r+',ms=10)
pl.grid()
pl.xlabel("korel. koef. skutecny")
pl.ylabel("sklon průměrovaných dat")
pl.legend(["m1 vs m2","m2 vs m1"],loc=2)
pl.xlim(-.6,.8)

# nyní vychází sklon skoro přesně
np.polyfit(cavg,np.array(ook)[:,0,0],1)
kontury konstantní hustoty jsou elipsy
zpracování konturového grafu je v NumPy trochu náročnější
m1, m2 = measure(100000,0.7)
siz=14.5/4.
bins=np.r_[-siz:siz:30j]
out=np.histogram2d(m1,m2,[bins,bins])
from matplotlib.pyplot import imshow,contour
con1=contour(out[0],origin="lower",extent=[-siz,siz,-siz,siz])
pl.grid()
pl.xlabel("m1")
pl.ylabel("m2")

col1=con1.collections[1].get_paths()[0]
ix,iy=np.array([i[0] for i in col1.iter_segments() if i[1]==2]).transpose()
modelujeme
$$r(\alpha)=r_m+d \cos 2(\alpha - \alpha_0)=r_m+d \cos 2\alpha \cos 2\alpha_0 - d \sin 2\alpha \sin 2\alpha_0 $$následuje cvičení na aplikaci lineární regrese
#nafitujeme pomocí lineární regrese
r=np.sqrt(ix**2+iy**2)
ang=np.arctan2(iy,ix)
plot(ang,r,"d")
mat=np.array([np.ones(r.shape),np.cos(2*ang),np.sin(2*ang)])
mcov=np.linalg.inv(mat.dot(mat.T))
coef=mcov.dot(mat.dot(r))
plot(ang,coef.dot(mat))
pl.xlabel("uhel [rad]")
pl.ylabel("vzdal. od středu")
pl.legend(["data","fit"])
coef

#plot(ix,iy)
rn=coef.dot(mat)
ixn=rn*np.cos(ang)
iyn=rn*np.sin(ang)
plot(ixn,iyn)

# schovame vse do procedury
def contal(con1,itr=2,choice=2,doplot=False):
col1=con1.collections[itr].get_paths()[0]
ix2,iy2=np.array([i[0] for i in col1.iter_segments() if i[1]==choice]).transpose()
#plot(ix2,iy2)
r=np.sqrt(ix2**2+iy2**2)
ang=np.arctan2(iy2,ix2)
if doplot:plot(ang,r,"d")
mat=np.array([np.ones(r.shape),np.cos(2*ang),np.sin(2*ang)])
mcov=np.linalg.inv(mat.dot(mat.T))
coef=mcov.dot(mat.dot(r))
if doplot:
plot(ang,coef.dot(mat))
pl.grid()
return coef
contal(con1,2,doplot=True)

m1, m2 = measure(100000,0.3)
siz=14.5/4.
bins=np.r_[-siz:siz:30j]
out=np.histogram2d(m1,m2,[bins,bins])
con2=contour(out[0],origin="lower",extent=[-siz,siz,-siz,siz])
aper=np.array([contal(con2,i) for i in range(1,5)])
print(np.arctan2(aper[:,2],aper[:,1])/np.pi*90)
pl.grid()
pl.title("2D histogram")
aper

X, Y = np.mgrid[-siz:siz:100j, -siz:siz:100j]
positions = np.vstack([X.ravel(), Y.ravel()])
values = np.vstack([m1, m2])
kernel = stats.gaussian_kde([m1,m2])
kde = np.reshape(kernel(positions).T, X.shape)
con3=contour(kde,origin="lower",extent=[-siz,siz,-siz,siz])
aper3=np.array([contal(con3,i) for i in range(1,5)])
print(np.arctan2(aper3[:,2],aper3[:,1])/np.pi*90)
aper3

sestrojíme model kdif pro 2-D gaussovo rozdělení
r=0.3
modkde=(X**2+Y**2-2*X*Y*r)/(1-r**2)
contour(np.exp(-modkde),origin="lower",extent=[-siz,siz,-siz,siz])
colorbar()
from scipy import optimize as op
hisx=kde
kdif=lambda p:(hisx-np.exp(-((X-p[2])**2+(Y-p[3])**2-2*(X-p[2])*(Y-p[3])*p[0])/(1-p[0]**2))*p[1])
rep=op.fmin(lambda p:sum(kdif(p).ravel()**2),[0.3,0.4,0,0])
rep

from matplotlib.pyplot import colorbar
con3=contour(kde,origin="lower",extent=[-siz,siz,-siz,siz])
contour(kde-kdif(rep),origin="lower",extent=[-siz,siz,-siz,siz])
colorbar()

for r in np.r_[0.1:0.8:0.1]:
m1, m2 = measure(100000,r)
out=np.histogram2d(m1,m2,[bins,bins])
his2=out[0]/len(m1)*(30/2./siz)**2
hisx=his2
M=(np.r_[-siz:siz:30j]+siz/30.)[:-1].reshape(29,1)
hdif=lambda p:(hisx-np.exp(-((M-p[2])**2+(M.T-p[3])**2-2*(M-p[2])*(M.T-p[3])*p[0])/(1-p[0]**2))*p[1])
rep2=op.fmin(lambda p:sum(hdif(p).ravel()**2),[r,0.2,0,0])
print(rep2)
#orientace elipsy
np.arctan2(aper[:,2],aper[:,1])/np.pi*180