In [3]:
%pylab inline
from scipy import stats
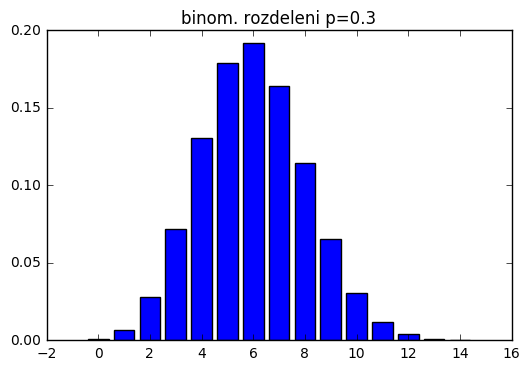
vals=stats.binom(20,0.3).pmf(r_[0:15])
bar(r_[0:15]-0.4,vals)
title("binom. rozdeleni p=0.3")
ax=vals[:4].sum()
vals[4],vals[:4].sum()
#stats.binom?
Out[3]:
frekventistické tvrzení má smysl, jen pokud lze experiment/událost opakovat!
literatura: Barlow, sec. 7.2
pracujeme s rozdělením pozorovaných hodnot pro danou hypotézu ($X_{\rm true}=X_u$), nikoli rozdělení skutečných hodnot $X_{\rm true}$ ...
Z 20 pozorování nám 4 vyšla pozitivně. Jaký je 95% interval pro pravděpodobnost pozitivního výsledku?
Pravděpodobnost se řídí binomickým rozdělením. Příklad pro pravděpodobnost úspěchu p=0.3 dává 13% pro pravděpod. daného výsledku, necelých 11%, že vyjde méně než 4.
%pylab inline
from scipy import stats
vals=stats.binom(20,0.3).pmf(r_[0:15])
bar(r_[0:15]-0.4,vals)
title("binom. rozdeleni p=0.3")
ax=vals[:4].sum()
vals[4],vals[:4].sum()
#stats.binom?
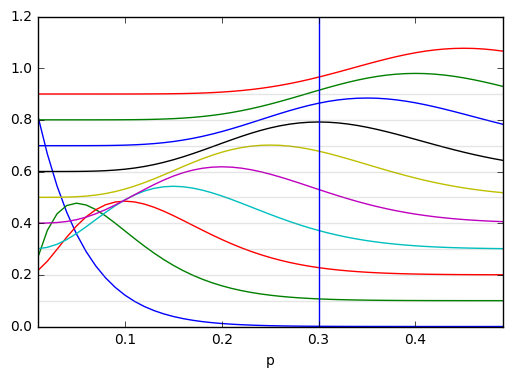
(přehledné) znázornění trojdim. grafu závislosti pravděpodobnosti na hodnotě $p$ a pozorované hodnotě $i$
x=r_[0.01:0.5:0.01]
for i in range(0,10):
axhline(.1*i,color='gray',alpha=0.2)#,xmax=x[-1])
plot(x,i*0.1+stats.binom(20,x).pmf(i))
axvline(.3)
xlim(x[[0,-1]])
xlabel("p")
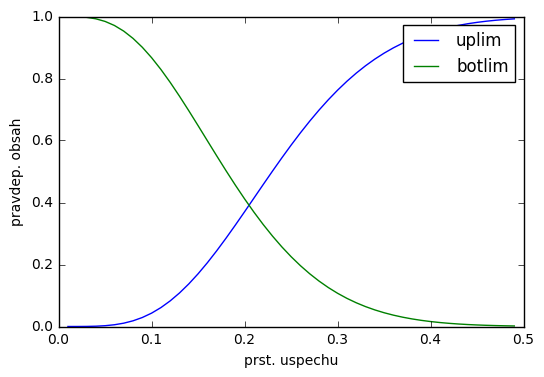
pro (předpoklad) různé hodnoty $p$ lze spočítat pravděpodobnosti, že vyjde méně než daný počet (botlim) nebo více než daný počet (uplim) pozitivních výsledků...
botlim=lambda p,k:stats.binom(20,p).cdf(k-1)
uplim=lambda p,k:1-stats.binom(20,p).cdf(k)
x=r_[0.01:0.5:0.01]
plot(x,[uplim(a,4) for a in x],x,[botlim(a,4) for a in x])
legend(["uplim","botlim"])
xlabel("prst. uspechu")
ylabel("pravdep. obsah")
Nyní zbývá najít řešení této tzv. Clopper-Pearson limity $$\sum_{r=m+1}^n P(r;p_+,n) = 0.975$$ $$\sum_{r=0}^{m-1} P(r;p_-,n) = 0.975$$ (tedy hodnoty $p_+, p_-$ jako horní a dolní mez konfidenčního intervalu).
Je to nejmenší/největší hodnota, která je "ještě kompatibilní" s naměřenou hodnotou - tedy nelze je s danou mírou rizika zamítnout.
# pozorovany 4 z 20
from scipy import optimize as op
xbt=op.fsolve(lambda p:botlim(p,4)-0.975,0.1)[0]
xup=op.fsolve(lambda p:uplim(p,4)-0.975,0.3)[0]
xbt,xup
#pozorovano 6 z 20
xbt6=op.fsolve(lambda p:botlim(p,6)-0.975,0.1)[0]
xup6=op.fsolve(lambda p:uplim(p,6)-0.975,0.4)[0]
xbt6,xup6
Tahle interpretace je jediná smysluplná, pokud narazíme na fyzikální meze skutečných hodnot parametru (často jen kladné hodnoty, někdy omezené shora).
počítáme vodorovně, odečítáme svisle
v každém řádku (pro danou hodnotu p) určíme kvantil binomického rozdělení
n=20
p=0.1
ptrue=r_[.0:1.01:0.025]
cont=0.25
xlo=[stats.binom(n,p).ppf(cont) for p in ptrue]
xlo[0]=0
xhi=[stats.binom(n,p).ppf(1-cont) for p in ptrue]
plot(xlo,ptrue,':')
plot(xhi,ptrue,':')
cont=0.025
xlo=[stats.binom(n,p).ppf(cont) for p in ptrue]
xlo[0]=0
xhi=[stats.binom(n,p).ppf(1-cont) for p in ptrue]
plot(xlo,ptrue)
plot(xhi,ptrue)
grid()
xlabel('pocet priznivych udalosti (z 20)')
ylabel('prst. uspechu v binom. rozdeleni')
axvline(20)

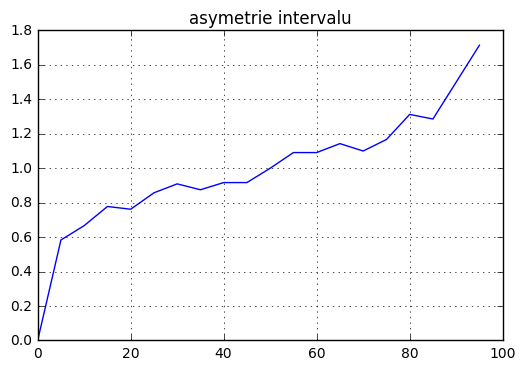
# linearni interpolace
from scipy import interpolate as ip
plim1=ip.interp1d(xhi,ptrue)
plim2=ip.interp1d(xlo,ptrue)
xps=r_[:100:5]
plot(xps,-(xps/100.-plim1(xps))/(xps/100.-plim2(xps)))
title("asymetrie intervalu")
grid()
xbtall=[op.fsolve(lambda p:botlim(p,i)-0.95,plim1(xps[i]))[0] for i in range(1,20)]
xupall=[op.fsolve(lambda p:uplim(p,i)-0.95,plim2(xps[i]))[0] for i in range(1,20)]
xps=r_[:20]
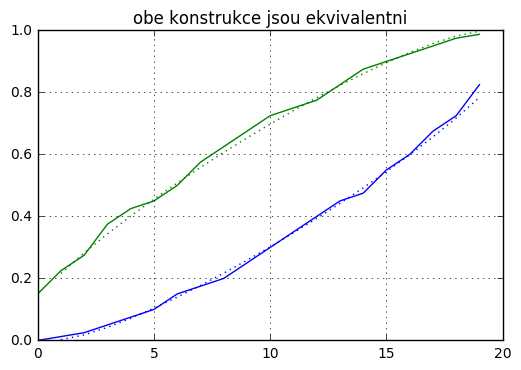
plot(xps[1:],xbtall,':')
plot(xps[1:],xupall,':')
plot(xps,plim1(xps),'b')
plot(xps,plim2(xps),'g')
grid()
i=5
title("obe konstrukce jsou ekvivalentni")
xps[i+1]
optimize.fsolve(lambda p:botlim(p,18)-0.975,0.6)[0]
Pro normální rozdělení je situace jednodušší díky symetrii integrálu (graf z obr. 2 dává ve směru obou os v řezu gaussovky).
Podmínka $$\int_x^{\infty}{\frac{1}{\sigma\sqrt{2\pi}} e^{-(x'-p_-)^2/2\sigma^2} dx'} =0.025$$ je ekvivalentní přímému výpočtu $$\int_{-\infty}^{p_-}{\frac{1}{\sigma\sqrt{2\pi}} e^{-(x'-x)^2/2\sigma^2} dx'} = \int_{-\infty}^{p_-+x}{\frac{1}{\sigma\sqrt{2\pi}} e^{-x''^2/2\sigma^2} dx''} = 0.025$$
konfidenční pás je pruh mezi rovnoběžnými přímkami (se sklonem 1, stejně vzdálené horizontálně i vertikálně).
xf=r_[:16:0.2]
qfun=stats.norm(20*0.3,sqrt(0.3*(1-0.3)*20))
bar(r_[0:15]-0.4,vals)
plot(xf,qfun.pdf(xf),'r')
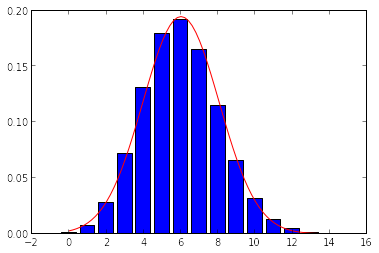
aproximace úvodního problému rozdělením $N(\mu=n p,\sigma^2=n p(1-p))$
#qfun2=stats.norm(8*0.5,sqrt(0.8*(1-0.5)*8))
qfun2=stats.norm(4,sqrt(4*(1-4./20)))
qfun2.ppf(0.05)/20,qfun2.isf(0.05)/20
# varianta prikladu 90% konfid. interval pri 4 uspesnych pokusech z 8
from scipy import optimize
botlimq=lambda p,k,nn:stats.binom(nn,p).cdf(k-1)
uplimq=lambda p,k,nn:1-stats.binom(nn,p).cdf(k)
xbtq=optimize.fsolve(lambda p:botlimq(p,4,8)-0.95,0.1)[0]
xupq=optimize.fsolve(lambda p:uplimq(p,4,8)-0.95,0.4)[0]
xbtq,xupq
pocitano z aproximace normalnim rozdelenim
qfun3=stats.norm(8*0.5,sqrt(0.8*(1-0.5)*8))
qfun3.ppf(0.1)/8,qfun3.isf(0.1)/8