In [2]:
%pylab inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = [10, 5]
from scipy import stats
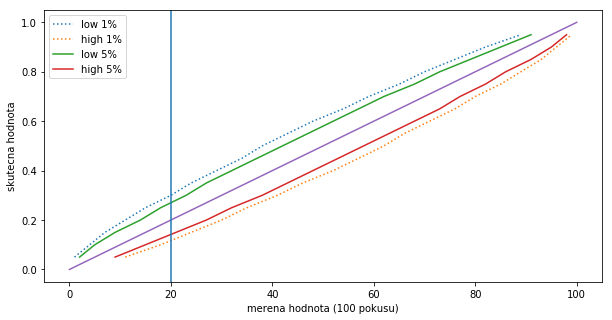
n=100
p=0.1
i=30
ptrue=r_[.05:1:0.05]
cont=0.01
xlo=r_[[stats.binom(n,p).ppf(cont) for p in ptrue]]
xhi=r_[[stats.binom(n,p).ppf(1-cont) for p in ptrue]]
plot(xlo,ptrue,':')
plot(xhi,ptrue,':')
cont=0.05
xlo=r_[[stats.binom(n,p).ppf(cont) for p in ptrue]]
xhi=r_[[stats.binom(n,p).ppf(1-cont) for p in ptrue]]
plot(xlo,ptrue)
plot(xhi,ptrue)
plot([0,100],[0,1.])
axvline(20)
xlabel("merena hodnota (100 pokusu)")
ylabel("skutecna hodnota")
legend(["low 1%","high 1%","low 5%","high 5%"])
Out[2]: