V předchozí kapitole jsme uvažovali pouze jeden znak $X$. Teď si nadefinujeme četnosti, které se budou týkat dvou znaků $X$ a $Y$, tyto četnosti se nazývají simultánní a tabulka, která obsahuje tyto četnosti, se nazývá kontingenční tabulka.
Simultánní četnost - mějme výběrový soubor o rozsahu $n$, znak $X$ s počtem variant $r$ a znak $Y$ s počtem variant $s$. Pro $j = 1, \dots, r$ a $k = 1, \dots, s$ definujeme:
Absolutní četnost dvojice $(x_{[j]},y_{[k]})$
$$n_{jk} = N (X = x_{[j]} \wedge Y = y_{[k]})$$
Relativní četnost dvojice $(x_{[j]},y_{[k]})$
$$p_{jk}= \frac{n_{jk}}{n}$$
Absolutní kumulativní četnost dvojic nepřesahujících $(x_{[j]},y_{[k]})$
$$N_{jk} = N (X \leq x_{[j]} \wedge Y \leq y_{[k]}) = \sum_{u\leq j} \sum_{v \leq k} n_{uv}$$
Marginální četnosti – četnosti jednotlivých znaků. Používáme tečkovou notaci, tečka stojí na místě znaku, podle něhož sčítáme. Do tabulky je píšeme do posledního sloupce nebo řádku.
$n_{j .} = n_{j1} +\dots+ n_{js}$
$n_{ . k} = n_{1k} +\dots+ n_{rk}$
$p_{j .} = p_{j1} +\dots+ p_{js}$
$p_{ . k} = p_{1k} +\dots+ p_{rk}$
$N_{j .} = n_{1 .} +\dots+ n_{j .}$
$N_{ . k} = n_{ . 1} +\dots+ n_{ . k}$
$F_{j .} = p_{1 .} +\dots+ p_{j .}$
$F_{ . k} = p_{ . 1} +\dots+ p_{ . k}$
Podmíněné relativní četnosti - relativní četnost může být sloupcově nebo řádkově podmíněná
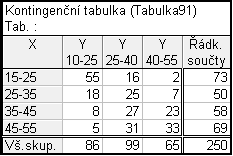
První řádek a první sloupec představují varianty znaků, vnitřní část tabulky je pak vyplněna simultánními četnostmi, poslední sloupec a poslední řádek vyplníme marginálními četnostmi. Podobně zavádíme tabulku i pro jiné druhy četností.
Simultánní četnostní funkce - funkce dvou reálných proměnných
$$p(x,y)= \begin{cases}
p_{jk}& \text{ pro } x=x_{[j]} \wedge y=y_{[k]}, j=1, \dots, r, k=1, \dots, s\\
0& \text{ jinak }
\end{cases}$$
Marginální četnostní funkce
$$p_1(x)= \begin{cases}
p_{j .}& \text{ pro } x=x_{[j]}, j=1, \dots, r\\
0& \text{ jinak }
\end{cases}$$
$$p_2(y)= \begin{cases}
p_{. k}& \text{ pro } y=y_{[k]}, k=1, \dots, s\\
0& \text{ jinak }
\end{cases}$$
Jestliže pro všechny dvojice $(x,y)$ z $\mathbb{R}^2$ platí vztah:
$$p(x,y) = p_1 (x) p_2 (y),$$
neboli pro všechna $j = 1, \dots, r$ a všechna $k= 1, \dots, s$ platí vztah:
$$p_{jk} = p_{j .} p_{. k},$$
pak můžeme říct, že znaky $X$ a $Y$ jsou četnostně nezávislé v daném výběrovém souboru.
Podmíněné četnostní funkce
Sloupcově podmíněná
$$p_{1/2} (x/y)=\begin{cases}
\frac{p(x,y)}{p_2(y)} & \text{ pro } p_2 (y)\neq 0\\
0 & \text{ jinak }
\end{cases}$$
Řádkově podmíněná
$$p_{2/1} (y/x)=\begin{cases}
\frac{p(x,y)}{p_1(x)} & \text{ pro } p_1 (x)\neq 0\\
0 & \text{ jinak }
\end{cases}$$
Příklad 2.1:
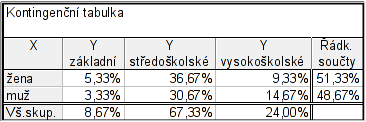
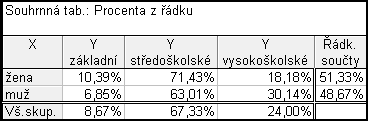
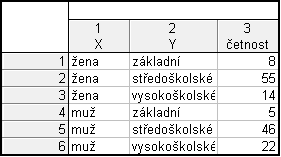
Ve firmě byl proveden průzkum, ve kterém se zjišťovalo pohlaví (znak $X$) a nejvyšší dosažené vzdělání (znak $Y$). Dotazovaných bylo 150. Žen bylo 77 a mužů 73. Základní vzdělání mělo 8 žen a 5 mužů, středoškolské mělo 55 žen a 46 mužů a vysokoškolské mělo 14 žen a 22 mužů.
Postup je stejný jako za a) pouze v předposledním kroku: Možnosti – odškrtneme Zvýraznit četn. > 10 a zaškrtneme Procento z celkového počtu – Detailní výsledky – zaškrtneme zobrazit vybraná % v samost. tab.– Výpočet
Dostaneme tabulku, ve které jsou relativní četnosti uvedené v procentech.
Pro převedení relativní četnosti z procent na čísla dvakrát klikneme na proměnnou Y – Formát zobrazení: Číslo – Desetinná místa: 2
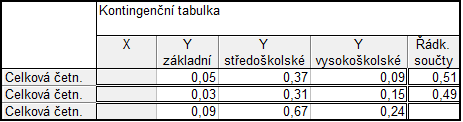
c. Kontingenční tabulku absolutních kumulativních četností
postup
postup v programu Statistica
Vnitřní část tabulky vyplníme simultánními absolutními kumulativními četnostmi (použijeme vzorec \(\displaystyle N_{jk}=N(X \leq x_{[j]} \wedge Y \leq y_{[k]}) = \sum_{u \leq j} \sum_{v \leq k} n_{uv}\).
Světle modře jsou vyznačené buňky, které sčítáme a výsledek zapíšeme do tmavomodré buňky.
Program Statistica neumí vytvořit kontingenční tabulku kumulativních četností.
d. Kontingenční tabulku sloupcově podmíněných relativních četností
postup
postup v programu Statistica
Tentokrát mírně poupravíme tabulku a vnitřní část vyplníme podle vzorce
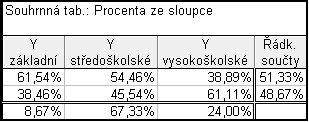
Postup je stejný jako za a) liší se pouze v předposledním kroku: Možnosti – odškrtneme Zvýraznit četn. > 10 a zaškrtneme Procenta z počtu ve sloupci – Detailní výsledky – zaškrtneme zobrazit vybraná % v samost. tab. – Výpočet
Dostaneme tabulku, ve které jsou sloupcově podmíněné četnosti uvedené v procentech. Pro jejich odstranění dvakrát klikneme na proměnnou Y a změníme formát na číslo a počet desetinných míst nastavíme na 2.
Abychom se zbavili posledního řádku a sloupce, dáme případy (proměnné) – odstranit a vybereme, které chceme odstranit.
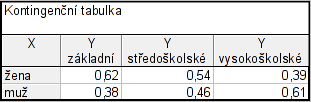
e. Kontingenční tabulku řádkově podmíněných relativních četností
postup
postup v programu Statistica
Tabulku poupravíme, aby vypadala následovně, a vnitřní část vyplníme podle vzorce
Postup je stejný jako za a) liší se pouze v předposledním kroku: Možnosti – odškrtneme Zvýraznit četn. > 10 a zaškrtneme Procenta z počtu v řádku – Detailní výsledky – zaškrtneme zobrazit vybraná % v samost. tab. – Výpočet
Dostaneme tabulku, ve které jsou řádkově podmíněné četnosti uvedené v procentech. Pro jejich odstranění dvakrát klikneme na proměnnou Y a změníme formát na číslo a počet desetinných míst nastavíme na 2.
Abychom se zbavili posledního řádku a sloupce, dáme případy (proměnné) – odstranit a vybereme, které chceme odstranit.
f. Četnostní nezávislost
postup
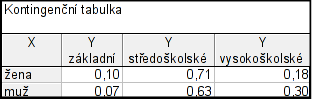
Budeme potřebovat tabulku, kterou jsme dostali v případě 2.1b).
Vidíme, že požadovaná rovnost není splněna, nemusíme tedy dále pokračovat a můžeme říci, že nejvyšší dosažené vzdělání a pohlaví jsou četnostně závislé.
g. Graf simultánní četnostní funkce
postup
postup v programu Statistica
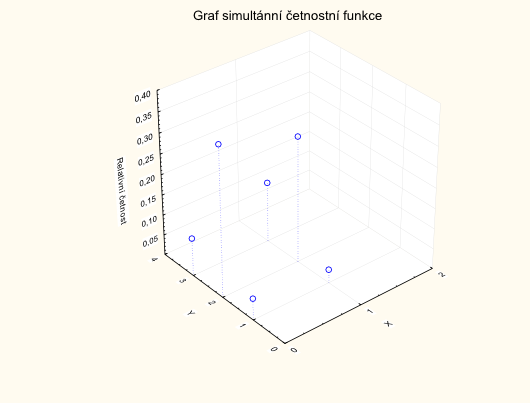
Na osu z naneseme hodnoty simultánní četnostní funkce, na osu x hodnoty znaku X a na osu y hodnoty znaku Y
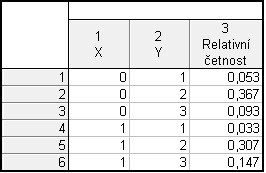
Nejdříve vytvoříme nový datový soubor o 3 proměnných (X: 0 = žena, 1 = muž, Y: 1 = základní, 2 = středoškolské, 3 = vysokoškolské, Relativní četnost - relativní četnosti dvojic) a 6 případech.
Grafy – 3D XYZ grafy – Bodové grafy – Proměnné – X, Y, Relativní četnost – OK – OK
Kliknutím na obrázek grafu můžeme pak dále graf upravovat (např. měřítko na osách, kroky na osách, nadpis, …), aby graf vypadal lépe a byl lépe čitelný.
$d_jh_k$ … obsah dvourozměrného třídicího intervalu
Simultánní četnost - mějme výběrový soubor o rozsahu $n$, $r$ je počet třídicích intervalů znaku $X$ a $s$ je počet třídicích intervalů znaku $Y$. Pro $j = 1, \dots, r$ a $k = 1, \dots, s$ definujeme:
Absolutní četnost $(j,k)$–tého třídicího intervalu
$$
n_{jk} = N(u_j\lt X \leq u_{j+1} \wedge v_k \lt Y \leq v_{k+1})
$$
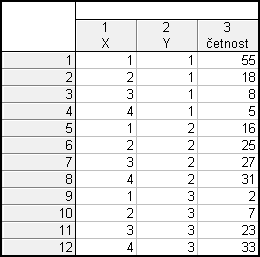
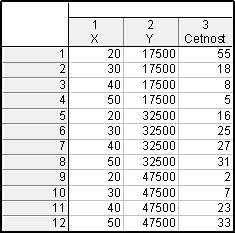
Vytvoříme nový datový soubor o 3 proměnných (X - věk, Y - plat, četnost) a 12 případech
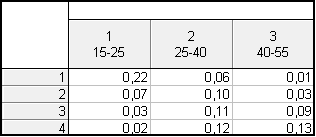
Dvakrát klikneme na proměnnou X – textové hodnoty – vyplníme tabulku: 15-25 $\rightarrow$ 1, 25-35 $\rightarrow$ 2, 35-45 $\rightarrow$ 3, 45-55 $\rightarrow$ 4 – OK
Dvakrát klikneme na proměnnou Y – textové hodnoty – vyplníme tabulku: 10-25 $\rightarrow$ 1, 25-40 $\rightarrow$ 2, 40-55 $\rightarrow$ 3 – OK
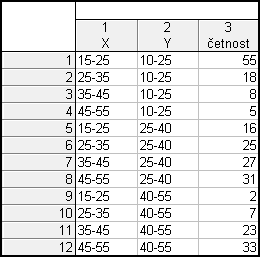
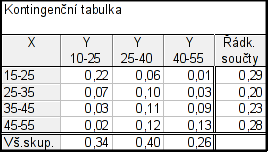
Dostaneme tabulku:
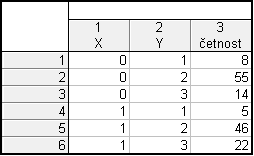
Dále Statistiky – Základní statistiky/tabulky – Kontingenční tabulky – Specif. tabulky (vyberte proměn.) – List1 $\rightarrow$ X – List2 $\rightarrow$ Y – OK – potom klikneme na (nastavení váhy) – Proměnná vah: četnost – Stav: Zapn. – OK – OK – Možnosti – odškrtneme Zvýraznit četn. > 10 – Výpočet
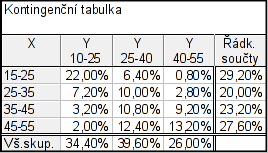
Postup je stejný jako v předešlém příkladě, pouze v předposledním kroku se liší: Možnosti – odškrtneme Zvýraznit četn. > 10 a zaškrtneme Procento z celkového počtu - Detailní výsledky – zaškrtneme zobrazit vybraná % v samost. tab. – Výpočet
Dostaneme tabulku, ve které jsou relativní četnosti opět uvedené v procentech.
Pro převedení relativní četnosti z procent na čísla dvakrát klikneme na proměnnou Y – Formát zobrazení: Číslo – Desetinná místa: 2
Výsledná tabulka tedy bude vypadat takto:
c. Kontingenční tabulku simultánních četnostních hustot
postup
postup v programu Statistica
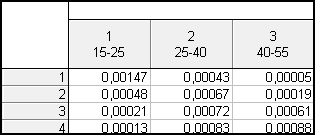
Tabulku vyplníme simultánními četnostními hustotami, vnitřní část tabulky vyplníme podle vzorce $f_{jk} = \frac{p_{jk}}{d_j \cdot h_k}$, poslední sloupec vyplníme podle vzorce $f_{j\cdot}= \frac{p_{j\cdot}}{d_j}$ poslední řádek vyplníme podle vzorce $f_{\cdot k}= \frac{p_{\cdot k}}{h_k}$, kde $d_j = 10$ a $h_k = 15$.
Použijeme tabulku, kterou jsme dostali v předešlém případě, ale pouze vnitřní část tabulky. Tabulka tedy bude vypadat takto:
Protože program Statistica neumí vypočítat kontingenční tabulku simultánních četnostních hustot, musíme využít dlouhého jména, do kterého ručně zadáme vzorec.
Vzorec pro výpočet vnitřní části kontingenční tabulky je $f_{jk} = \frac{p_{jk}}{d_jh_k}$, kde $p_{jk}$ máme již nachystané v tabulce a $d_j\cdot h_k = 10\cdot 15 = 150$. Proto každý sloupec v připravené tabulce musíme vydělit 150.
Dvakrát klikneme na proměnnou 10-25 – do Dlouhého jména napíšeme: =v1/150 – Formát zobrazení: Číslo – Desetinná místa: 5 – OK.
Dvakrát klineme na proměnnou 25-40 – do Dlouhého jména napíšeme: =v2/150 – Formát zobrazení: Číslo – Desetinná místa: 5 – OK.
Dvakrát klineme na proměnnou 40-55 – do Dlouhého jména napíšeme: =v3/150 – Formát zobrazení: Číslo – Desetinná místa: 5 – OK.
Výsledná vnitřní část tabulky tedy vypadá takto:
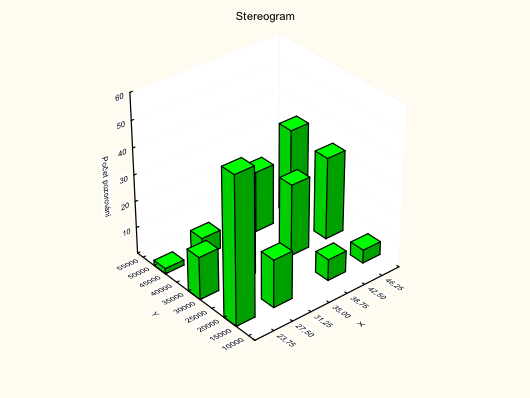
d. V programu Statistica vytvořte Stereogram
postup
postup v programu Statistica
3D graf, který zobrazuje relativní četnost $(j, k)$-tého třídicího intervalu. V grafu jsou kvádry sestrojené nad jednotlivými třídicími intervaly, jejich výška je určena simultánní hustotou četnosti $f(x,y)$. Objem těchto kvádrů je roven relativním četnostem. Toto vyplývá ze vzorce
$p_{jk} = d_j h_k f_{jk}$. Jedná se tedy o analogii histogramu, jako v předchozí kapitole, ale v prostoru.
Bohužel program Statistica neumí vytvořit správný stereogram. Správný graf by měl na ose z simultánní hustotu četnosti, místo počtu pozorování (absolutní četnosti) a mezi kvádry by nebyly žádné mezery.
Nejdříve vytvoříme nový datový soubor o 3 proměnných a 12 případech. Tabulku vyplníme tak, aby vypadala následovně:
Statistiky – Základní statistiky a tabulky – Korelační matice – nastavíme váhy: vybereme Zapn. a Proměnná vah: Cetnost – OK – Detailní výsledky – 3D histogramy – vybereme v prvním okně proměnnou X a ve druhém Y – OK.
Dvakrát klikneme na graf – Vzhled – Mezery mezi sloupci/bloky/stužkami - X:0 Y:0 – OK.
 (nastavení váhy) – Proměnná vah: četnost – Stav : Zapn. – OK – OK – Možnosti – odškrtneme Zvýraznit četn. > 10 – Výpočet
(nastavení váhy) – Proměnná vah: četnost – Stav : Zapn. – OK – OK – Možnosti – odškrtneme Zvýraznit četn. > 10 – Výpočet