Základní soubor – je neprázdná množina, jejíž prvky jsou objekty
Výběrový soubor – libovolná konečná podmnožina základního prostoru o rozsahu \(n\)
Absolutní četnost – počet objektů ve výběrovém souboru pocházející z konkrétní podmnožiny nebo splňující určitou vlastnost
Relativní četnost – absolutní četnost podělená rozsahem výběrového souboru, tedy četnost vzhledem k celému výběrovému souboru
Příklad 1:
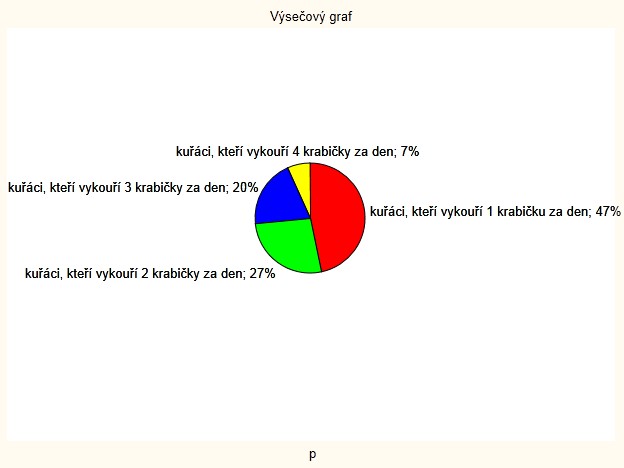
V nadnárodní firmě je velký počet zaměstnanců (základní soubor). Bylo zjišťováno, jaké je nejvyšší dosažené vzdělání zaměstnanců. Podmnožina S obsahuje zaměstnance, kteří mají středoškolské vzdělání a podmnožina V obsahuje zaměstnance s vysokoškolským vzděláním. Náhodně bylo vylosováno 20 zaměstnanců (ti tvoří výběrový soubor o rozsahu 20). Z nich 12 má středoškolské vzdělání a 8 vysokoškolské vzdělání.
\(n\) … rozsah výběrového souboru, tzn. počet zaměstnanců, kteří byli vylosováni
\(n(S)\) … absolutní četnost středoškoláků, tzn. počet středoškoláků, kteří byli vylosováni
\(p(S)\) … relativní četnost středoškoláků
\(n =\)
\(n(S) =\)
\(p(S) =\)
\(n = 20\)
\(n(S) = 12\)
\(p(S) = 12/20 = 0,6\)
Závěr: Z 20 vylosovaných zaměstnanců má 60% pouze středoškolské vzdělání.
Datový soubor – do něj zaznamenáváme hodnoty znaku \(X\) zjišťované na množině objektů, tvořících výběrový soubor. Dostáváme tak vektor \((x_{1}, \ldots, x_{n})^T\). Můžeme zaznamenávat i hodnoty více znaků, pak se jedná o vícerozměrný datový soubor. Uspořádané hodnoty tvoří uspořádaný datový soubor, značíme: \((x_{(1)}, \ldots, x_{(n)})^T\)
Vektor variant – navzájem různé a uspořádané hodnoty znaku \(X\), značíme: \((x_{[1])}, \ldots, x_{[r]})^T\)
Absolutní četnost varianty \(x_{[j]}\):
\[n_j = card\{j;x = x_{[j]}\}\]
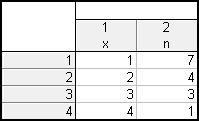
Nejdříve vytvoříme nový dokument o 4 případech a dvou proměnných (x a n).
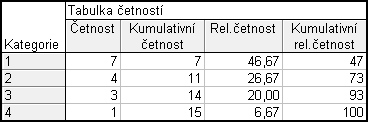
Statistiky – Základní statistiky a tabulky – Tabulky četností – Proměnné : x – OK – potom klikneme na
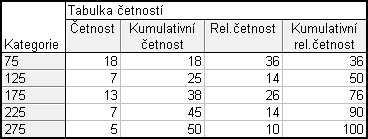
(nastavení váhy) – Proměnná vah: n – Stav : Zapn. – OK – Možnosti odškrtnu Počet a zaprotokolování ChD – zaškrtnu Kumulativní četnosti, Relativní četnosti (%), Kumulativní relativní četnosti – Výpočet (nesmíme zapomenout, že relativní a kumulativní relativní četnosti jsou v %)
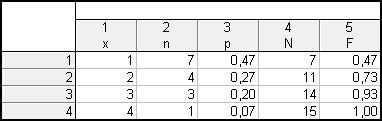
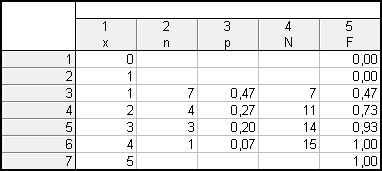
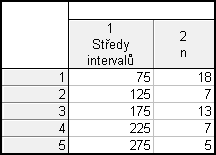
Vytvoříme si nový datový soubor o 4 případech a 5 proměnných (x, n, p, N a F). Budeme tedy chtít tabulku rozložení četností. Hodnoty vezmeme z tabulky četností, kterou jsme ve Statistice dostali výše.
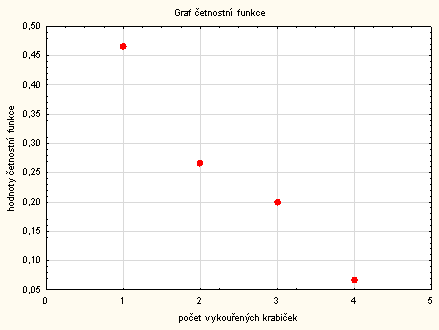
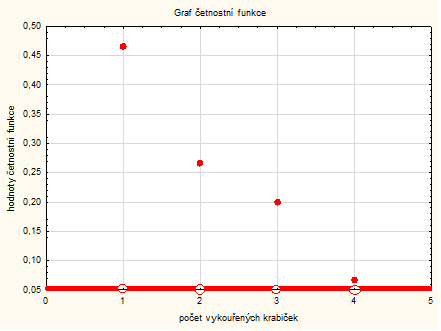
Grafy – 2D grafy – Bodové grafy – Proměnné : x a p – OK – Typ proložení: odškrtnu Lineární – OK
Pravým tlačítkem myší klikneme na graf – Možnosti grafu \(\rightarrow\) můžeme graf upravovat (například popisky os, spojnice, měřítko na osách atd.)
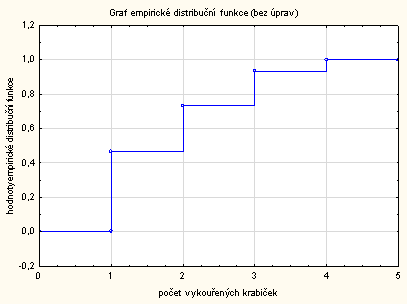
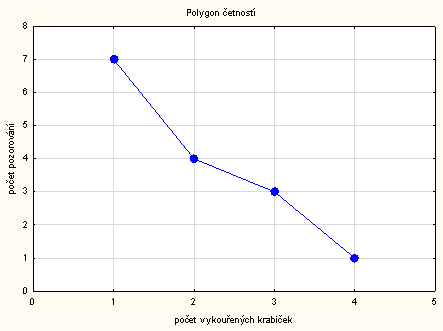
Správně graf četnostní funkce vypadá takto:
Bohužel takový graf v programu Statistica vytvořit neumíme a musíme si pomoci jiným programem.
b. Graf empirické distribuční funkce
postup
postup v programu Statistica
Na osu \(x\) naneseme hodnoty znaku \(X\) a na osu \(y\) naneseme hodnoty empirické distribuční funkce.
Tabulku rozšíříme o 3 nové případy, dva vložíme před první řádek a jeden za poslední řádek.
Vložit – Přidat případy – Kolik: 2, Přidat za případy: 0 – OK
Vložit – Přidat případy – Kolik: 1, Přidat za případy: 6 – OK
Budeme se zajímat pouze o sloupec F a x. Tabulku doplníme tak, aby vypadala následovně:
Dále pokračujeme: Grafy – 2D grafy – Bodové grafy – Proměnné: X zatrhneme x a Y zatrhneme F – OK – Typ proložení vypneme – OK
Pravým tlačítkem myši klikneme na výsledný graf – Možnosti grafu – Spojnice – zatrhneme spojnice a Typ čáry vybereme Schod – OK
Jako poslední úpravu změníme měřítko osy X: opět pravým tlačítkem myši klikneme na výsledný graf – Možnosti grafu – Měřítko – Osa: vybereme X – Mód: vybereme Ručně a nastavíme meze od 0 do 5 – OK
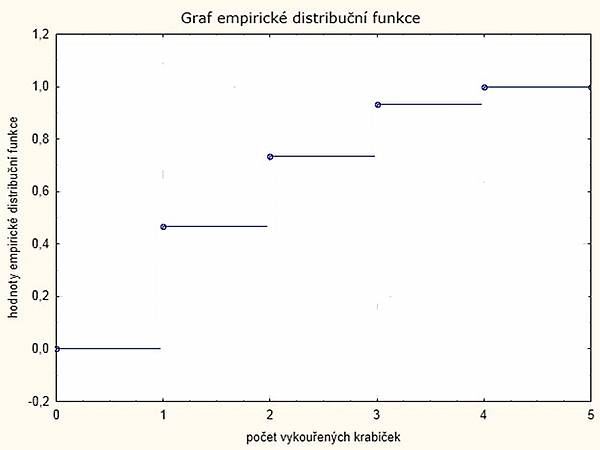
Bohužel program Statistica neumí vynechat svislé čáry, které by v tomto grafu být neměly. Pro to je třeba využít možností jiného programu.
Graf, který dostaneme po úpravě v jiném programu, vypadá takto:
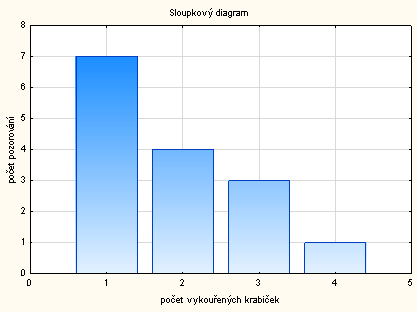
c. Sloupkový diagram
postup
postup v programu Statistica
Na osu \(x\) naneseme hodnoty znaku \(X\) a na osu \(y\) naneseme počet pozorování \((n_j)\).
– četnosti přiřazujeme třídicím intervalům, počet variant je velký
\((u_j; u_{j+1}\rangle\ldots j\)-tý třídicí interval
\(d_j=u_{j+1}-u_j\ldots\) délka \(j\)-tého třídicího intervalu
\(x_{[j]}\ldots\) střed \(j\)-tého třídicího intervalu
\(r\ldots\) počet třídicích intervalů, nejčastěji se volí \(r\) blízké \(\sqrt{n}\) a nebo jej často volíme podle tzv. Sturgersova pravidla: \(r \approx 1+3,3\cdot \log(n)\), kde \(n\) je rozsah výběrového souboru.
Četnostní hustota \(j\)-tého třídicího intervalu:
\[f_j=\frac{p_j}{d_j}\]
Příklad 1.2:
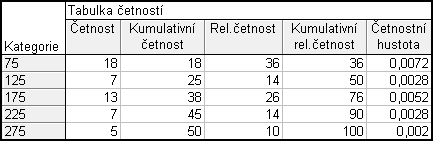
U 50 kuřáků bylo zjišťováno, kolik Kč za den zaplatí za cigarety.
Vytvoříme nový dokument o 5 případech a 2 proměnných (Středy intervalů a n)
Statistiky – Základní statistiky a tabulky – Tabulky četností – Proměnné : Středy intervalů – OK – potom klikneme na
(nastavení váhy) – Proměnná vah: n – Stav : Zapn. – OK – Možnosti odškrtnu Počet a zaprotokolování ChD – zaškrtnu Kumulativní četnosti, Relativní četnosti (%), Kumulativní relativní četnosti – Výpočet (nesmím zapomenout, že relativní a kumulativní relativní četnosti jsou v %)
Do tabulky dodáme četnostní hustotu:
Data – Proměnné – Přidat – Kolik:1, Za:4, Jméno: Četnostní hustota, Dlouhé jméno: =v3/50/100
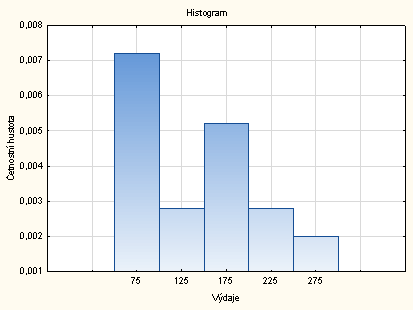
Pomocí histogramu znázorňujeme intervalové relativní četnosti. Schodovitá čára, která shora omezuje histogram, je grafem hustoty četnosti. Na osu \(x\) nanášíme hodnoty znaku \(X\), na osu \(y\) naneseme hodnoty četnostní hustoty, výšky obdélníků jsou četnostní hustoty a obsahy obdélníků odpovídají relativním četnostem.
Nastavíme se kurzorem na proměnnou četnostní hustota – klikneme pravým tlačítkem – Grafy bloku dat – Spojnicový graf:celé sloupce. Vytvořený graf upravíme: 2x klikneme na pozadí grafu, vybereme Spojnice, Obecné – zrušíme Značky – vybereme Sloupce, zaškrtneme Zobrazovat sloupce, Šířka 1, Oblast modrá – OK
b. Graf intervalové empirické distribuční funkce
postup
postup v programu Statistica
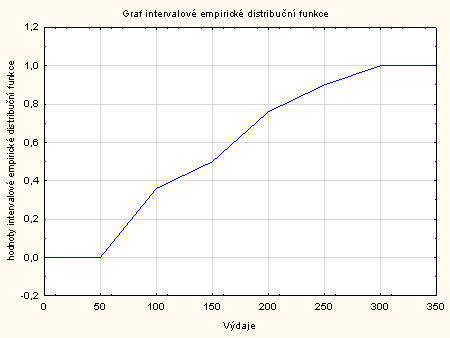
N a osu \(x\) naneseme hodnoty znaku \(X\) a na osu \(y\) naneseme hodnoty intervalové empirické distribuční funkce
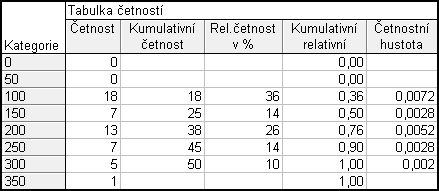
Obdobně jako u sestrojování grafu empirické distribuční funkce budeme muset tabulku z příkladu 1.2 rozšířit o tři případy, dva před první řádek a jeden za poslední řádek. Přepíšeme kategorie, Kumulativní relativní četnosti vydělíme 100, abychom se zbavili % a tabulku doplníme, aby vypadala následovně:
Nastavíme se kurzorem na Kumulativní relativní četnost – klikneme pravým tlačítkem – Grafy bloku dat – Spojnicový graf:celé sloupce.
Pravým tlačítkem myši klikneme na vytvořený graf a změníme Měřítko a Obecné. Měřítko změníme na ose X a to od 1 do 8. Dále klikneme na Obecné a zrušíme zaškrtnutí u Značky a zaškrtneme Spojnice – OK.
 (nastavení váhy) – Proměnná vah: n – Stav : Zapn. – OK – Možnosti odškrtnu Počet a zaprotokolování ChD – zaškrtnu Kumulativní četnosti, Relativní četnosti (%), Kumulativní relativní četnosti – Výpočet (nesmíme zapomenout, že relativní a kumulativní relativní četnosti jsou v %)
(nastavení váhy) – Proměnná vah: n – Stav : Zapn. – OK – Možnosti odškrtnu Počet a zaprotokolování ChD – zaškrtnu Kumulativní četnosti, Relativní četnosti (%), Kumulativní relativní četnosti – Výpočet (nesmíme zapomenout, že relativní a kumulativní relativní četnosti jsou v %)