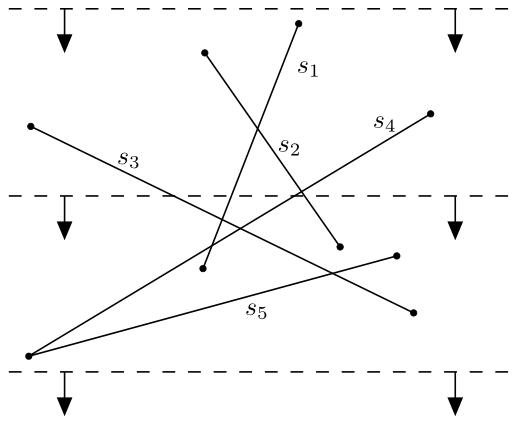
Pro danou množinu \(S = \{ s_1, s_2, \dots , s_n\}\) úseček v rovině chceme najít všechny jejich průsečíky, přičemž u každého průsečíku budou vypsány všechny úsečky, na kterých leží.
Jak se spočítá průsečík dvou úseček \(ab\) a \(cd\)? Každý bod úsečky \(ab\) je tvaru
Jestliže existuje řešení této soustavy takové, že \(\lambda \in [0,1]\) a \(\mu \in [0,1]\) mají úsečky průsečík, v opačném případě jej nemají.
Triviální algoritmus na výpočet průsečíků bere všechny dvojice úseček \((s_i, s_j)\), \(1\leq i \lt j\leq n\), a počítá jejich průsečík. Protože všech dvojic je \(\binom{n}{2}\), je časová náročnost řádu \(O(n^2)\). Často se však stává, že průsečíků je řádově méně než \(n^2\) a pak je tento algoritmus neefektivní. Budeme se zabývat algoritmem, který je pro takové případy daleko vhodnější a pracuje v čase
\[O\big((n+k)\log n\big),\]
kde \(k\) je počet nalezených průsečíků. Algoritmus používá tzv. metodu zametací přímky.
Metoda zametací přímky
Metoda zametací přímky (sweep line) je založena na následující geometrické představě: rovinou se od shora dolů pohybuje vodorovná přímka, její cesta začíná nad všemi úsečkami množiny \(S\) a končí pod nimi. Algoritmus provádí nějakou akci pouze, když zametací přímka prochází význačnými body, tak zvanými událostmi. V tomto případě jsou jimi koncové body úseček a již v průběhu algoritmu spočítané průsečíky. Akce, kterou algoritmus provádí, spočívá v tom, že zjišťuje, zda úsečky z nejbližšího levého a pravého okolí události mají průsečík pod zametací přímkou. Pokud ano, zařadí jej mezi události do tzv. fronty.
Obrázek 2.1
Struktury spojené s metodou zametací přímky
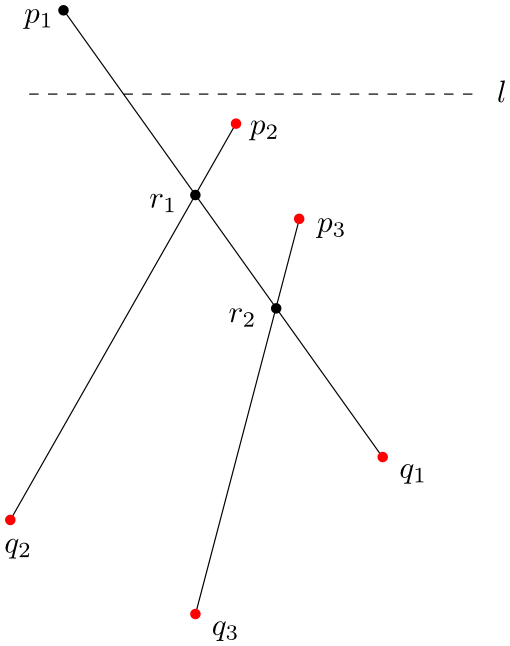
S metodou zametací přímky se obvykle pojí dvě struktury – fronta a binární vyvážený strom. Fronta událostí \(Q\) je uspořádaná posloupnost význačných bodů. Uspořádání je „od shora dolů a zleva doprava“, což je formálně lexikografické uspořádání: bod \(p\) stojí před bodem \(q\), jestliže
Při průchodu zametací přímky nějakou událostí, je tato událost z fronty odstraněna, zatímco některé další události mohou být do fronty nově zařazeny. V našem případě jsou na začátku ve frontě všechny koncové body úseček množiny \(S\).
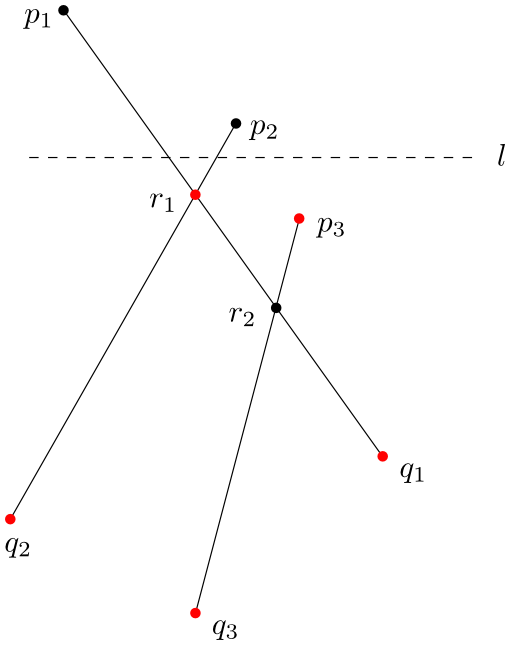
Obrázek 2.3 Po průchodu přímky \(l\) událostí \(p_2\) se fronta změní na posloupnost \((r_1, p_3, q_1, q_2, q_3)\).
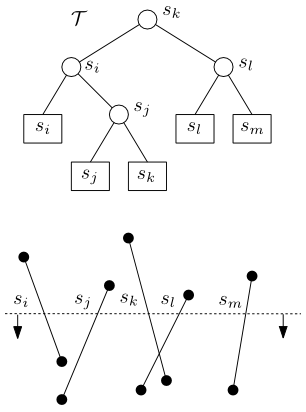
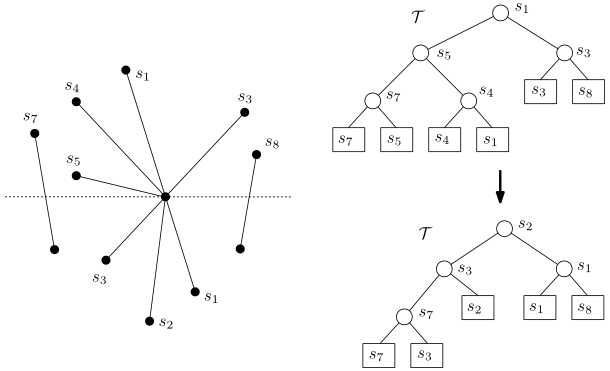
Další strukturou spojenou s metodou zametací přímky je binární vyvážený strom \({\mathcal T}\). Ten popisuje uspořádání úseček, které protínají zametací přímku \(l\). Toto uspořádání se bere zleva doprava a je zachyceno v listech stromu \({\mathcal T}\). Uzly stromu jsou pojmenovány podle listu, který je nejvíce vpravo v levém podstromu.
Obrázek 2.4
Co se děje při průchodu událostí \(p\)
Označme \(L(p)\) úsečky z množiny \(S\), které mají \(p\) jako svůj dolní bod, \(C(p)\) úsečky z množiny \(S\), které obsahují bod \(p\) jako svůj vnitřní bod a \(U(p)\) úsečky z množiny \(S\), které mají bod \(p\) jako svůj horní bod.
Je-li zametací přímka těsně nad bodem \(p\) obsahuje strom \({\mathcal T}\) ve svých listech úsečky z \(L(p)\cup C(p)\) a případně další, nikoliv však z \(U(p)\). Při průchodu zametací přímky bodem \(p\) úsečky množiny \(L(p)\) ze stromu \({\mathcal T}\) zmizí, úsečky z \(U(p)\) přibudou a úsečky z \(C(p)\) změní pořadí. Formálně to provedeme takto: z \({\mathcal T}\) vyndáme listy \(L(p)\cup C(p)\) a po vyndání každého listu strom vyvážíme, potom přidáme mezi listy ve správném pořadí úsečky z \(C(p)\cup U(p)\) a po přidání každého listu strom opět vyvážíme. Pokud sjednocení \(L(p)\cup C(p)\cup U(p)\) obsahuje více než dvě úsečky, označíme \(p\) za průsečík. V každém případě vyřadíme bod \(p\) z fronty \(Q\).
Obrázek 2.5
Další akce při průchodu zametací přímky bodem \(p\) spočívají v počítání průsečíků úseček procházejících bodem \(p\) a sousedních úseček. Vycházíme z pořadí úseček pro zametací přímkou těsně pod událostí \(p\).
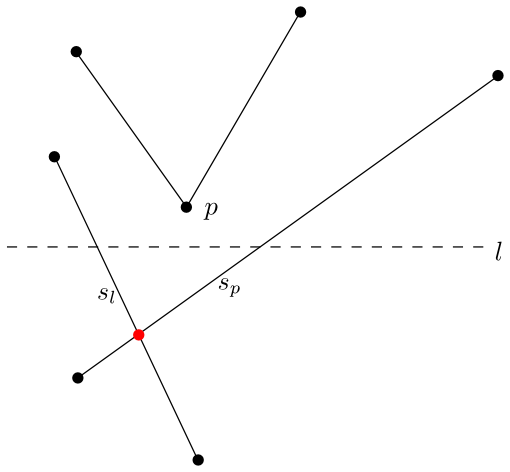
Jestliže \(C(p)\cup U(p)=\emptyset\), zjistíme zda nejbližší úsečka vlevo od \(p\) (označme ji \(s_l\)) a vpravo od \(p\) (označme ji \(s_p\)) mají průsečík pod zametací přímkou. Pokud ano, zařadíme průsečík do fronty.
Obrázek 2.6
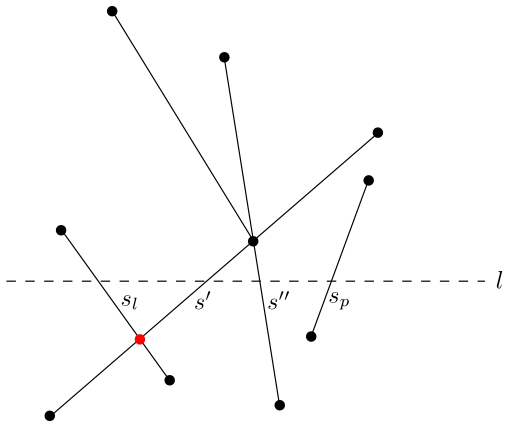
Jestliže \(C(p)\cup U(p)\ne\emptyset\), označíme \(s'\) úsečku z \(C(p)\cup U(p)\), která je nejvíc vlevo, a \(s^{\prime\prime}\) úsečku z \(C(p)\cup U(p)\), která je nejvíce vpravo. Nechť \(s_l\) je nejbližší levý soused úsečky \(s'\) a \(s_p\) nejbližší pravý soused úsečky \(s^{\prime\prime}\). Hledáme průsečíky \(s' \cap s_l\) a \(s^{\prime\prime}\cap s_p\) pod zametací přímkou \(l\). Pokud existují zařadíme je do fronty \(Q\).
Obrázek 2.7
AlgorithmFindIntersections(\(S\))
Input. A set \(S\) of line segments in the plane.
Output. The set of intersection points among the segments in $S$ such that each intersection point is associated with the segments which contain it.
Initialize an empty event queue \({\mathcal Q}\). Next, insert the segment endpoints into \({\mathcal Q}\); when an upper endpoint is inserted, the corresponding segment should be stored with it.
Initialize an empty status structure \({\mathcal T}\).
while \({\mathcal Q}\) is not empty
do Determine the next event point \(p\) in \({\mathcal Q}\) and delete it.
HandleEventPoint(\(p\))
AlgorithmHandleEventPoint(\(p\))
Let \(U(p)\) be the set of segments whose upper endpoint is \(p\); these segments are stored with the event point \(p\). (For horizontal segments, the upper endpoint is by definition the left endpoint.)
Find all segments stored in \({\mathcal T}\) that contain \(p\); they are adjacent in \({\mathcal T}\). Let \(L(p)\) denote the subset of segments found whose lower endpoint is \(p\), and let \(C(p)\) denote the subset of segments found that contain \(p\) in their interior.
if \(L(p) \cup U(p) \cup C(p)\) contains more than one segment
then Report \(p\) as an intersection, together with \(L(p)\), \(U(p)\), and \(C(p)\).
Delete the segments in \(L(p) \cup C(p)\) from \({\mathcal T}\).
Insert the segments in \(U(p) \cup C(p)\) into \({\mathcal T}\). The order of the segments in \({\mathcal T}\) should correspond to the order in which they are intersected by a sweep line just below \(p\). If there is a horizontal segment, it comes last among all segments containing \(p\).
(∗ Deleting and re-inserting the segments of \(C(p)\) reverses their order. ∗)
if \(U(p) \cup C(p) = \emptyset\)
then Let \(s_l\) and \(s_p\) be the left and right neighbors of \(p\) in \({\mathcal T}\).
FindNewEvent \((s_l, s_p, p)\)
else Let \(s'\) be the leftmost segment of \(U(p) \cup C(p)\) in \({\mathcal T}\).
Let \(s_l\) be the left neighbor of \(s'\) in \({\mathcal T}\).
FindNewEvent \((s_l, s', p)\)
Let \(s''\) be the rightmost segment of \(U(p) \cup C(p)\) in \({\mathcal T}\).
Let \(s_p\) be the right neighbor of \(s''\) in \({\mathcal T}\).
FindNewEvent \((s'', s_p, p)\)
AlgorithmFindNewEvent\((s_l , s_p , p)\)
if \(s_l\) and \(s_p\) intersect below the sweep line, or on it and to the right of the current event point \(p\), and the intersection is not yet present as an event in \({\mathcal Q}\)
then Insert the intersection point as an event into \({\mathcal Q}\).
Animace algoritmu pro konkrétní situaci
Lemma 2.1
Algoritmus najde všechny průsečíky.
Důkaz
Je potřeba ukázat, že každý průsečík je spočítán při průchodu některou událostí. Nechť \(p\) je průsečík a všechny před ním už byly spočítány a vloženy do fronty.
Obrázek 2.8
Na obrázku jsou červeně označeny události, ve kterých je \(p\) detekován jako průsečík.
\(\Box\)
Lemma 2.2
Algoritmus pracuje v čase \(O\big((n+k)\log n\big)\), kde \(n\) je počet úseček a \(k\) je počet nalezených průsečíků.
K důkazu potřebujeme Eulerovu větu z teorie grafů.
Věta 2.3 (Eulerova)
Nechť \(G\) je rovinný graf, který má \(n_v\) vrcholů, \(n_e\) hran a rovinu rozděluje na \(n_f\) oblastí. Pak \(n_v -n_e+n_f\geq 2\). Je-li \(G\) souvislý graf, pak nastane rovnost
\[n_v-n_e+n_f=2\,.\]
Důsledek 2.4
\[n_e\le 3n_v\]
Důkaz
Každá oblast je ohraničena aspoň třemi hranami, každá hrana omezuje nejvýše dvě oblasti. Proto je počet všech oblastí včetně té neomezené
\[n_f\le \frac{2n_e}{3}.\]
Dosazením za \(n_f\) do Eulerovy nerovnosti, dostaneme
\[n_v-n_e+\frac{2n_e}{3}\ge 2.\]
Po úpravě dostaneme dokazovanou nerovnost.
\(\Box\)
Důkaz lemmatu 2.2
Uspořádání \(2n\) koncových bodů úseček množiny \(S\) trvá čas \(O(n\log n)\). Vyvážení lineárního stromu o \(n\) listech po ubrání nebo přidání listu trvá čas \(O(\log n)\).
Pro událost \(p\) nechť \(m(p)\) je počet prvků množiny \(L(p)\cup C(p)\cup U(p)\). Čas potřebný pro aplikaci algoritmu HANDLE EVENT POINT v bodě \(p\) je
\[O\big(m(p)\log n\big)\,.\]
Proto čas potřebný pro celý algoritmus je řádově
\[\sum_p m(p) \log n\,.\]
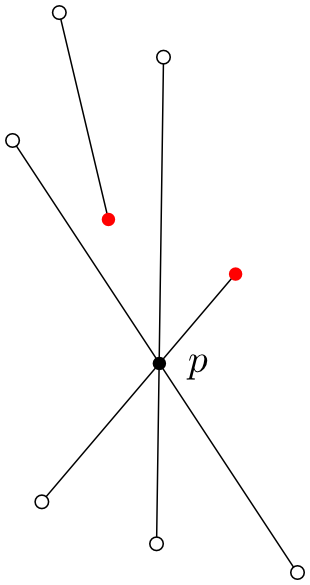
Toto číslo spočteme aplikací Eulerovy věty na rovinný graf daný množinou \(S\). Uzly grafu jsou všechny koncové body a průsečíky úseček. Stupeň uzlu \(p\) (\(=\) počet hran z \(p\) vycházejících) je \(s(p)\). Platí \(m(p)\le s(p)\).
Obrázek 2.9 \(m(p)=4, s(p)=6\).
Nyní si stačí uvědomit, že \(\sum_p s(p) = 2n_e\) a \(n_v \leq 2n +k\). Aplikací nerovnosti za Eulerovou větou dostaneme