Principy kvalitativního výzkumu
Dana Dolanová, Edita Pešáková, Petra Búřilová, Andrea Pokorná
Obsah kapitoly
Příprava, kódování a zobrazování dat v kvalitativním výzkumu
Příprava kvalitativních dat k dalšímu zpracování – přepisu, kódování a zobrazování/vizualizaci (myšlenkové mapy, schémata, grafy, diagramy) je jednou z nejdůležitějších částí celého procesu směřujícího k jejich zdárné analýze a interpretaci. Pro analýzu dat je důležitých několik vzájemně navazujících kroků, které schematicky uvádíme v obrázku 1.
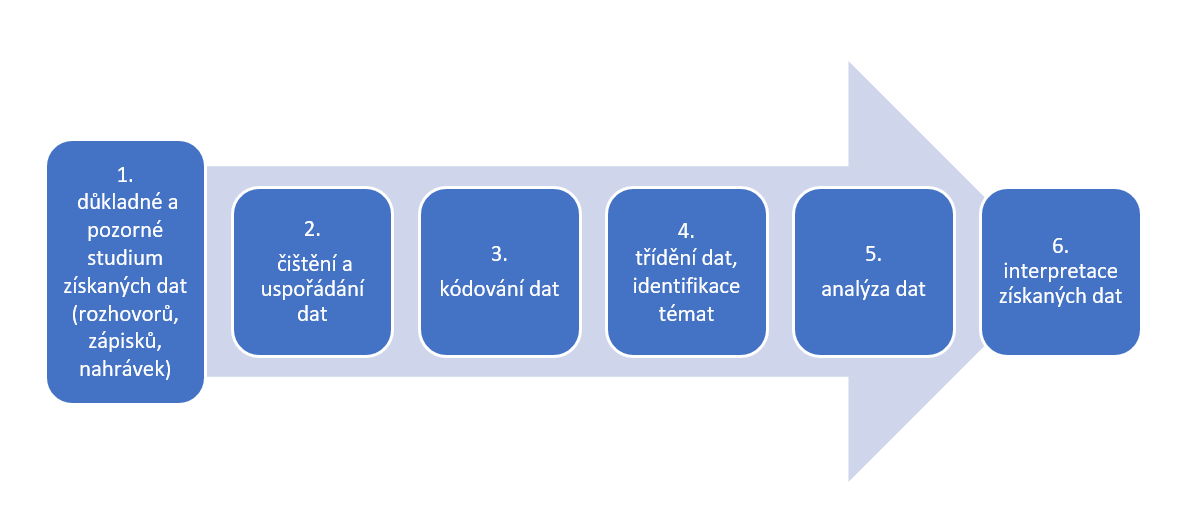
Analýza dat následně vychází zejména z přepisu rozhovorů, terénních poznámek (field notes) výzkumníka, videozáznamů, audionahrávek, písemných vyjádření respondentů, autentických dokumentů apod. Cílem analýzy dat je získaná data uspořádat, strukturovat a dekódovat jejich význam. I když pro analýzu kvalitativních dat neexistují žádné univerzální pravidla, lze následovat jednotlivé metodiky analýzy získaných dat pro každou z běžně užívaných kvalitativních technik. Detailně je možné se s nimi seznámit v publikacích Flick, 20141; Ritchie et al., 20142. Při zpracovávání kvalitativních dat je třeba data zkoumat obezřetně a rozvážně s ohledem na enormní množství materiálů, které je často nutné číst opakovaně se snahou je uspořádat, nalézt a pochopit jejich význam a poté je srozumitelně interpretovat. Badatel by se měl maximálně snažit omezit vnášení vlastních názorů, které mohou ovlivnit výsledky výzkumu.
Dle Stuckey (2015)3 je kódování dat při analýze kvalitativního výzkumu procesem vyžadujícím čas a kreativitu. S usnadněním celého procesu mohou pomoci následující tři kroky:
- pročtení dat a vytvoření příběhu;
- kategorizace dat do kódů;
- použití poznámek pro objasnění a interpretaci.
Vhodné je také pamatovat na výzkumnou otázku nebo dějovou linii, které při kódování pomáhají soustředit se na relevantní kódy. K definování významu kódů a udržení transparentnosti procesu lze použít datový slovník. Kódování se provádí buď pomocí předem stanovených (apriorních) nebo emergentních kódů (těch, které se objevují/vynořují v průběhu analýzy), nejčastěji však kombinací obou. Používáním poznámek, které pomáhají objasnit, jak výzkumník konstruuje kódy a své interpretace, se analýza nakonec lépe píše a má větší konzistenci. Pro detailnější seznámení se s kódováním dat a shlédnutí příkladu použití jednotlivých kroků na konkrétním případu u pacientů s diabetem mellitem doporučujeme prostudovat celou publikaci Stuckey, 2015.3
Ilustraci shromažďování audiovizuálních dat a uspořádání smíšeného sledu akcí a interakcí, poskytují videozáznamy chirurgických týmů na dvou operačních sálech velké londýnské fakultní nemocnice, které provedl autorský tým Pallotti, Weldon a Lomi (2022)4. Pro bližší informaci doporučujeme vážným zájemcům o kvalitativní výzkum prostudovat celou jejich publikaci.
Přepis dat
Ačkoli je přepis často považován za součást procesu sběru dat, je také součástí analýzy.5 Prvním krokem analýzy získaných dat je zdárný přepis audiovizuálních dat do písemné podoby. Je to časově náročný interpretační proces, který zahrnuje odvozování závěrů. Existuje mnoho různých způsobů, jak přepsat stejná data. Výzkumní pracovníci se musí rozhodnout, jaká úroveň podrobnosti přepisu je pro konkrétní projekt požadována a jak mají být data reprezentována v písemné podobě.6 Přepis (transkripce), který obsahuje pouze slova vyřčená účastníky, ztrácí údaje o interakci mezi nimi. Je ale na výzkumníkovi, zda bude přepis obsahovat podrobnosti o interakcích (což by vyžadovalo více času nebo zdrojů), nebo se rozhodne, že informace o interakcích nejsou pro jeho analýzu relevantní.78 Přepisování je spíše interpretačním aktem než pouhým technickým postupem. Psaný text se od mluveného slova liší syntaxí, volbou slov a přijatou gramatikou.6 Pečlivé pozorování, které přepisování zahrnuje, může vést k zaznamenání neočekávaných (skrytých) jevů. V přepisu nelze vyjádřit celou složitost lidské interakce, a tak poslech a/nebo sledování „původních“ nahraných dat přibližuje údaje tím, že reflektuje způsob, jakým byly věci řečeny, i to, co bylo řečeno.9Transkripce je také považována za subjektivní zobrazovací proces, protože přepisovatel musí v průběhu celého procesu činit subjektivní rozhodnutí o tom, co do textu zahrnout (nebo nezahrnout), zda opravit chyby a upravit gramatiku, či opakování některých vyjádření. V této souvislosti lze tedy hovořit o „naturalizovaném přepisu“ (neboli o „inteligentním doslovném přepisu“), který přizpůsobuje ústní projev psaným normám, a „denaturalizovaném přepisu“ („úplný doslovný přepis“), kde je ponecháno vše, včetně výroků, veškerých chyb (i gramatických) a opakování.10 Proces transkripce tedy zahrnuje to, co je v přepisu zastoupeno (např. rozhovor, čas, neverbální jednání, vztahy mezi mluvčím a posluchačem, fyzická orientace, více jazyků, překlady); kdo koho zastupuje, jakým způsobem, za jakým účelem a s jakým výsledkem; a jak analytici ve svých prezentacích zobrazují sami sebe, své účastníky, formu, obsah a jednání.11
Vzhledem k neustálému zdokonalování technologií a faktu, že umělá inteligence je stále schopnější vytvářet psaný text z nahraného zvuku, objevuje se otázka, zda je vůbec nutný lidský přepis? Díky existenci nových možností softwaru pro počítačem podporovanou analýzu kvalitativních dat (CAQDAS – popsáno i níže), jako jsou NVivo, Atlas.ti a MAXQDA, mají kvalitativní výzkumníci možnost zcela se vzdát přepisu zvuku do textu a místo toho se věnovat živému kódování audiovizuálních souborů. S využitím technologií mohou výzkumníci:
- nejprve pozorně poslouchat nahrávky, aby následně mohli neverbální náznaky kódovat;
- poté následuje fáze zaznamenávání a kódování na základě předem definovaných témat a jejich přiřazování k časovým kódům a neverbálním náznakům;
- a nakonec pak výzkumníci z nahrávky přepisují konkrétní citáty, které je zajímají.12
Takto mají výzkumníci prostor pro lepší vhled do problematiky, ponoření se do dat, což jim umožňuje zohlednit dynamiku zkoumaného procesu (např. skupinové interakce, neverbální komunikace), která se při kompletním přepisu zvuku do textu často ztrácí.13
Přepis slyšeného rozhovoru do písemné podoby vyžaduje redukci, interpretaci a znázornění, tak aby byl psaný text čitelný a smysluplný.1415 U vizuálních dat je nutné si ujasnit, zda jsou vizuální informace nezbytné pro interpretaci dat (například uspořádání místností, orientace těla, mimika, gesta, použití vybavení při konzultaci…)16, protože vizuální data jsou náročná na zpracování, jejich přepis trvá velmi dlouho a neexistují jasná pravidla, jak vizuální prvky v přepisu znázornit.17 Zdařilou ukázku přepisu audiovizuálních dat a bližší informace k postupu je možné nalézt v publikaci Bailey, 20089 nebo také v publikaci Stuckey, 201418, či McMullin, 2021.13
Tvorba kategorií dat
Uspořádání – kategorizace dat je více než jen administrativní úkol; může být také strategií pro analýzu. Je také pro výzkumníka důležité, aby nemusel pokaždé procházet celý datový soubor, ale byl schopen identifikovat část, kterou aktuálně potřebuje. Účelem tvorby jednotlivých kategorií je redukce dat na menší jednotky. Kategoriální systém a jeho vývoj vyplývá z pečlivého pročtení datového souboru a zaměření se na identifikování skrytých pojmů, či myšlenek a jejich vzájemných vztahů. Pro úspěšnou kategorizaci kvalitativních dat lze opět využít většinu software pro kvalitativní analýzu dat (dále jako QDA – Qualitative Data Analysis), který nabízí možnost jednoduchého či kombinovaného uspořádání souborů. Každý způsob uspořádání se tak stává novým způsobem pohledu na získaná data. Výzkumník má možnost třídit soubory podle místa výzkumu nebo data pořízení apod. Jakmile se výzkumník dostane hlouběji do analýzy, otevírají se mu další možnosti a vidí existenci dalších organizačních přístupů, které mohou poskytnout přehled (například podle statusu rodičů).19
Kódování
Kódování kvalitativních dat v podstatě znamená označování a vytváření kategorií pro jednotlivé části nebo „fragmenty“ v souboru dat. Pro názornost si lze kódování představit jako práci knihovníka, jehož práce je podobná – vytváření předmětových hesel pro jednotlivé sekce. Kódování tak může ve druhé fázi analýzy pomoci data přesunout, či posunout vpřed nebo upozornit na nově vznikající témata.20 Kódování lze rovněž definovat i jako strategii pro analýzu kvalitativních dat, jejímž cílem je identifikovat související obsah napříč daty prostřednictvím přiřazování popisného označení jednotlivým jejich aspektům. Hovoříme o hledání pomyslné červené niti, která se line získanými informacemi. Způsob, jakým se výzkumník rozhodne kódovat, nebo zda vůbec kódovat získaná data, by se měl řídit metodikou výzkumu.19Důležité body, které je třeba zvážit, při rozhodování, jak kódovat získaná data uvádíme v tabulce 2.
Tabulka 2 Důležité body kódování dat
| Na co nezapomenout při rozhodování, jak kódovat data19 | ||
| Co budete kódovat? | Jaké aspekty dat je třeba kódovat? V případě, že není potřeba kódovat všechna dostupná data, dle čeho se výzkumník rozhodne, které prvky je třeba kódovat? Pokud jsou k dispozici nahrávky rozhovorů nebo ohniskových skupin nebo jiné typy multimediálních dat, je třeba vytvářet přepisy, které budou analyzovány a kódovány? Nebo je možné kódovat samotná média? (viz Farley, Duppong & Aitken, 202021 o přímém kódování zvukových nahrávek namísto přepisů). | |
| Odkud budou vaše kódy pocházet? | V závislosti na metodice výzkumu může kódovací schéma vycházet z předchozího výzkumu a být aplikováno na stávající data (deduktivní). Nebo se výzkumník pokusí vytvořit kódy výhradně z dat, přičemž bude co nejvíce ignorovat předchozí znalosti o zkoumaném tématu, čímž vytvoří schéma založené na vlastních datech (induktivní). V praxi se bude mnoho postupů pohybovat mezi těmito dvěma přístupy. | |
| Jak budete své kódy aplikovat na data? | Výzkumník se rozhodne, zda ke kódování svých kvalitativních dat použije software/softwarové nástroje (např. software Word nebo tabulkový procesor), nebo bude pracovat především s fyzickými verzemi svých dat. I když kvalitativní software nabízí některé výhody, není nezbytně nutný. | Kódy lze snadno přeznačovat, slučovat nebo rozdělovat. Na stejná data je možné použít více kódovacích schémat, což znamená, že je možné zkoumat více způsobů porozumění stejným datům. Analýza tedy není omezena schopností výzkumníka pracovat s fyzickými daty, například s papírovými přepisy. |
| Většina softwarových programů pro QDA obsahuje možnost exportu a importu kódovacích schémat. To znamená, že je možné vytvořit a znovu použít kódovací schéma z předchozí studie nebo které bylo vytvořeno mimo software, aniž by bylo potřeba každý kód vytvářet ručně. | ||
| Některé softwary pro QDA obsahují možnost přímého kódování obrazových, video a audio souborů, což představuje úsporu času oproti vytváření přepisů a může být kódování obohaceno přístupem ke zprostředkovanému obsahu ve srovnání s přepisy. | ||
| Používání softwaru QDA umožňuje využití funkce automatického kódování, např. automatické kódování všech výroků podle mluvčího v přepisu fokusní skupiny nebo identifikace a kódování všech odstavců, které obsahují určitou frázi. | ||
| Co se bude kódovat? | Výzkumník si klade otázku, jaký přístup ke kódování zvolí. Zda bude používat přístup kódování po řádcích, přičemž menší kódy budou nakonec zhuštěny do větších kategorií nebo pojmů, anebo začne s kódy aplikovanými na větší úseky textu a možná později projde příklady, aby prozkoumal a překódoval rozdíly mezi jednotlivými částmi? | |
| Jak vysvětlíte proces kódování? | Bez ohledu na to, jak výzkumník ke kódování přistoupí, měl by být tento proces jasně sdělen při podávání zprávy o výzkumu22 Je potřeba pečlivě zvážit používání frází typu „objevila se témata“, protože to evokuje situaci, ve které témata leží a pasivně čekají v datech, až je výzkumník vytrhne. V popisu tohoto typu chybí sdělení, jak výzkumník témata „viděl/vnímal“ a rozhodl se, která z nich jsou pro studii relevantní. Ryan a Bernard (2003)23 nabízejí skvělý návod, jak lze témata v datech identifikovat, a to jak pomocí vlastních pozorování, tak i manipulací s daty. | |
| Jak budete informovat o výsledcích svého procesu kódování? | Způsob reportování procesu kódování by měl být v souladu e zvolenou metodikou. Metoda vyžaduje pečlivé a konzistentní použití kódovacího schématu, společně se zprávami o spolehlivosti mezi jednotlivými hodnotiteli a počty, jak často se kód v datech objevuje. Kódy je možné použít v vytvoření bohatého popisu zkušeností, aniž byste museli přesně uvádět, jak často byl kód použit. | |
| Jak budete kódovat ve spolupráci? | V případě spolupráce vícero výzkumníků nebo výzkumných týmů, vyžaduje proces kódování pečlivé plánování a realizaci. Je vhodné vést pravidelné rozhovory o postupu výzkumu, zejména pokud je jeho cílem vytvoření a důsledné uplatňování kódovacích schémat napříč daty. | |
Pro kódování dat je již běžně užíván Computer-Assisted Qualitative Data Analysis Software – CAQDAS (Software pro počítačovou analýzu kvalitativních dat) jako pomoc výzkumníkům při správě, organizaci a analýze kvalitativních dat.2425 Jde o mechanismus pro lepší organizaci a kódování dat, zahrnující různé analytické nástroje: pro vyhledávání obsahu, pro kódování, pro propojování, pro mapování nebo vytváření sítí, pro dotazování, pro psaní a anotaci. Všechny zmíněné funkce pomáhají výzkumníkům konstruovat témata z velkých souborů dat, přesto vyžadují kódování dat manuálně. Samotný proces kódování je stále časově náročný a pracný. Příklady software pro počítačovou analýzu dat uvádí tabulka 3.
Tabulka 3 Přehled software pro počítačovou analýzu kvalitativních dat
| Software pro počítačovou analýzu kvalitativních dat | |
| Otevřené zdroje software | Aquad; Cassandre; CLAN; Coding Analysis Toolkit; Compendium; ELAN; KH Coder; Qiqqa; Quantitative Discourse Analysis Package (qdap); RQDA |
| Patentovaný software | ATLAS.ti; Dedoose; Delve; MAXQDA; NVivo; QDA Miner; Quirkos; Transana |
Lennon et al.26 vyvinuli pro výzkumné pracovníky v oblasti primární péče modelovou metodiku automatického/automatizovaného kvalitativního asistenta (automated qualitative assistant – AQUA), která slouží k rozšíření kvalitativního kódování rozsáhlých souborů dat a umožnění proveditelnosti kvalitativního výzkumu velkého rozsahu. Nástroj AQUA lze do kvalitativního designu začlenit ve dvou fázích analýzy:
- v počáteční fázi analýzy – pro rychlou tematickou analýzu rozsáhlých souborů dat s volným textem a vytváření vizuálně interpretovatelných výstupů
- ve fázi po manuální analýze podmnožiny rozsáhlého kvalitativního souboru dat, ke kódování některých tematických kategorií ve zbývajícím souboru, což výrazně zvyšuje rozsah analýzy, kterou může daný tým dokončit.
Pro lepší pochopení a nástroje i prostudování názorné ukázky doporučujeme prostudovat celou publikaci autorů Lennon a kol. (2021).26
Metody vyhodnocení a interpretace kvalitativních dat
Prezentace a interpretace dat
Interpretaci dat je možné chápat jako smysluplný výklad zjištěných výsledků, které je možné prezentovat individuálně (např. dle jednotlivých kategorií) nebo souhrnně (např. vztažené k cílům práce). Interpretace kvalitativních dat je zásadní a nezbytná, protože povyšuje výsledky kvalitativní studie z pouhého lokálního „příběhu“ na výpověď, která má potenciální význam pro širší okolí/publikum/společnost.27282930 Zjednodušeně lze říci, že interpretace spočívá v systematickém označování důležitých (zajímavých nebo nesrozumitelných) míst v datovém materiálu. Následně výzkumník data komentuje, porovnává, třídí, propojuje a hledá souvislosti. S časovým odstupem (např. několika týdnů) se k nim opět vrací, přezkoumává a pokračuje s následným zahušťováním dat a snahou o „vypíchnutí“ nejdůležitějších myšlenek, skládání „příběhů“ a opouštění nerelevantních dat.
-
Iterativní kategorizace (Iterative categorization, IC)
Iterativní kategorizace je systematická technika pro řízení analýzy, která podporuje a je kompatibilní se stávajícími běžnými analytickými přístupy (např. tematickou analýzou, rámcem, konstantním srovnáváním, analytickou indukcí, obsahovou analýzou, konverzační analýzou, analýzou diskurzu, interpretativní fenomenologickou analýzou a narativní analýzou). Svého cíle dosahuje tím, že umožňuje kódovat a analyzovat data podle tématu, události, příběhu, verbální interakce, významu, pocitu, myšlenky, kategorie, tématu, konceptu nebo teorie atd. Lze ji použít u textových dat, která byla kódována deduktivně (na základě již existujících předtuch nebo teorií výzkumníka o otázkách, které budou v datech pravděpodobně důležité) a induktivně (na základě otázek, které vyplynou jako důležité ze samotných dat). Přínos IC spočívá v tom, že nabízí soubor standardizovaných postupů, které vedou výzkumníka od analýzy dat až po jejich interpretaci a zanechávají jasnou auditní stopu. Auditní stopa ukazuje, jak výzkumníci dospěli ke svým zjištěním, a poskytuje cestu zpět k výchozím údajům pro další objasnění, rozpracování a potvrzení/vyvrácení důkazů.32 Nabízí přísný a transparentní postup, který zvyšuje důvěryhodnost a potenciální reprodukovatelnost výsledků výzkumu.27283132
Při publikování kvalitativních studí je potřeba dodržovat mezinárodně uznávané pokyny, aby bylo zajištěno zveřejnění všech důležitých témat týkajících se plánu studie a výsledků. Většina akademických časopisů ve svých pokynech uvádí předpoklad, že autoři tyto pokyny následují a některé dokonce od autorů vyžadují, aby uvedli a/nebo nahráli pokyny pro vykazování, které byly použity při psaní článku. Pokyny pro vykazování různých typů studií je možné najít online na webových stránkách The EQUATOR-network (Enhancing the QUAlity and Transparency Of health Research; https://www.equator-network.org/). Je důležité používat a začlenit příslušné pokyny už od začátku výzkumného projektu, protože v nich jsou uvedeny důležité kroky.
Pro standardizaci a usnadnění publikace výsledků kvalitativního výzkumu mohou výzkumníci využít několik druhů standardů vykazování. Nejpoužívanějšími jsou COREQ (Consolidated criteria for reporting qualitative research – Konsolidovaná kritéria pro vykazování kvalitativního výzkumu), SRQR (Standards for reporting qualitative research: a synthesis of recommendations – Standardy pro vykazování kvalitativního výzkumu a ENTREQ (Enhancing transparency in reporting the synthesis of qualitative research – Zvyšování transparentnosti při vykazování syntézy kvalitativního výzkumu).3334
- COREQ – Consolidated criteria for reporting qualitative research (Konsolidovaná kritéria pro vykazování kvalitativního výzkumu) nabízí kontrolní seznam obsahující 32 položek/kritérií, které můžou výzkumným pracovníkům pomoci uvést důležité aspekty týkající se výzkumného týmu, metod studie, kontextu studie, zjištění, analýzy a interpretace. Je užitečný zejména pro kvalitativní výzkum, v němž byly provedeny rozhovory a/nebo ohniskové skupiny. (COREQ / Full Text)
- SRQR – Standards for Reporting Qualitative Research (Standardy pro vykazování kvalitativního výzkumu) jde o kontrolní seznam pokrývající širší škálu kvalitativního výzkumu. Nabízí standard reportování kvalitativního výzkumu, který vychází z přehledu různých pokynů. Jeho cílem je zlepšit transparentnost kvalitativního výzkumu a pomoci autorům při přípravě rukopisu. (SRQR / Full Text)
- ENTREQ – Enhancing transparency in reporting the synthesis of qualitative research (Zvýšení transparentnosti při podávání zpráv o syntéze kvalitativního výzkumu) pomáhá výzkumným pracovníkům uvádět syntézu zjištění z více kvalitativních studií. ENTREQ zahrnuje několik fází: vyhledávání a výběr kvalitativního výzkumu, hodnocení kvality a metody syntézy kvalitativních zjištění. (ENTREQ / Full Text)
Více informací o kódování, analýze a interpretaci dat lze nastudovat v publikacích Johny Saldana (2021)35, Vanover (2021)36, Skjott a Korsgaard, (2019)37. Podrobnější informace k interpretaci kvalitativních dat lze také nalézt v publikaci Joanne Neale (2020).38
Souhrn kapitoly
V kapitole jsme uvedli základní informace vymezující postavení kvalitativního výzkumu včetně jeho místa a role v získávání poznatků a důkazů nezbytných pro rozvoj teorie a praxe ošetřovatelství jako vědního oboru. Popsali jsme vybrané přístupy kvalitativního výzkumu a vybrané metody sběru a analýzy dat. Vzhledem k charakteru publikace nejsou jednotlivé pasáže rozpracovány vyčerpávajícím způsobem, proto v textu odkazujeme na další publikace a autory, kteří se zkoumanou problematikou zabývají podrobněji. V závěru kapitoly považujeme za užitečné upozornit na důležitost validity (platnosti) a reliability (spolehlivosti) kvalitativního výzkumu. Obě charakteristiky jsou klíčové pro generalizaci (zobecňování) výzkumných zjištění (a následnou tvorbu nových teorií) a současně zvyšují důvěryhodnost výzkumu. Validita udává, zda prezentovaná výzkumná zjištění skutečně vypovídají o zkoumaném fenoménu neboli zda výzkumník skutečně zkoumal to, co původně zamýšlel zkoumat. Reliabilita vypovídá o tom, zda je možné v případě opakování výzkumu dospět k totožným či obdobným výzkumným zjištěním. Ačkoli je kvalitativní výzkum specifický zejména v tom, že jeho opakování zpravidla není možné – podmínky i kontexty jsou jedinečné a proměňují se v čase. Z uvedeného důvodu kvalitativní výzkumníci věnují zvýšenou pozornost podrobnému popisu průběhu celého výzkumu. Nezbytné je především zdůvodnit výzkumnou otázku, vyčerpávajícím způsobem charakterizovat zkoumaný soubor, jasně a srozumitelně popsat postup sběru a analýzy dat, a interpretovat výzkumná zjištění vždy s oporou ve výzkumných datech a s přihlédnutím k limitacím vyplývajícím z kvalitativního charakteru výzkumu. V tabulce 4 shrnujeme konkrétní kroky nutné k realizaci kvalitativního výzkumu a popisujeme, jaké informace by měly být v závěrečné práci obsaženy.
Tabulka 4 Konkrétní kroky nutné k realizaci kvalitativního výzkumu
| Název fáze | Co je potřeba uvést v závěrečné práci |
| Úvod/příprava | Předběžné stanovení cílů a výzkumných otázek. Je třeba zvolit hlavní tematickou linii (někteří autoři hovoří o tom, že je třeba „uplést tenkou červenou nit“), která se bude prolínat celou výzkumnou zprávou, respektive závěrečnou prací. Nejprve je třeba srozumitelně vyložit: o čem výzkum bude (viz úvodní kapitoly), proč je v kontextu dané vědecké disciplíny významný, jaké nálezy budou představeny, případně jaké teorie budou rozvíjeny, a jak bude text strukturován. Je doporučováno držet se věcného tónu – nestavět do popředí osobní zaujetí autora, do popředí by mělo vystoupit téma samotné (Šeďová, Švaříček, 201339). |
| Přehled (rešerše literatury) | Provedení přehledu (rešerše) literatury týkající se zkoumaného fenoménu. Zdůvodnění relevance jednotlivých zdrojů. Tento krok je klíčovou součástí výzkumné práce, kdy výzkumník shromažďuje potřebné informace týkající se již proběhlých výzkumů v dané problematice. Díky patřičné rešerši může navázat na zjištění jiných výzkumníků a současně vytváří teoretickou základnu o zkoumaném fenoménu aj. (Mareš, 201340; Sing, 202141). Více viz kapitola o vyhledávání informací a PICO otázce. |
| Metodika | Zdůvodnění výběru konkrétního výzkumného nástroje a jeho popis. Popis výsledků pilotní studie včetně případných změn v navrhovaném výzkumném designu. Popis, jak dlouho trval zkušební rozhovor, nebo jak dlouho byl vyplňován jeden záznamový arch. Provedení předvýzkumu ověřuje, zda výzkumný nástroj přináší data potřebná pro zodpovězení výzkumných otázek aj. |
| Definování výzkumného souboru | Počet participantů musí být zvolen tak, aby bylo možné objasnit zkoumaný fenomén. Měla by být jasně zdůvodněna kritéria pro zařazení/vyřazení respondentů výzkumu. Důležité je zdůvodnit, proč si výzkumník zvolil konkrétní počet respondentů. Tzn., jak rozpoznal, že získaná data jsou dostatečná. Na rozdíl od kvantitativního výzkumu není nutné stanovit přesný počet potřebných participantů. Vždy se vychází z konkrétního výzkumného přístupu, kdy výzkumník ukončuje sběr dat poté, co byla data teoreticky saturována/nasycena (soubor byl vyčerpán, respektive významy ukryté ve výpovědích respondentů se opakují). To znamená, že výzkumník dostává opakovaně stejné informace o zkoumaném fenoménu a další výzkum neodhalí už jiná zjištění. Výzkumník rovněž musí definovat kritéria inkluze (tzn. vstupní kritéria pro zařazení) a exkluze (tzn. vstupní kritéria pro nezařazení), např. požadovaný věk, pohlaví, přidružené choroby u pacientů. V případě zaměření výzkumu na zdravotníky je např. zohledňováno profesní zařazení, délka praxe, typ vzdělání. |
| Přípravná fáze výzkumu | Popis způsobu a formy oslovení respondentů, jak s nimi byla navázána komunikace, popis způsobu získání souhlasu s výzkumem (od jednotlivců, zdravotnických zařízení, etických komisí aj. – obvykle se dává v kopii do přílohy práce). Dále je nutné definovat prostředí, ve kterém bude sběr dat probíhat (viz PICO otázka). V naturalistickém pojetí je upřednostňováno využívat tzv. domácího prostředí (přirozeného sociálního prostředí participanta), které může odhalit další významné prvky pro výzkum (např. návštěva participantů v jejich práci, kde můžeme sledovat celkový vzhled pracoviště, vybavení, včetně dostupnosti pomůcek aj.). Rovněž rutinní úkony mohou být v laboratorním nebo jiném prostředí prováděny odlišně než na klinickém pracovišti. Dalším příkladem může být návštěva participantů v jejich kancelářích nebo domovech, kde si může výzkumník všimnout různých osobních předmětů (fotografií, vzpomínkových předmětů aj.), které ho mohou navést k dalším otázkám přispívajícím k odkrytí zkoumaného fenoménu). |
| Sběr dat | Popis sběru dat, kde a jak sběr dat probíhal, jak dlouho trvalo provedení výzkumu (rozhovoru, pozorování, psaní aj.). Výzkumník může rovněž popsat podmínky utvořené pro sběr dat, atmosféru v průběhu sběru dat, subjektivní pocity z komunikace s participanty a postřehy, které je vhodné zapsat si co nejdříve po ukončení sběru dat (viz field notes uvedené v podkapitole pozorování). Data jsou většinou vyjádřena slovně a obvykle se zaznamenávají na diktafon, video (následně je nutný přepis/transkripce), anebo si výzkumník zapisuje poznámky do záznamového archu. |
| Analýza dat | Přesně se popisuje způsob zpracování dat (tzn. co se přesně dělo, např. s přepisy rozhovorů, jak probíhalo kódování dat – např. zda a jakým způsobem byly využity počítačové programy určené ke zpracování kvalitativních dat aj.). |
| Výsledky | V této fázi výzkumu se výzkumník zamýšlí nad získanými daty, výsledky jsou popsány a následně je možné je kategorizovat, schematizovat, hledat vztahy mezi různými oblastmi aj. Syntéza nově zjištěných poznatků přináší cenné informace o zkoumaném jevu. Popis jednotlivých výsledků práce. Jednotlivé kategorie, nebo zkoumané oblasti je vhodné pro ilustraci doplnit vhodně zvolenými úryvky z rozhovorů, psaných záznamů (uváděných v přímé citaci). Tyto výroky mohou zvýšit důvěryhodnost výzkumu. Po provedení popisu dat výzkumník prezentuje výsledky vztažené k výzkumným otázkám a cílům práce. Vhodné je získaná data a jejich kategorie vyjádřit graficky, tj. zobrazit ve schématech, obrázcích aj. |
| Diskuse | Výsledky svého výzkumu výzkumník diskutuje s teoretickými zdroji nebo s výsledky českých i zahraničních relevantních empirických studií týkajících se zkoumaného fenoménu. Současně zde upozorňuje na přínosy a úskalí jeho výzkumu, konkrétní výzkumné metody a poznání. Výzkumník se zde může vyjádřit k možným, jím navrhovaným opatřením vedoucím ke zlepšení/doplnění dalšího výzkumu. |
| Závěr | Jedná se o stručnou sumarizaci konkrétních zjištěných poznatků (ve vztahu ke splnění výzkumníkem stanovených cílů) s přemostěním k dalším možným budoucím výzkumům. |
Seznam literatury
↑ 1. Flick U. An Introduction to Qualitative Research. 5th ed. Los Angeles, CA: Sage; c2014.
↑ 2. Ritchie J, Lewis J, Nicholls CM, Ormston R. Qualitative Research Practice: A Guide for Social Science Students and Researchers. 2nd ed. Los Angeles, CA: SAGE Publications; c2014.
↑ 3. Stuckey HL. “The second step in data analysis: Coding qualitative research data.” Journal of Social Health and Diabetes. 2015;03(01):007-010. doi: 10.4103/2321-0656.140875
↑ 4. Francesca P, Weldon SM, Lomi A. Lost in translation: Collecting and coding data on social relations from audio-visual recordings. Social Networks. 2020;69:102–112. doi: 10.1016/j.socnet.2020.02.006
↑ 5. Woods D. Presentation in: Christina Silver, PhD. (2020, December 4). CAQDAS webinar 005 Transcription as an analytic act. [Video]. https://www.youtube.com/watch?v=7X-s1r4l0QQ. Accessed August 8, 2022.
↑ 6. Davidson C. Transcription: Imperatives for qualitative research. International Journal of Qualitative Methods. 2009;8(2):35–52. doi: https://doi.org/10.1177/160940690900800206.
↑ 7. Clark L, Birkhead AS, Fernandez C, Egger MJ. A transcription and translation protocol for sensitive cross-cultural team research. Qualitative Health Research. 2017:27(12)1751–1764. doi:10.1177/1049732317726761.
↑ 8. Woods D. Presentation in: Silver Ch. (2020, December 4). CAQDAS webinar 005 Transcription as an analytic act. [Video]. https://www.youtube.com/watch?v=7X-s1r4l0QQ.
↑ 9. Bailey J. First steps in qualitative data analysis: transcribing. Family Practice. 2008; 25(2): 127–131. doi:10.1093/fampra/cmn003.
↑ 10. Bucholtz M. The politics of transcription. Journal of Pragmatics. 2000;32(10):1439–1465. doi:10.1016/S0378-2166(99)00094-6.
↑ 11. Green J, Franquiz M, Dixon C. The myth of the objective transcript: Transcribing as a situated act. TESOL Quarterly. 1997;21(1):172–176.
↑ 12. Parameswaran UD, Ozawa-Kirk JL, Latendresse G. To live (code) or to not: A new method for coding in qualitative research. Qualitative Social Work. 2020;19(4):630–644. doi:10.1177/1473325019840394.
↑ 13. McMullin C. Transcription and Qualitative Methods: Implications for Third Sector Research. Voluntas. 2021;10:1–14. doi: 10.1007/s11266-021-00400-3.
↑ 14. Roberts C. Qualitative Data Analysis. Transcribing Spoken Discourse FDTL Data Project 2004. http://www.kcl.ac.uk/schools/sspp/education/research/projects/dataqual.html. Accessed Nov 4, 2007
↑ 15. Green J, Franquiz M, Dixon C. The myth of the objective transcript: transcribing as a situated act. TESOL Quarterly. 1997;31(172-176).
↑ 16. Greatbatch D, Heath C, Campion P, Luff P. How do desk-top computers affect the doctor-patient interaction?. Fam Pract. 1995;12(32-36).
↑ 17. Have P. Transcribing Talk in Interaction. Doing Conversation Analysis. A Practical Guide. London SAGE Publication; c1999.
↑ 18. Stuckey HL. The first step in Data Analysis: Transcribing and managing qualitative research data. J Soc Health Diabetes. 2014;2(6-8). doi: 10.4103/2321-0656.120254.
↑ 19. Qualitative Data Analysis: Qualitative Data Analysis Strategies. 2020 University of Illinois Board of Trustees. https://guides.library.illinois.edu/qualitative. Accessed Oct 5, 2022.
↑ 20. Dhakal K. NVIVO. Journal of the Medical Library Association. 2022;110(2):270-272. doi:10.5195/jmla.2022.1271.
↑ 21. Farley J, Duppong Hurley K, Aitken A. "Monitoring implementation in program evaluation with direct audio coding" 2020. Publications of the University of Nebraska Public Policy Center. 179. https://digitalcommons.unl.edu/publicpolicypublications/179 Accessed October 5, 2022.
↑ 22. Deterding NM, Waters MC. Flexible coding of in-depth interviews: A twenty-first-century approach. Sociological Methods & Research. 2021:50(2):708–739. doi:10.1177/0049124118799377
↑ 23. Ryan GW, Bernard HR. Techniques to identify themes. Field Methods. 2003;15(1):85–109. doi:10.1177/1525822X02239569.
↑ 24. Lewins A, Silver C. Using software in qualitative research: a step-by-step guide. 2nd ed. London: Thousand Oaks, c2014.
↑ 25. Cope DG. Computer-Assisted Qualitative Data Analysis Software. Oncology Nursing Forum. 2014;41(3):322-323. doi:10.1188/14.ONF.322-323.
↑ 26. Lennon RP, Fraleigh R, Van Scoy LJ et al. Developing and testing an automated qualitative assistant (AQUA) to support qualitative analysis. Family Medicine and Community Health. 2021;9:e001287. doi:10.1136/fmch-2021-001287.
↑ 27. Braun V, Clarke V. Successful qualitative research: a practical guide for beginners. London: Sage; c2013.
↑ 28. Neale J, Hunt G, Lankenau S et al. Addiction journal is committed to publishing qualitative research. Addiction. 2013;108:447–449. doi:10.1111/add.12051.
↑ 29. Green J, Thorogood N. Qualitative methods for health research. London: Sage; c2004.
↑ 30. Bazeley P. Qualitative data analysis: practical strategies. London: Sage; c2013.
↑ 31. Neale J. Iterative categorization (IC): a systematic technique for analysing qualitative data. Addiction. 2016;111(6):1096-106. doi:10.1111/add.13314.
↑ 32. Korstjens I, Moser M. Series: practical guidance to qualitative research. Part 4: trustworthiness and publishing. Eur J Gen Pract. 2018;24:120–124. doi: 10.1080/13814788.2017.1375092.
↑ 33. Tong A, Sainsbury P, Craig J. Consolidated criteria for reporting qualitative research (COREQ): a 32-item checklist for interviews and focus groups. International Journal for Quality in Health Care. 2007;19(6):349–357. doi:10.1093/intqhc/mzm042.
↑ 34. Tenny S, Brannan GD, Brannan JM, Sharts-Hopko NC. Qualitative Study. 2021. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing. PMID: 29262162.
↑ 35. Saldaña J. The coding manual for qualitative researchers. 4th edition. Los Angeles: SAGE, c2021.
↑ 36. Vanover Ch, Mihas P, Saldaña J ed. Analyzing and interpreting qualitative research: after the interview. Thousand Oaks, California: Sage, c2021.
↑ 37. Skjott Linneberg M, Korsgaard S. Coding qualitative data: a synthesis guiding the novice. Qualitative Research Journal. 2019;19(3):259-270. doi: https://doi.org/10.1108/QRJ-12-2018-0012.
↑ 38. Neale J. Iterative categorisation (IC) (part 2): interpreting qualitative data. Addiction. 2020;116(3):668-676. doi:10.1111/add.15259.
↑ 39. Šeďová K, Švaříček R. Jak psát kvalitativně orientované výzkumné studie: kvalita v kvalitativním výzkumu. Pedagog orientace. 2013;23(4):478-510. doi: https://doi.org/10.5817/PedOr2013-4-478.
↑ 40. Mareš J. Přehledové studie: jejich typologie, funkce a způsob vytváření. Pedagog orientace. 2013;23(4):427-454. doi: https://doi.org/10.5817/PedOr2013-4-427.
↑ 41. Singh S. Why does it take so long to publish your research? J Conserv Dent. 2021;24(6):529. doi:10.4103/jcd.jcd_92_22.