15.2 Transformace tabulek do tidy formátu
Ne všechny dostupné datasety jsou organizované v tidy formátu. Součástí tidyverse je balíček tidyr, který obsahuje nástroje pro transformaci tabulek do tidy formátu.
Základními funkcemi v balíku tidyr, které zvládnou většinu obvyklých problémů, jsou pivot_wider() a pivot_longer().
15.2.0.1 Poznámka 1
Funkce pivot_wider() a pivot_longer() přišly do tidyr od verze 1.0.0 (podzim 2019). Ve streších verzích balíku jejich funkci plnily funkce gather() a spread(), které byly vlastně speciálním případem obecnějších pivot_* funkcí. Funkce gather() a spread() byly v balíku podrženy pouze pro zachování zpětné kompatibility.
15.2.0.2 Poznámka 2
Existují balíky, které mají podobné funkcionality jako tidyr. Zejména jde o reshape a reshape2. Oba balíky jsou v podstatě starými evolučními verzemi balíku tidyr. Zejména reshape2 je stále v závislostech mnoha dalších balíků. tidyr je však obecně pokročilejší (co do rychlosti, elegance i rozsahu funkcí).
15.2.1 Transformace mnoha sloupců do jednoho s funkcí pivot_longer()
Mnoho datasetů obsahuje sloupce, jejichž jména nejsou samostatné proměnné, ale ve skutečnosti jde o hodnoty jedné proměnné. Jako příklad můžeme použít tabulku table4a z balíku tidyr, která zachycuje počet pozorovaných případů v několika letech a zemích:
print(table4a)## # A tibble: 3 × 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766V tomto formátu obsahuje jeden řádek hned dvě pozorování (dvě pozorování z jedné země) a dva sloupce obsahují stejnou proměnnou (počet případů). Pro transformaci takové tabulky do tidy formátu slouží funkce pivot_longer().
pivot_longer() skládá hodnoty z vybraných sloupců do nově vytvořeného sloupce. Jména vybraných sloupců vytvoří další dodatečný sloupec. pivot_longer() tak nahradí vybrané sloupce dvěma novými:
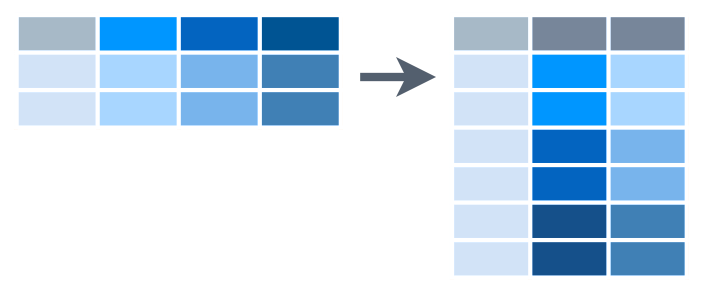 Výsledná tabulka je proto “delší.” Pro snadnější zapamatování se se proto funkce jmenuje
Výsledná tabulka je proto “delší.” Pro snadnější zapamatování se se proto funkce jmenuje pivot_longer().
Ukázkou praktické aplikace pivot_longer() může být transformace tabulky table4a:
table4a %>%
pivot_longer(-country)## # A tibble: 6 × 3
## country name value
## <chr> <chr> <int>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766Funkce pivot_longer() provedla transformaci ilustrovanou následujícím obrázkem:

Fungování gather() (Wickham, 2016)
Původní tabulka měla 3 řádky. Nyní jich má 6. Každý původní řádek se rozpadl na dva nové.
Funkce pivot_longer() má následující syntax a parametry (více viz ?pivot_longer):
pivot_longer(data, cols,
names_to = "name",
names_prefix = NULL,
names_sep = NULL,
names_pattern = NULL,
names_ptypes = list(),
names_repair = "check_unique",
values_to = "value",
values_drop_na = FALSE,
values_ptypes = list()
)Základní parametry jsou následující:
- data…vstupní tabulka (data frame), která má projít transformací,
- cols…identifikace sloupců, které mají být transformovány,
- names_to…jméno sloupce, který ve výsledné tabulce bude obsahovat jména transformovaných sloupců,
- values_to…jméno sloupce, který v transformované tabulce bude obsahovat hodnoty z původních sloupců.
Nyní se vraťme k úvodnímu příkladu:
table4a %>%
pivot_longer(-country)Vstupem do funkce pivot_longer() byla tabulka table4a. Parametr cols byl s využitím pomocné funkce - nastaven na hodnotu -country. To znamená, že transformovány byly všechny sloupce až na country. Nově vytvořená tabulka má tři sloupce: netransformovaný sloupec country a nově vytvořené sloupce name a value. Jména těchto sloupců jsou dána defaultním nastavením funkce pivot_longer().
Nyní se podíváme na složitější případ. Pro ilustraci upravenou tabulku table4a, které přidáme sloupec obsahující ID:
## # A tibble: 3 × 4
## country `1999` `2000` id
## * <chr> <int> <int> <int>
## 1 Afghanistan 745 2666 1
## 2 Brazil 37737 80488 2
## 3 China 212258 213766 3Tabulku chceme transformovat tak, aby se sloupce s hodnotami (1999 a 2000) transformovaly do sloupců year a value. Je jasné, že chceme sáhnout po pivot_longer():
table4a %>%
# Tento řádek vytvoří nový sloupec s číslem řádku
mutate(id = row_number()) %>%
pivot_longer(-country, -id)Toto nebude fungovat, protože parametr cols má jenom jednu pozici – v jejím rámci musíme identifikovat všechny sloupce, které se mají transformovat.
# Použití negativní identifikace
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(-c(country,id))## # A tibble: 6 × 4
## country id name value
## <chr> <int> <chr> <int>
## 1 Afghanistan 1 1999 745
## 2 Afghanistan 1 2000 2666
## 3 Brazil 2 1999 37737
## 4 Brazil 2 2000 80488
## 5 China 3 1999 212258
## 6 China 3 2000 213766V tomto případě byl do jednomístného slotu vložen vektor vytvořený funkcí c(). Všiměte si, že i v něm jsou jména sloupců uvedena bez úvozovek.
Hint: V reálném nasazení je vždy užitečné zvážit použití negtivní identifikace sloupců. Představte si například situaci, kdy Vašim zdrojeme je databáze, do které každý rok přibude další sloupec. Pozitivní identifikace sloupců by způsobila, že Vaše skripty by po prvním updatu přestaly správně fungovat. Negativní identifikace tímto problémem netrpí.
Výše uvedená možnost není jediná možná. Následující příklady by vedly ke stejným výsledkům:
# Použití pozitivní identifikace
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(c(`1999`,`2000`))
# Použití pozitivní identifikace a speciální funkce `:`
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(`1999`:`2000`)
# Použití select helpers
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(matches("\\d{4}"))15.2.2 Transformace dvojice sloupců do mnoha sloupců s funkcí pivot_wider()
Funkce pivot_wider() je inverzní k funkci pivot_longer(). Použijeme ji v případě, že sloupec ve skutečnosti neobsahuje hodnoty jedné proměnné, ale hodnoty mnoha proměnných. Funkce pivot_wider() transforumje dvojici sloupců do mnoha nových sloupců. Hodnoty prvního z původních sloupců obsahují určení proměnné a v druhém sloupci jsou uloženy jejich hodnoty.
Příkladem takového datasetu může být tabulka table2 z balíku tidyr:
## # A tibble: 12 × 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583Pozorování je opět identifikováno hodnotami ve sloupcích country a year. Nicméně jedno pozorování je roztaženo do dvou řádků a hodnoty pro počet případů (count) a velikost populace (population) jsou obsaženy v jednom sloupci count.
Pro převední takové tabulky do tidy fromátu je potřeba provést operaci popsanou následujícím schématem:
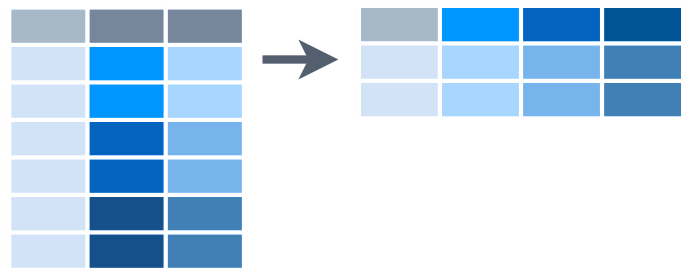
Fungování pivot_wider() (RStudio, 2015)
Funkce pivot_wider() použije hodnoty z prvního sloupce (key) jako jména nově vytvořených sloupců. Nově vytvořené buňky jsou potom vyplněny hodnotami z druhého sloupce (value) v původní tabulce:
table2 %>%
pivot_wider(names_from = type, values_from = count)## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Funkce pivot_wider() provedla transformaci ilustrovanou následujícím obrázkem:
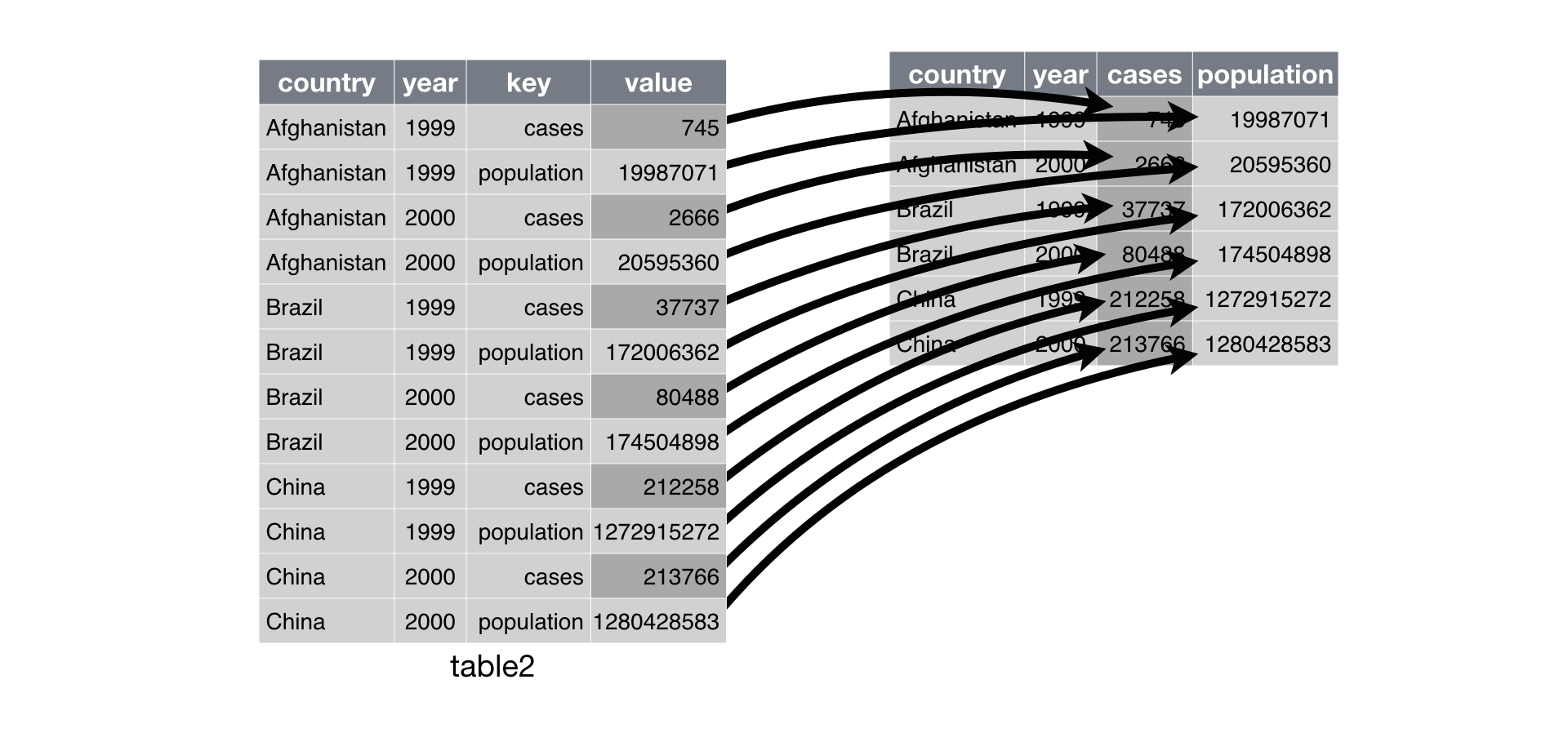
Fungování pivot_wider() (Wickham, 2016)
Funkce pivot_wider() má následující syntax a parametry (více viz ?pivot_wider):
pivot_wider(data,
id_cols = NULL,
names_from = name,
names_prefix = "",
names_sep = "_",
names_repair = "check_unique",
values_from = value,
values_fill = NULL,
values_fn = NULL
)Klíčové parametry jsou následující:
data…vstupní tabulka (data frame), která má projít transformacíid_cols…sloupce, které identifikují jedno pozorování. V defaultní nastevením (tedyNULL) se k tomuto účelu použijí všechny sloupce, které neprocházejí transformací.names_from…sloupec (nebo sloupce), ze kterého se mají vytvořit jména nově vytvořených sloupců,values_from…sloupec (nebo sloupce), ze kterých se mají vzít hodnoty pro naplnění nově vytvořených sloupců.
Jak to funguje, pokud je parametr names_from delší než 1?
Předpokládejme, že chceme vytvořit tabulku, ve které budou sloupce definovány kombinací roku a proměnné:
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count)## # A tibble: 3 × 5
## country cases_1999 population_1999 cases_2000 population_2000
## <chr> <int> <int> <int> <int>
## 1 Afghanistan 745 19987071 2666 20595360
## 2 Brazil 37737 172006362 80488 174504898
## 3 China 212258 1272915272 213766 1280428583Jméno sloupců je teď vytvořené z kombinace type a year. Výslednou podobu jmen upravuje parametr names_sep z pivot_wider().
15.2.3 Praktické procvičení pivot_longer() a pivot_wider() I
Uvažujme tabulku vytvořenou v předchozím případě. Jak z ní vytvoříme tidy dataset?
Tabulka byla vytvořena s pivot_wider(). V prvním kroku tedy sáhneme tedy po inverzní funkci pivot_longer().
V tomto příkladě využijeme řadu zatím nediskutovaných parametrů pivot_longer():
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count) %>%
pivot_longer(-country,
names_to = c("type","year"),
names_sep = "_",
names_transform = list(year = as.integer),
names_ptypes = list(type = character()),
values_to = "count"
)## # A tibble: 12 × 4
## country type year count
## <chr> <chr> <int> <int>
## 1 Afghanistan cases 1999 745
## 2 Afghanistan population 1999 19987071
## 3 Afghanistan cases 2000 2666
## 4 Afghanistan population 2000 20595360
## 5 Brazil cases 1999 37737
## 6 Brazil population 1999 172006362
## 7 Brazil cases 2000 80488
## 8 Brazil population 2000 174504898
## 9 China cases 1999 212258
## 10 China population 1999 1272915272
## 11 China cases 2000 213766
## 12 China population 2000 1280428583Co se v nově použitých parametrech stalo? Parametr names_to je nyní délky 2. To znamená, že jména transformovaných sloupců se rozpadnou do dvou sloupců se zadanými jmény. Jak se má tento rozpad provést určuje parametr names_sep (u složitějších případů names_pattern). V současném nastavení říká, že znaky před _ mají být přeneseny do sloupce type a znaky za _ do sloupce year. Bylo by také vhodné, aby hodnoty ve sloupci type byly character a ve sloupci year integer. Tato konverze se nastavuje parametrem names_ptypes. Ten obsahuje pojmenovaný list. Jména odpovídají jménům nově vytvořených sloupců ke ketrým je přiřazen prázdný vektor požadovaného datového typu.
Tato transformace zvrátila účinky pivot_wider(). Nicméně data stále nejsou tidy. Potřebujeme mít dva nové sloupce cases a population s hodnotami ze sloupce count. A job for pivot_wider():
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count) %>%
pivot_longer(-country,
names_to = c("type","year"),
names_sep = "_",
names_transform = list(year = as.integer),
names_ptypes = list(type = character()),
values_to = "count"
) %>%
pivot_wider(
id_cols = c(country,year), # V tomto případě ekvivalenttní k NULL
names_from = type,
values_from = count
)## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583…and here we go.
Výsledek odpovídá formátu tidy data.